 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
MoCha:End-to-End Video Character Replacement without Structural Guidance
Jan 14, 2026Controllable video character replacement with a user-provided identity remains a challenging problem due to the lack of paired video data. Prior works have predominantly relied on a reconstruction-based paradigm that requires per-frame segmentation masks and explicit structural guidance (e.g., skeleton, depth). This reliance, however, severely limits their generalizability in complex scenarios involving occlusions, character-object interactions, unusual poses, or challenging illumination, often leading to visual artifacts and temporal inconsistencies. In this paper, we propose MoCha, a pioneering framework that bypasses these limitations by requiring only a single arbitrary frame mask. To effectively adapt the multi-modal input condition and enhance facial identity, we introduce a condition-aware RoPE and employ an RL-based post-training stage. Furthermore, to overcome the scarcity of qualified paired-training data, we propose a comprehensive data construction pipeline. Specifically, we design three specialized datasets: a high-fidelity rendered dataset built with Unreal Engine 5 (UE5), an expression-driven dataset synthesized by current portrait animation techniques, and an augmented dataset derived from existing video-mask pairs. Extensive experiments demonstrate that our method substantially outperforms existing state-of-the-art approaches. We will release the code to facilitate further research. Please refer to our project page for more details: orange-3dv-team.github.io/MoCha
End-to-End Video Character Replacement without Structural Guidance
Jan 13, 2026Controllable video character replacement with a user-provided identity remains a challenging problem due to the lack of paired video data. Prior works have predominantly relied on a reconstruction-based paradigm that requires per-frame segmentation masks and explicit structural guidance (e.g., skeleton, depth). This reliance, however, severely limits their generalizability in complex scenarios involving occlusions, character-object interactions, unusual poses, or challenging illumination, often leading to visual artifacts and temporal inconsistencies. In this paper, we propose MoCha, a pioneering framework that bypasses these limitations by requiring only a single arbitrary frame mask. To effectively adapt the multi-modal input condition and enhance facial identity, we introduce a condition-aware RoPE and employ an RL-based post-training stage. Furthermore, to overcome the scarcity of qualified paired-training data, we propose a comprehensive data construction pipeline. Specifically, we design three specialized datasets: a high-fidelity rendered dataset built with Unreal Engine 5 (UE5), an expression-driven dataset synthesized by current portrait animation techniques, and an augmented dataset derived from existing video-mask pairs. Extensive experiments demonstrate that our method substantially outperforms existing state-of-the-art approaches. We will release the code to facilitate further research. Please refer to our project page for more details: orange-3dv-team.github.io/MoCha
Addressing Domain Shift via Imbalance-Aware Domain Adaptation in Embryo Development Assessment
Jan 09, 2025Deep learning models in medical imaging face dual challenges: domain shift, where models perform poorly when deployed in settings different from their training environment, and class imbalance, where certain disease conditions are naturally underrepresented. We present Imbalance-Aware Domain Adaptation (IADA), a novel framework that simultaneously tackles both challenges through three key components: (1) adaptive feature learning with class-specific attention mechanisms, (2) balanced domain alignment with dynamic weighting, and (3) adaptive threshold optimization. Our theoretical analysis establishes convergence guarantees and complexity bounds. Through extensive experiments on embryo development assessment across four imaging modalities, IADA demonstrates significant improvements over existing methods, achieving up to 25.19\% higher accuracy while maintaining balanced performance across classes. In challenging scenarios with low-quality imaging systems, IADA shows robust generalization with AUC improvements of up to 12.56\%. These results demonstrate IADA's potential for developing reliable and equitable medical imaging systems for diverse clinical settings. The code is made public available at \url{https://github.com/yinghemedical/imbalance-aware_domain_adaptation}
Efficient optimization-based trajectory planning
Dec 29, 2023



This study proposes a unified optimization-based planning framework that addresses the precise and efficient navigation of a controlled object within a constrained region, while contending with obstacles. We focus on handling two collision avoidance problems, i.e., the object not colliding with obstacles and not colliding with boundaries of the constrained region. The object or obstacle is denoted as a union of convex polytopes and ellipsoids, and the constrained region is denoted as an intersection of such convex sets. Using these representations, collision avoidance can be approached by formulating explicit constraints that separate two convex sets, or ensure that a convex set is contained in another convex set, referred to as separating constraints and containing constraints, respectively. We propose to use the hyperplane separation theorem to formulate differentiable separating constraints, and utilize the S-procedure and geometrical methods to formulate smooth containing constraints. We state that compared to the state of the art, the proposed formulations allow a considerable reduction in nonlinear program size and geometry-based initialization in auxiliary variables used to formulate collision avoidance constraints. Finally, the efficacy of the proposed unified planning framework is evaluated in two contexts, autonomous parking in tractor-trailer vehicles and overtaking on curved lanes. The results in both cases exhibit an improved computational performance compared to existing methods.
Efficient collision avoidance for autonomous vehicles in polygonal domains
Aug 17, 2023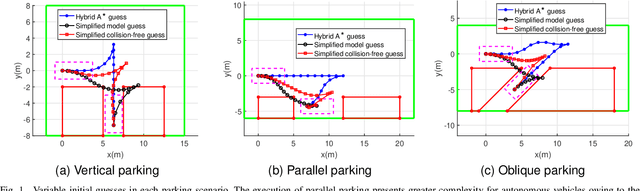
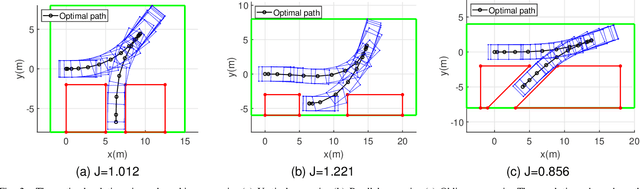
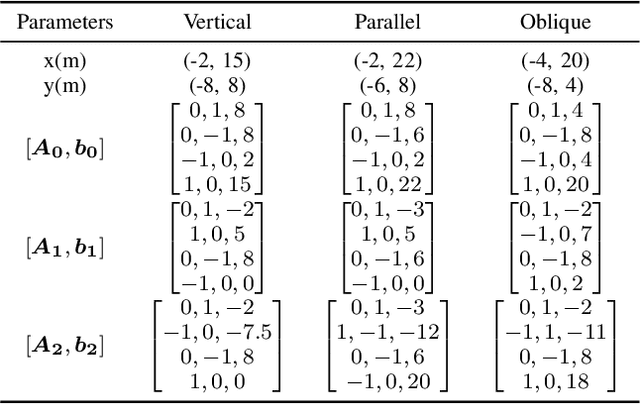
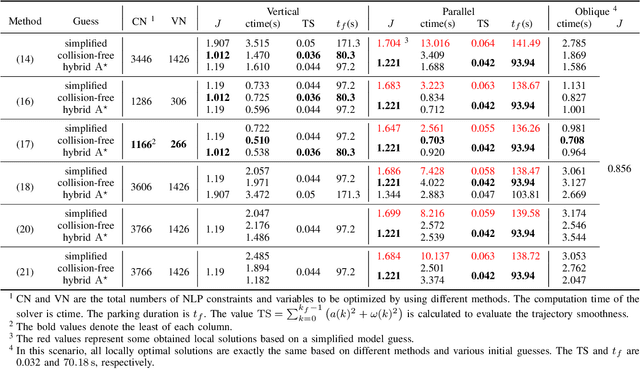
This research focuses on trajectory planning problems for autonomous vehicles utilizing numerical optimal control techniques. The study reformulates the constrained optimization problem into a nonlinear programming problem, incorporating explicit collision avoidance constraints. We present three novel, exact formulations to describe collision constraints. The first formulation is derived from a proposition concerning the separation of a point and a convex set. We prove the separating proposition through De Morgan's laws. Then, leveraging the hyperplane separation theorem we propose two efficient reformulations. Compared with the existing dual formulations and the first formulation, they significantly reduce the number of auxiliary variables to be optimized and inequality constraints within the nonlinear programming problem. Finally, the efficacy of the proposed formulations is demonstrated in the context of typical autonomous parking scenarios compared with state of the art. For generality, we design three initial guesses to assess the computational effort required for convergence to solutions when using the different collision formulations. The results illustrate that the scheme employing De Morgan's laws performs equally well with those utilizing dual formulations, while the other two schemes based on hyperplane separation theorem exhibit the added benefit of requiring lower computational resources.
A Cross-Residual Learning for Image Recognition
Nov 22, 2022ResNets and its variants play an important role in various fields of image recognition. This paper gives another variant of ResNets, a kind of cross-residual learning networks called C-ResNets, which has less computation and parameters than ResNets. C-ResNets increases the information interaction between modules by densifying jumpers and enriches the role of jumpers. In addition, some meticulous designs on jumpers and channels counts can further reduce the resource consumption of C-ResNets and increase its classification performance. In order to test the effectiveness of C-ResNets, we use the same hyperparameter settings as fine-tuned ResNets in the experiments. We test our C-ResNets on datasets MNIST, FashionMnist, CIFAR-10, CIFAR-100, CALTECH-101 and SVHN. Compared with fine-tuned ResNets, C-ResNets not only maintains the classification performance, but also enormously reduces the amount of calculations and parameters which greatly save the utilization rate of GPUs and GPU memory resources. Therefore, our C-ResNets is competitive and viable alternatives to ResNets in various scenarios. Code is available at https://github.com/liangjunhello/C-ResNet
Hard Example Guided Hashing for Image Retrieval
Dec 27, 2021

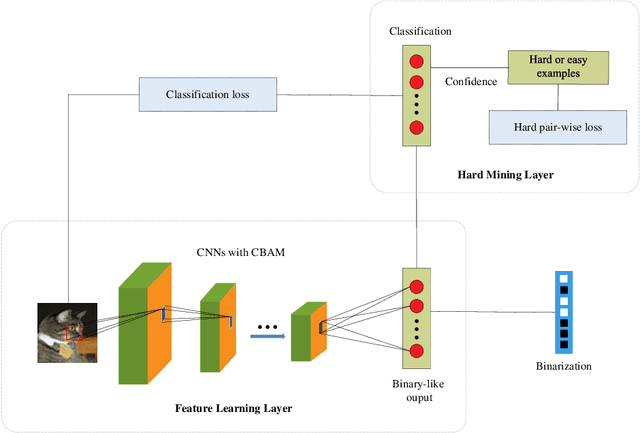

Compared with the traditional hashing methods, deep hashing methods generate hash codes with rich semantic information and greatly improves the performances in the image retrieval field. However, it is unsatisfied for current deep hashing methods to predict the similarity of hard examples. It exists two main factors affecting the ability of learning hard examples, which are weak key features extraction and the shortage of hard examples. In this paper, we give a novel end-to-end model to extract the key feature from hard examples and obtain hash code with the accurate semantic information. In addition, we redesign a hard pair-wise loss function to assess the hard degree and update penalty weights of examples. It effectively alleviates the shortage problem in hard examples. Experimental results on CIFAR-10 and NUS-WIDE demonstrate that our model outperformances the mainstream hashing-based image retrieval methods.
Dual Semantic Fusion Network for Video Object Detection
Sep 16, 2020
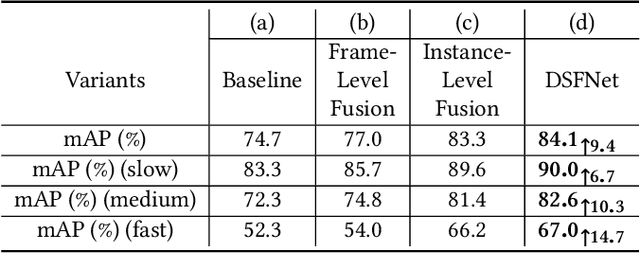
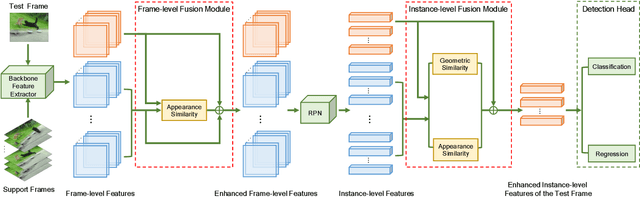
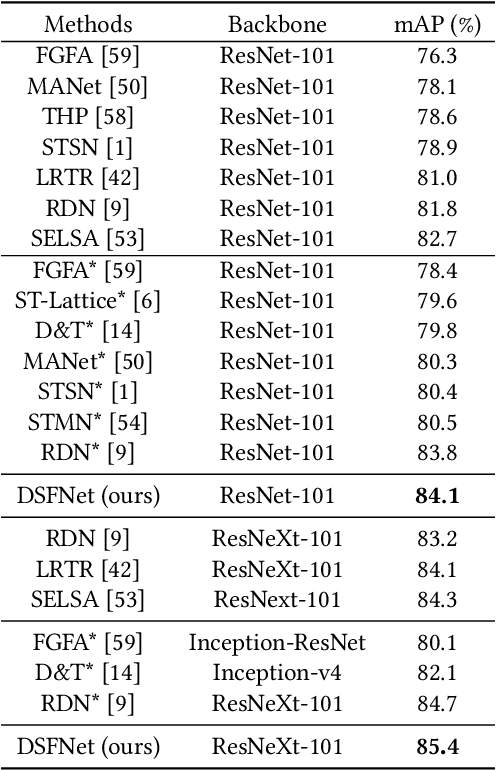
Video object detection is a tough task due to the deteriorated quality of video sequences captured under complex environments. Currently, this area is dominated by a series of feature enhancement based methods, which distill beneficial semantic information from multiple frames and generate enhanced features through fusing the distilled information. However, the distillation and fusion operations are usually performed at either frame level or instance level with external guidance using additional information, such as optical flow and feature memory. In this work, we propose a dual semantic fusion network (abbreviated as DSFNet) to fully exploit both frame-level and instance-level semantics in a unified fusion framework without external guidance. Moreover, we introduce a geometric similarity measure into the fusion process to alleviate the influence of information distortion caused by noise. As a result, the proposed DSFNet can generate more robust features through the multi-granularity fusion and avoid being affected by the instability of external guidance. To evaluate the proposed DSFNet, we conduct extensive experiments on the ImageNet VID dataset. Notably, the proposed dual semantic fusion network achieves, to the best of our knowledge, the best performance of 84.1\% mAP among the current state-of-the-art video object detectors with ResNet-101 and 85.4\% mAP with ResNeXt-101 without using any post-processing steps.
* 9 pages,6 figures
Fusion of Multispectral Data Through Illumination-aware Deep Neural Networks for Pedestrian Detection
Feb 27, 2018

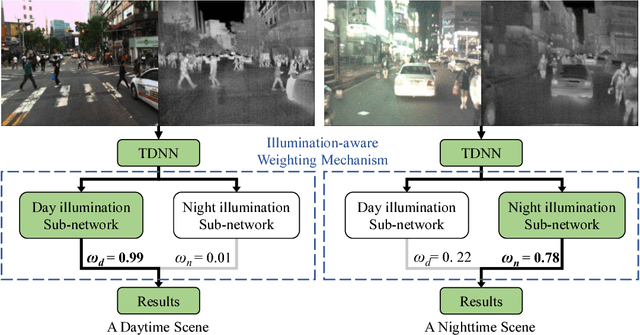
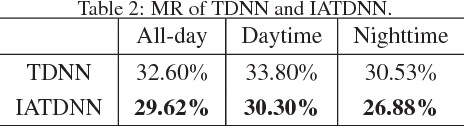
Multispectral pedestrian detection has received extensive attention in recent years as a promising solution to facilitate robust human target detection for around-the-clock applications (e.g. security surveillance and autonomous driving). In this paper, we demonstrate illumination information encoded in multispectral images can be utilized to significantly boost performance of pedestrian detection. A novel illumination-aware weighting mechanism is present to accurately depict illumination condition of a scene. Such illumination information is incorporated into two-stream deep convolutional neural networks to learn multispectral human-related features under different illumination conditions (daytime and nighttime). Moreover, we utilized illumination information together with multispectral data to generate more accurate semantic segmentation which are used to boost pedestrian detection accuracy. Putting all of the pieces together, we present a powerful framework for multispectral pedestrian detection based on multi-task learning of illumination-aware pedestrian detection and semantic segmentation. Our proposed method is trained end-to-end using a well-designed multi-task loss function and outperforms state-of-the-art approaches on KAIST multispectral pedestrian dataset.