 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEAR: Pixel-aligned Expressive humAn mesh Recovery
Jan 30, 2026Reconstructing detailed 3D human meshes from a single in-the-wild image remains a fundamental challenge in computer vision. Existing SMPLX-based methods often suffer from slow inference, produce only coarse body poses, and exhibit misalignments or unnatural artifacts in fine-grained regions such as the face and hands. These issues make current approaches difficult to apply to downstream tasks. To address these challenges, we propose PEAR-a fast and robust framework for pixel-aligned expressive human mesh recovery. PEAR explicitly tackles three major limitations of existing methods: slow inference, inaccurate localization of fine-grained human pose details, and insufficient facial expression capture. Specifically, to enable real-time SMPLX parameter inference, we depart from prior designs that rely on high resolution inputs or multi-branch architectures. Instead, we adopt a clean and unified ViT-based model capable of recovering coarse 3D human geometry. To compensate for the loss of fine-grained details caused by this simplified architecture, we introduce pixel-level supervision to optimize the geometry, significantly improving the reconstruction accuracy of fine-grained human details. To make this approach practical, we further propose a modular data annotation strategy that enriches the training data and enhances the robustness of the model. Overall, PEAR is a preprocessing-free framework that can simultaneously infer EHM-s (SMPLX and scaled-FLAME) parameters at over 100 FPS. Extensive experiments on multiple benchmark datasets demonstrate that our method achieves substantial improvements in pose estimation accuracy compared to previous SMPLX-based approaches. Project page: https://wujh2001.github.io/PEAR
MANGO:Natural Multi-speaker 3D Talking Head Generation via 2D-Lifted Enhancement
Jan 05, 2026Current audio-driven 3D head generation methods mainly focus on single-speaker scenarios, lacking natural, bidirectional listen-and-speak interaction. Achieving seamless conversational behavior, where speaking and listening states transition fluidly remains a key challenge. Existing 3D conversational avatar approaches rely on error-prone pseudo-3D labels that fail to capture fine-grained facial dynamics. To address these limitations, we introduce a novel two-stage framework MANGO, which leveraging pure image-level supervision by alternately training to mitigate the noise introduced by pseudo-3D labels, thereby achieving better alignment with real-world conversational behaviors. Specifically, in the first stage, a diffusion-based transformer with a dual-audio interaction module models natural 3D motion from multi-speaker audio. In the second stage, we use a fast 3D Gaussian Renderer to generate high-fidelity images and provide 2D-level photometric supervision for the 3D motions through alternate training. Additionally, we introduce MANGO-Dialog, a high-quality dataset with over 50 hours of aligned 2D-3D conversational data across 500+ identities. Extensive experiments demonstrate that our method achieves exceptional accuracy and realism in modeling two-person 3D dialogue motion, significantly advancing the fidelity and controllability of audio-driven talking heads.
LEMAS: Large A 150K-Hour Large-scale Extensible Multilingual Audio Suite with Generative Speech Models
Jan 04, 2026We present the LEMAS-Dataset, which, to our knowledge, is currently the largest open-source multilingual speech corpus with word-level timestamps. Covering over 150,000 hours across 10 major languages, LEMAS-Dataset is constructed via a efficient data processing pipeline that ensures high-quality data and annotations. To validate the effectiveness of LEMAS-Dataset across diverse generative paradigms, we train two benchmark models with distinct architectures and task specializations on this dataset. LEMAS-TTS, built upon a non-autoregressive flow-matching framework, leverages the dataset's massive scale and linguistic diversity to achieve robust zero-shot multilingual synthesis. Our proposed accent-adversarial training and CTC loss mitigate cross-lingual accent issues, enhancing synthesis stability. Complementarily, LEMAS-Edit employs an autoregressive decoder-only architecture that formulates speech editing as a masked token infilling task. By exploiting precise word-level alignments to construct training masks and adopting adaptive decoding strategies, it achieves seamless, smooth-boundary speech editing with natural transitions. Experimental results demonstrate that models trained on LEMAS-Dataset deliver high-quality synthesis and editing performance, confirming the dataset's quality. We envision that this richly timestamp-annotated, fine-grained multilingual corpus will drive future advances in prompt-based speech generation systems.
MelCap: A Unified Single-Codebook Neural Codec for High-Fidelity Audio Compression
Oct 02, 2025Neural audio codecs have recently emerged as powerful tools for high-quality and low-bitrate audio compression, leveraging deep generative models to learn latent representations of audio signals. However, existing approaches either rely on a single quantizer that only processes speech domain, or on multiple quantizers that are not well suited for downstream tasks. To address this issue, we propose MelCap, a unified "one-codebook-for-all" neural codec that effectively handles speech, music, and general sound. By decomposing audio reconstruction into two stages, our method preserves more acoustic details than previous single-codebook approaches, while achieving performance comparable to mainstream multi-codebook methods. In the first stage, audio is transformed into mel-spectrograms, which are compressed and quantized into compact single tokens using a 2D tokenizer. A perceptual loss is further applied to mitigate the over-smoothing artifacts observed in spectrogram reconstruction. In the second stage, a Vocoder recovers waveforms from the mel discrete tokens in a single forward pass, enabling real-time decoding. Both objective and subjective evaluations demonstrate that MelCap achieves quality on comparable to state-of-the-art multi-codebook codecs, while retaining the computational simplicity of a single-codebook design, thereby providing an effective representation for downstream tasks.
CanonSwap: High-Fidelity and Consistent Video Face Swapping via Canonical Space Modulation
Jul 03, 2025Video face swapping aims to address two primary challenges: effectively transferring the source identity to the target video and accurately preserving the dynamic attributes of the target face, such as head poses, facial expressions, lip-sync, \etc. Existing methods mainly focus on achieving high-quality identity transfer but often fall short in maintaining the dynamic attributes of the target face, leading to inconsistent results. We attribute this issue to the inherent coupling of facial appearance and motion in videos. To address this, we propose CanonSwap, a novel video face-swapping framework that decouples motion information from appearance information. Specifically, CanonSwap first eliminates motion-related information, enabling identity modification within a unified canonical space. Subsequently, the swapped feature is reintegrated into the original video space, ensuring the preservation of the target face's dynamic attributes. To further achieve precise identity transfer with minimal artifacts and enhanced realism, we design a Partial Identity Modulation module that adaptively integrates source identity features using a spatial mask to restrict modifications to facial regions. Additionally, we introduce several fine-grained synchronization metrics to comprehensively evaluate the performance of video face swapping methods. Extensive experiments demonstrate that our method significantly outperforms existing approaches in terms of visual quality, temporal consistency, and identity preservation. Our project page are publicly available at https://luoxyhappy.github.io/CanonSwap/.
GUAVA: Generalizable Upper Body 3D Gaussian Avatar
May 06, 2025Reconstructing a high-quality, animatable 3D human avatar with expressive facial and hand motions from a single image has gained significant attention due to its broad application potential. 3D human avatar reconstruction typically requires multi-view or monocular videos and training on individual IDs, which is both complex and time-consuming. Furthermore, limited by SMPLX's expressiveness, these methods often focus on body motion but struggle with facial expressions. To address these challenges, we first introduce an expressive human model (EHM) to enhance facial expression capabilities and develop an accurate tracking method. Based on this template model, we propose GUAVA, the first framework for fast animatable upper-body 3D Gaussian avatar reconstruction. We leverage inverse texture mapping and projection sampling techniques to infer Ubody (upper-body) Gaussians from a single image. The rendered images are refined through a neural refiner. Experimental results demonstrate that GUAVA significantly outperforms previous methods in rendering quality and offers significant speed improvements, with reconstruction times in the sub-second range (0.1s), and supports real-time animation and rendering.
HRAvatar: High-Quality and Relightable Gaussian Head Avatar
Mar 11, 2025Reconstructing animatable and high-quality 3D head avatars from monocular videos, especially with realistic relighting, is a valuable task. However, the limited information from single-view input, combined with the complex head poses and facial movements, makes this challenging. Previous methods achieve real-time performance by combining 3D Gaussian Splatting with a parametric head model, but the resulting head quality suffers from inaccurate face tracking and limited expressiveness of the deformation model. These methods also fail to produce realistic effects under novel lighting conditions. To address these issues, we propose HRAvatar, a 3DGS-based method that reconstructs high-fidelity, relightable 3D head avatars. HRAvatar reduces tracking errors through end-to-end optimization and better captures individual facial deformations using learnable blendshapes and learnable linear blend skinning. Additionally, it decomposes head appearance into several physical properties and incorporates physically-based shading to account for environmental lighting. Extensive experiments demonstrate that HRAvatar not only reconstructs superior-quality heads but also achieves realistic visual effects under varying lighting conditions.
Qffusion: Controllable Portrait Video Editing via Quadrant-Grid Attention Learning
Jan 11, 2025This paper presents Qffusion, a dual-frame-guided framework for portrait video editing. Specifically, we consider a design principle of ``animation for editing'', and train Qffusion as a general animation framework from two still reference images while we can use it for portrait video editing easily by applying modified start and end frames as references during inference. Leveraging the powerful generative power of Stable Diffusion, we propose a Quadrant-grid Arrangement (QGA) scheme for latent re-arrangement, which arranges the latent codes of two reference images and that of four facial conditions into a four-grid fashion, separately. Then, we fuse features of these two modalities and use self-attention for both appearance and temporal learning, where representations at different times are jointly modeled under QGA. Our Qffusion can achieve stable video editing without additional networks or complex training stages, where only the input format of Stable Diffusion is modified. Further, we propose a Quadrant-grid Propagation (QGP) inference strategy, which enjoys a unique advantage on stable arbitrary-length video generation by processing reference and condition frames recursively. Through extensive experiments, Qffusion consistently outperforms state-of-the-art techniques on portrait video editing.
Identity-Preserving Video Dubbing Using Motion Warping
Jan 08, 2025



Video dubbing aims to synthesize realistic, lip-synced videos from a reference video and a driving audio signal. Although existing methods can accurately generate mouth shapes driven by audio, they often fail to preserve identity-specific features, largely because they do not effectively capture the nuanced interplay between audio cues and the visual attributes of reference identity . As a result, the generated outputs frequently lack fidelity in reproducing the unique textural and structural details of the reference identity. To address these limitations, we propose IPTalker, a novel and robust framework for video dubbing that achieves seamless alignment between driving audio and reference identity while ensuring both lip-sync accuracy and high-fidelity identity preservation. At the core of IPTalker is a transformer-based alignment mechanism designed to dynamically capture and model the correspondence between audio features and reference images, thereby enabling precise, identity-aware audio-visual integration. Building on this alignment, a motion warping strategy further refines the results by spatially deforming reference images to match the target audio-driven configuration. A dedicated refinement process then mitigates occlusion artifacts and enhances the preservation of fine-grained textures, such as mouth details and skin features. Extensive qualitative and quantitative evaluations demonstrate that IPTalker consistently outperforms existing approaches in terms of realism, lip synchronization, and identity retention, establishing a new state of the art for high-quality, identity-consistent video dubbing.
GPAvatar: Generalizable and Precise Head Avatar from Image(s)
Jan 18, 2024
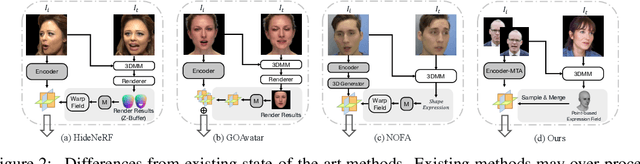


Head avatar reconstruction, crucial for applications in virtual reality, online meetings, gaming, and film industries, has garnered substantial attention within the computer vision community. The fundamental objective of this field is to faithfully recreate the head avatar and precisely control expressions and postures. Existing methods, categorized into 2D-based warping, mesh-based, and neural rendering approaches, present challenges in maintaining multi-view consistency, incorporating non-facial information, and generalizing to new identities. In this paper, we propose a framework named GPAvatar that reconstructs 3D head avatars from one or several images in a single forward pass. The key idea of this work is to introduce a dynamic point-based expression field driven by a point cloud to precisely and effectively capture expressions. Furthermore, we use a Multi Tri-planes Attention (MTA) fusion module in the tri-planes canonical field to leverage information from multiple input images. The proposed method achieves faithful identity reconstruction, precise expression control, and multi-view consistency, demonstrating promising results for free-viewpoint rendering and novel view synthesis.