 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Time Conformal Reasoning with Valid Factuality Control for Large Language Models
Jun 07, 2026Large language models (LLMs) increasingly perform multi-step reasoning, where intermediate claims form implicit directed acyclic graphs whose node correctness is structurally conditioned on their ancestors. This makes factuality uncertainty structural, rather than a trivial accumulation of node-wise errors, and necessitates inference-time uncertainty quantification over the reasoning structure. While conformal prediction (CP) offers flexible user-specified factuality control, existing work remains post-hoc and cannot intervene during generation. To fill the gap between CP's flexibility and its post-hoc limitation, we propose an \emph{Inference-Time Conformal Reasoning (ITCR)} framework that integrates CP directly into reasoning graph generation. ITCR learns a structure-level factuality uncertainty function that aggregates claim-level factuality signals over reasoning graphs without complex modeling assumptions. We then design the non-conformity score based on graph-level factuality uncertainty and calibrate the conformal threshold to decide when to stop generation. We theoretically show such generation is nested, yielding valid coverage guarantees for factuality control. Experiments over multiple datasets and coverage objectives demonstrate empirically valid coverage. In downstream reasoning tasks, inference-time calibrated graphs yield more accurate generation than post-hoc pruned graphs.
Inline Critic Steers Image Editing
May 12, 2026Instruction-based image editing exhibits heterogeneous difficulty not only across cases but also across regions of an image, motivating refinement approaches that allocate correction to where the model struggles. Existing refinement signals arrive late, after a fully generated image or a completed denoising step. We ask whether such a signal can act within an ongoing forward pass. To investigate this, we probe a frozen image-editing model and find that although generation capability emerges only in the last few layers, the error pattern is already set in early layers (rank correlation \r{ho} = 0.83 with the final-layer error map). Based on this, we introduce Inline Critic, a learnable token that critiques a frozen model's predictions at its intermediate layers and steers its hidden states to refine generation during the forward pass. A three-stage recipe is proposed to stabilize the training from learning how to critique to steering generation. As a result, we achieve state of the art on GEdit-Bench (7.89), a +9.4 gain on RISEBench over the same backbone, and the strongest open-source result on KRIS-Bench (81.92, surpassing GPT-4o). We further provide analyses showing that the critic genuinely shapes the model's attention and prediction updates at subsequent layers.
Conformal Margin Risk Minimization: An Envelope Framework for Robust Learning under Label Noise
Apr 07, 2026Most methods for learning with noisy labels require privileged knowledge such as noise transition matrices, clean subsets or pretrained feature extractors, resources typically unavailable when robustness is most needed. We propose Conformal Margin Risk Minimization (CMRM), a plug-and-play envelope framework that improves any classification loss under label noise by adding a single quantile-calibrated regularization term, with no privileged knowledge or training pipeline modification. CMRM measures the confidence margin between the observed label and competing labels, and thresholds it with a conformal quantile estimated per batch to focus training on high-margin samples while suppressing likely mislabeled ones. We derive a learning bound for CMRM under arbitrary label noise requiring only mild regularity of the margin distribution. Across five base methods and six benchmarks with synthetic and real-world noise, CMRM consistently improves accuracy (up to +3.39%), reduces conformal prediction set size (up to -20.44%) and does not hurt under 0% noise, showing that CMRM captures a method-agnostic uncertainty signal that existing mechanisms did not exploit.
RayMap3R: Inference-Time RayMap for Dynamic 3D Reconstruction
Mar 21, 2026Streaming feed-forward 3D reconstruction enables real-time joint estimation of scene geometry and camera poses from RGB images. However, without explicit dynamic reasoning, streaming models can be affected by moving objects, causing artifacts and drift. In this work, we propose RayMap3R, a training-free streaming framework for dynamic scene reconstruction. We observe that RayMap-based predictions exhibit a static-scene bias, providing an internal cue for dynamic identification. Based on this observation, we construct a dual-branch inference scheme that identifies dynamic regions by contrasting RayMap and image predictions, suppressing their interference during memory updates. We further introduce reset metric alignment and state-aware smoothing to preserve metric consistency and stabilize predicted trajectories. Our method achieves state-of-the-art performance among streaming approaches on dynamic scene reconstruction across multiple benchmarks.
VLA Knows Its Limits
Feb 24, 2026Action chunking has recently emerged as a standard practice in flow-based Vision-Language-Action (VLA) models. However, the effect and choice of the execution horizon - the number of actions to be executed from each predicted chunk - remains underexplored. In this work, we first show that varying the execution horizon leads to substantial performance deviations, with performance initially improving and then declining as the horizon increases. To uncover the reasons, we analyze the cross- and self-attention weights in flow-based VLAs and reveal two key phenomena: (i) intra-chunk actions attend invariantly to vision-language tokens, limiting adaptability to environmental changes; and (ii) the initial and terminal action tokens serve as stable anchors, forming latent centers around which intermediate actions are organized. Motivated by these insights, we interpret action self-attention weights as a proxy for the model's predictive limit and propose AutoHorizon, the first test-time method that dynamically estimates the execution horizon for each predicted action chunk to adapt to changing perceptual conditions. Across simulated and real-world robotic manipulation tasks, AutoHorizon is performant, incurs negligible computational overhead, and generalizes across diverse tasks and flow-based models.
Bi-Level Prompt Optimization for Multimodal LLM-as-a-Judge
Feb 11, 2026Large language models (LLMs) have become widely adopted as automated judges for evaluating AI-generated content. Despite their success, aligning LLM-based evaluations with human judgments remains challenging. While supervised fine-tuning on human-labeled data can improve alignment, it is costly and inflexible, requiring new training for each task or dataset. Recent progress in auto prompt optimization (APO) offers a more efficient alternative by automatically improving the instructions that guide LLM judges. However, existing APO methods primarily target text-only evaluations and remain underexplored in multimodal settings. In this work, we study auto prompt optimization for multimodal LLM-as-a-judge, particularly for evaluating AI-generated images. We identify a key bottleneck: multimodal models can only process a limited number of visual examples due to context window constraints, which hinders effective trial-and-error prompt refinement. To overcome this, we propose BLPO, a bi-level prompt optimization framework that converts images into textual representations while preserving evaluation-relevant visual cues. Our bi-level optimization approach jointly refines the judge prompt and the I2T prompt to maintain fidelity under limited context budgets. Experiments on four datasets and three LLM judges demonstrate the effectiveness of our method.
Real-Time Robot Execution with Masked Action Chunking
Jan 27, 2026Real-time execution is essential for cyber-physical systems such as robots. These systems operate in dynamic real-world environments where even small delays can undermine responsiveness and compromise performance. Asynchronous inference has recently emerged as a system-level paradigm for real-time robot manipulation, enabling the next action chunk to be predicted while the current one is being executed. While this approach achieves real-time responsiveness, naive integration often results in execution failure. Previous methods attributed this failure to inter-chunk discontinuity and developed test-time algorithms to smooth chunk boundaries. In contrast, we identify another critical yet overlooked factor: intra-chunk inconsistency, where the robot's executed action chunk partially misaligns with its current perception. To address this, we propose REMAC, which learns corrective adjustments on the pretrained policy through masked action chunking, enabling the policy to remain resilient under mismatches between intended actions and actual execution during asynchronous inference. In addition, we introduce a prefix-preserved sampling procedure to reinforce inter-chunk continuity. Overall, our method delivers more reliable policies without incurring additional latency. Extensive experiments in both simulation and real-world settings demonstrate that our method enables faster task execution, maintains robustness across varying delays, and consistently achieves higher completion rates.
CogniMap3D: Cognitive 3D Mapping and Rapid Retrieval
Jan 13, 2026We present CogniMap3D, a bioinspired framework for dynamic 3D scene understanding and reconstruction that emulates human cognitive processes. Our approach maintains a persistent memory bank of static scenes, enabling efficient spatial knowledge storage and rapid retrieval. CogniMap3D integrates three core capabilities: a multi-stage motion cue framework for identifying dynamic objects, a cognitive mapping system for storing, recalling, and updating static scenes across multiple visits, and a factor graph optimization strategy for refining camera poses. Given an image stream, our model identifies dynamic regions through motion cues with depth and camera pose priors, then matches static elements against its memory bank. When revisiting familiar locations, CogniMap3D retrieves stored scenes, relocates cameras, and updates memory with new observations. Evaluations on video depth estimation, camera pose reconstruction, and 3D mapping tasks demonstrate its state-of-the-art performance, while effectively supporting continuous scene understanding across extended sequences and multiple visits.
Consistent Instance Field for Dynamic Scene Understanding
Dec 16, 2025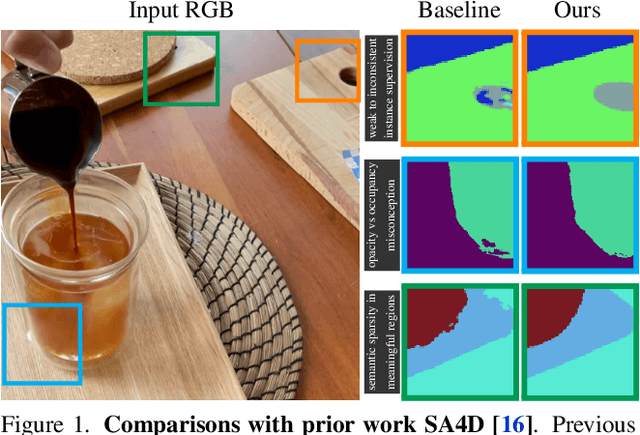
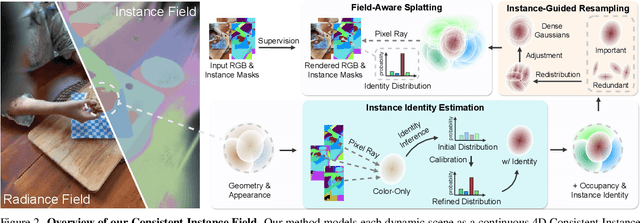
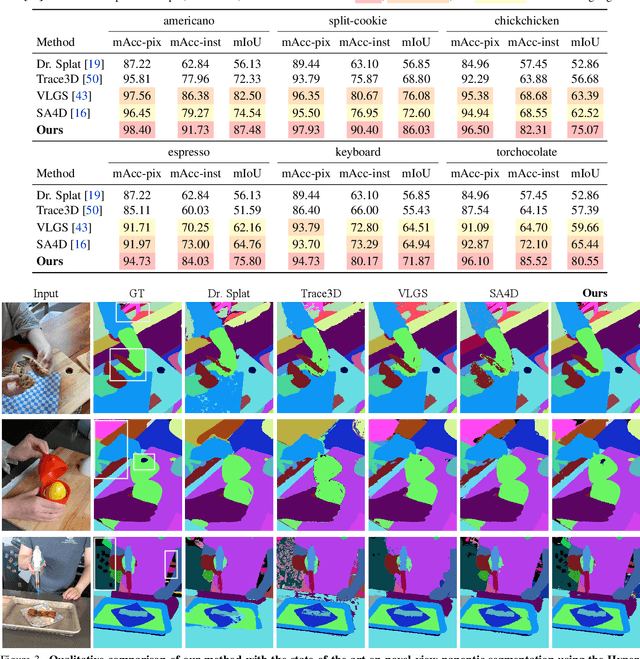
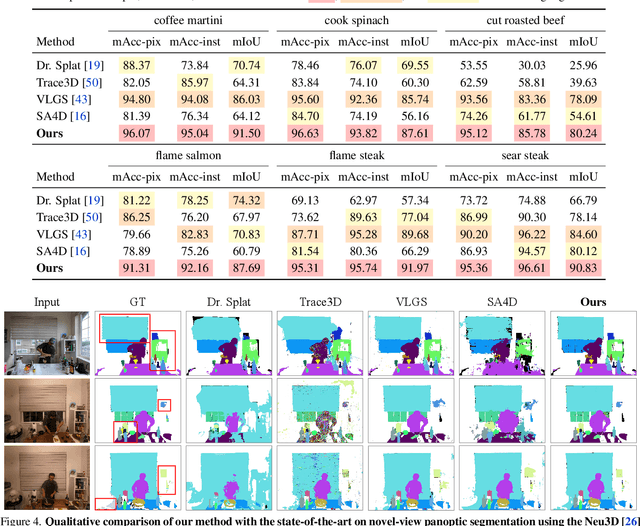
We introduce Consistent Instance Field, a continuous and probabilistic spatio-temporal representation for dynamic scene understanding. Unlike prior methods that rely on discrete tracking or view-dependent features, our approach disentangles visibility from persistent object identity by modeling each space-time point with an occupancy probability and a conditional instance distribution. To realize this, we introduce a novel instance-embedded representation based on deformable 3D Gaussians, which jointly encode radiance and semantic information and are learned directly from input RGB images and instance masks through differentiable rasterization. Furthermore, we introduce new mechanisms to calibrate per-Gaussian identities and resample Gaussians toward semantically active regions, ensuring consistent instance representations across space and time. Experiments on HyperNeRF and Neu3D datasets demonstrate that our method significantly outperforms state-of-the-art methods on novel-view panoptic segmentation and open-vocabulary 4D querying tasks.
Distill Video Datasets into Images
Dec 16, 2025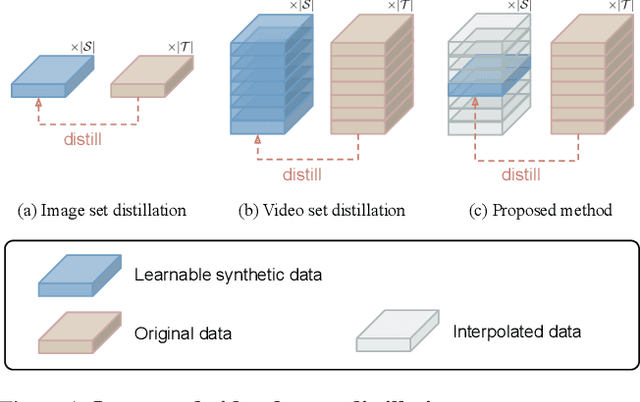
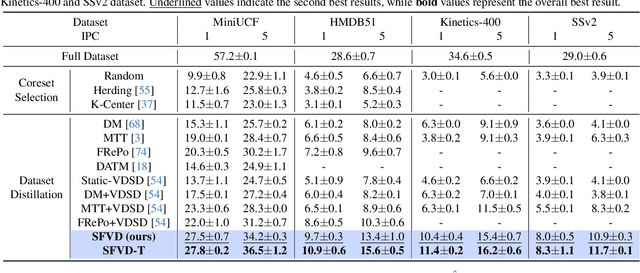
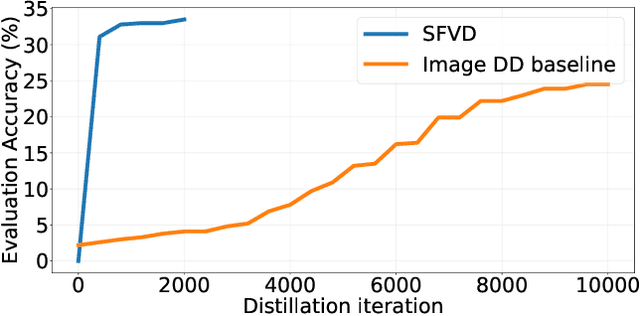
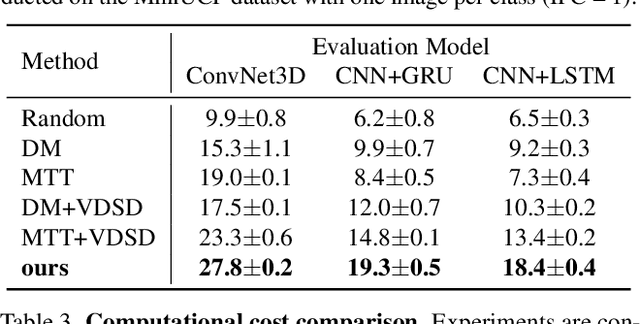
Dataset distillation aims to synthesize compact yet informative datasets that allow models trained on them to achieve performance comparable to training on the full dataset. While this approach has shown promising results for image data, extending dataset distillation methods to video data has proven challenging and often leads to suboptimal performance. In this work, we first identify the core challenge in video set distillation as the substantial increase in learnable parameters introduced by the temporal dimension of video, which complicates optimization and hinders convergence. To address this issue, we observe that a single frame is often sufficient to capture the discriminative semantics of a video. Leveraging this insight, we propose Single-Frame Video set Distillation (SFVD), a framework that distills videos into highly informative frames for each class. Using differentiable interpolation, these frames are transformed into video sequences and matched with the original dataset, while updates are restricted to the frames themselves for improved optimization efficiency. To further incorporate temporal information, the distilled frames are combined with sampled real videos from real videos during the matching process through a channel reshaping layer. Extensive experiments on multiple benchmarks demonstrate that SFVD substantially outperforms prior methods, achieving improvements of up to 5.3% on MiniUCF, thereby offering a more effective solution.