 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Instance Field for Dynamic Scene Understanding
Dec 16, 2025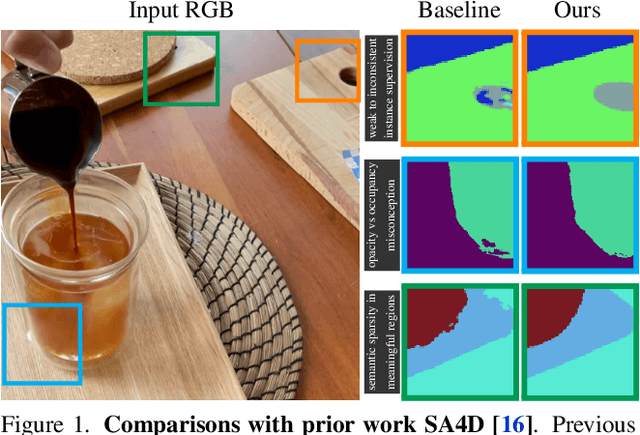
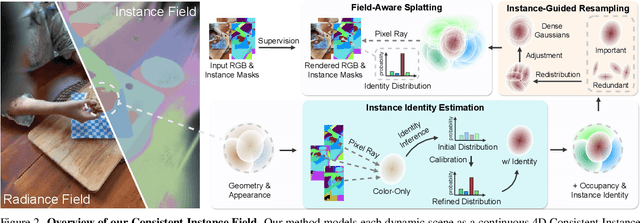
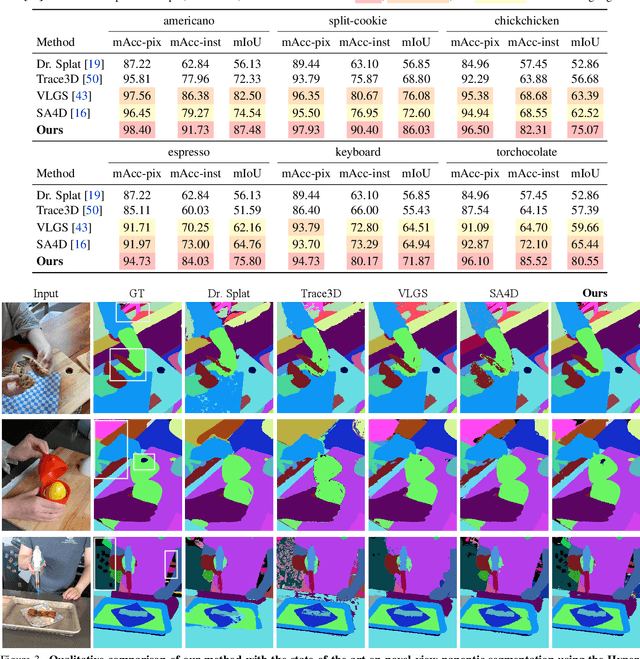
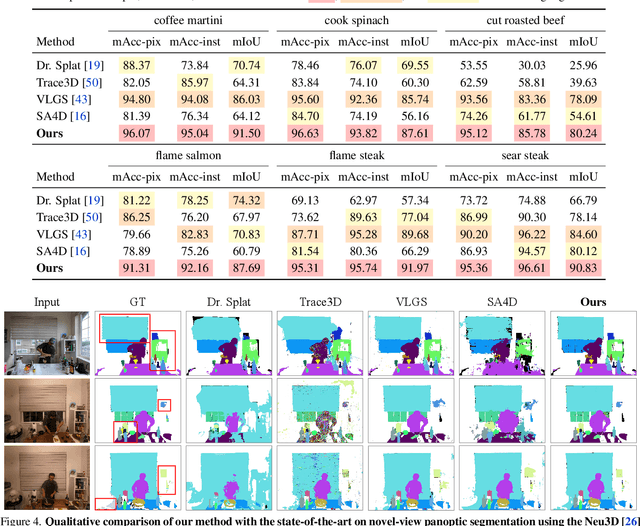
We introduce Consistent Instance Field, a continuous and probabilistic spatio-temporal representation for dynamic scene understanding. Unlike prior methods that rely on discrete tracking or view-dependent features, our approach disentangles visibility from persistent object identity by modeling each space-time point with an occupancy probability and a conditional instance distribution. To realize this, we introduce a novel instance-embedded representation based on deformable 3D Gaussians, which jointly encode radiance and semantic information and are learned directly from input RGB images and instance masks through differentiable rasterization. Furthermore, we introduce new mechanisms to calibrate per-Gaussian identities and resample Gaussians toward semantically active regions, ensuring consistent instance representations across space and time. Experiments on HyperNeRF and Neu3D datasets demonstrate that our method significantly outperforms state-of-the-art methods on novel-view panoptic segmentation and open-vocabulary 4D querying tasks.
MVI-Bench: A Comprehensive Benchmark for Evaluating Robustness to Misleading Visual Inputs in LVLMs
Nov 18, 2025

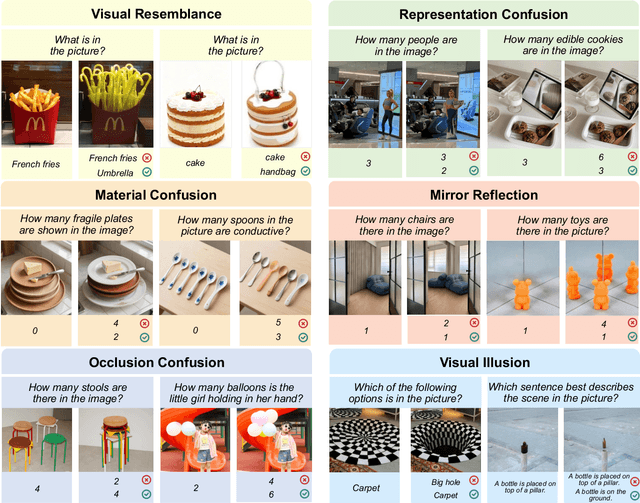

Evaluating the robustness of Large Vision-Language Models (LVLMs) is essential for their continued development and responsible deployment in real-world applications. However, existing robustness benchmarks typically focus on hallucination or misleading textual inputs, while largely overlooking the equally critical challenge posed by misleading visual inputs in assessing visual understanding. To fill this important gap, we introduce MVI-Bench, the first comprehensive benchmark specially designed for evaluating how Misleading Visual Inputs undermine the robustness of LVLMs. Grounded in fundamental visual primitives, the design of MVI-Bench centers on three hierarchical levels of misleading visual inputs: Visual Concept, Visual Attribute, and Visual Relationship. Using this taxonomy, we curate six representative categories and compile 1,248 expertly annotated VQA instances. To facilitate fine-grained robustness evaluation, we further introduce MVI-Sensitivity, a novel metric that characterizes LVLM robustness at a granular level. Empirical results across 18 state-of-the-art LVLMs uncover pronounced vulnerabilities to misleading visual inputs, and our in-depth analyses on MVI-Bench provide actionable insights that can guide the development of more reliable and robust LVLMs. The benchmark and codebase can be accessed at https://github.com/chenyil6/MVI-Bench.
Enhancing Dance-to-Music Generation via Negative Conditioning Latent Diffusion Model
Mar 28, 2025Conditional diffusion models have gained increasing attention since their impressive results for cross-modal synthesis, where the strong alignment between conditioning input and generated output can be achieved by training a time-conditioned U-Net augmented with cross-attention mechanism. In this paper, we focus on the problem of generating music synchronized with rhythmic visual cues of the given dance video. Considering that bi-directional guidance is more beneficial for training a diffusion model, we propose to enhance the quality of generated music and its synchronization with dance videos by adopting both positive rhythmic information and negative ones (PN-Diffusion) as conditions, where a dual diffusion and reverse processes is devised. Specifically, to train a sequential multi-modal U-Net structure, PN-Diffusion consists of a noise prediction objective for positive conditioning and an additional noise prediction objective for negative conditioning. To accurately define and select both positive and negative conditioning, we ingeniously utilize temporal correlations in dance videos, capturing positive and negative rhythmic cues by playing them forward and backward, respectively. Through subjective and objective evaluations of input-output correspondence in terms of dance-music beat alignment and the quality of generated music, experimental results on the AIST++ and TikTok dance video datasets demonstrate that our model outperforms SOTA dance-to-music generation models.
Forget Vectors at Play: Universal Input Perturbations Driving Machine Unlearning in Image Classification
Dec 21, 2024



Machine unlearning (MU), which seeks to erase the influence of specific unwanted data from already-trained models, is becoming increasingly vital in model editing, particularly to comply with evolving data regulations like the ``right to be forgotten''. Conventional approaches are predominantly model-based, typically requiring retraining or fine-tuning the model's weights to meet unlearning requirements. In this work, we approach the MU problem from a novel input perturbation-based perspective, where the model weights remain intact throughout the unlearning process. We demonstrate the existence of a proactive input-based unlearning strategy, referred to forget vector, which can be generated as an input-agnostic data perturbation and remains as effective as model-based approximate unlearning approaches. We also explore forget vector arithmetic, whereby multiple class-specific forget vectors are combined through simple operations (e.g., linear combinations) to generate new forget vectors for unseen unlearning tasks, such as forgetting arbitrary subsets across classes. Extensive experiments validate the effectiveness and adaptability of the forget vector, showcasing its competitive performance relative to state-of-the-art model-based methods. Codes are available at https://github.com/Changchangsun/Forget-Vector.
Visual Grounding with Attention-Driven Constraint Balancing
Jul 03, 2024Unlike Object Detection, Visual Grounding task necessitates the detection of an object described by complex free-form language. To simultaneously model such complex semantic and visual representations, recent state-of-the-art studies adopt transformer-based models to fuse features from both modalities, further introducing various modules that modulate visual features to align with the language expressions and eliminate the irrelevant redundant information. However, their loss function, still adopting common Object Detection losses, solely governs the bounding box regression output, failing to fully optimize for the above objectives. To tackle this problem, in this paper, we first analyze the attention mechanisms of transformer-based models. Building upon this, we further propose a novel framework named Attention-Driven Constraint Balancing (AttBalance) to optimize the behavior of visual features within language-relevant regions. Extensive experimental results show that our method brings impressive improvements. Specifically, we achieve constant improvements over five different models evaluated on four different benchmarks. Moreover, we attain a new state-of-the-art performance by integrating our method into QRNet.
Few-shot Medical Image Segmentation with Cycle-resemblance Attention
Dec 07, 2022



Recently, due to the increasing requirements of medical imaging applications and the professional requirements of annotating medical images, few-shot learning has gained increasing attention in the medical image semantic segmentation field. To perform segmentation with limited number of labeled medical images, most existing studies use Proto-typical Networks (PN) and have obtained compelling success. However, these approaches overlook the query image features extracted from the proposed representation network, failing to preserving the spatial connection between query and support images. In this paper, we propose a novel self-supervised few-shot medical image segmentation network and introduce a novel Cycle-Resemblance Attention (CRA) module to fully leverage the pixel-wise relation between query and support medical images. Notably, we first line up multiple attention blocks to refine more abundant relation information. Then, we present CRAPNet by integrating the CRA module with a classic prototype network, where pixel-wise relations between query and support features are well recaptured for segmentation. Extensive experiments on two different medical image datasets, e.g., abdomen MRI and abdomen CT, demonstrate the superiority of our model over existing state-of-the-art methods.
Semi-Supervised Video Inpainting with Cycle Consistency Constraints
Aug 14, 2022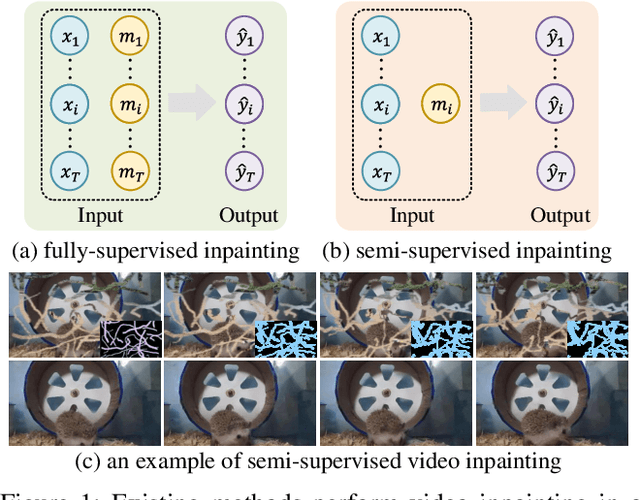
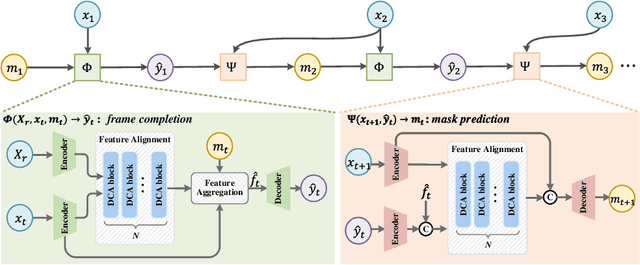

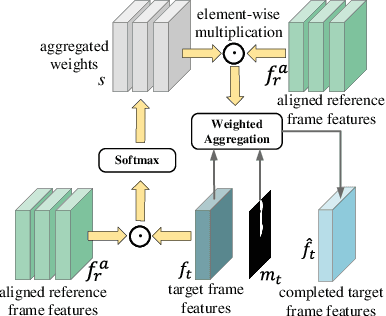
Deep learning-based video inpainting has yielded promising results and gained increasing attention from researchers. Generally, these methods usually assume that the corrupted region masks of each frame are known and easily obtained. However, the annotation of these masks are labor-intensive and expensive, which limits the practical application of current methods. Therefore, we expect to relax this assumption by defining a new semi-supervised inpainting setting, making the networks have the ability of completing the corrupted regions of the whole video using the annotated mask of only one frame. Specifically, in this work, we propose an end-to-end trainable framework consisting of completion network and mask prediction network, which are designed to generate corrupted contents of the current frame using the known mask and decide the regions to be filled of the next frame, respectively. Besides, we introduce a cycle consistency loss to regularize the training parameters of these two networks. In this way, the completion network and the mask prediction network can constrain each other, and hence the overall performance of the trained model can be maximized. Furthermore, due to the natural existence of prior knowledge (e.g., corrupted contents and clear borders), current video inpainting datasets are not suitable in the context of semi-supervised video inpainting. Thus, we create a new dataset by simulating the corrupted video of real-world scenarios. Extensive experimental results are reported to demonstrate the superiority of our model in the video inpainting task. Remarkably, although our model is trained in a semi-supervised manner, it can achieve comparable performance as fully-supervised methods.