 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-SimpleMem: Autoresearch-Guided Discovery of Lifelong Multimodal Agent Memory
Apr 02, 2026AI agents increasingly operate over extended time horizons, yet their ability to retain, organize, and recall multimodal experiences remains a critical bottleneck. Building effective lifelong memory requires navigating a vast design space spanning architecture, retrieval strategies, prompt engineering, and data pipelines; this space is too large and interconnected for manual exploration or traditional AutoML to explore effectively. We deploy an autonomous research pipeline to discover Omni-SimpleMem, a unified multimodal memory framework for lifelong AI agents. Starting from a naïve baseline (F1=0.117 on LoCoMo), the pipeline autonomously executes ${\sim}50$ experiments across two benchmarks, diagnosing failure modes, proposing architectural modifications, and repairing data pipeline bugs, all without human intervention in the inner loop. The resulting system achieves state-of-the-art on both benchmarks, improving F1 by +411% on LoCoMo (0.117$\to$0.598) and +214% on Mem-Gallery (0.254$\to$0.797) relative to the initial configurations. Critically, the most impactful discoveries are not hyperparameter adjustments: bug fixes (+175%), architectural changes (+44%), and prompt engineering (+188% on specific categories) each individually exceed the cumulative contribution of all hyperparameter tuning, demonstrating capabilities fundamentally beyond the reach of traditional AutoML. We provide a taxonomy of six discovery types and identify four properties that make multimodal memory particularly suited for autoresearch, offering guidance for applying autonomous research pipelines to other AI system domains. Code is available at this https://github.com/aiming-lab/SimpleMem.
LangMARL: Natural Language Multi-Agent Reinforcement Learning
Apr 01, 2026Large language model (LLM) agents struggle to autonomously evolve coordination strategies in dynamic environments, largely because coarse global outcomes obscure the causal signals needed for local policy refinement. We identify this bottleneck as a multi-agent credit assignment problem, which has long been studied in classical multi-agent reinforcement learning (MARL) but remains underaddressed in LLM-based systems. Building on this observation, we propose LangMARL, a framework that brings credit assignment and policy gradient evolution from cooperative MARL into the language space. LangMARL introduces agent-level language credit assignment, pioneers gradient evolution in language space for policy improvement, and summarizes task-relevant causal relations from replayed trajectories to provide dense feedback and improve convergence under sparse rewards. Extensive experiments across diverse cooperative multi-agent tasks demonstrate improved sample efficiency, interpretability, and strong generalization.
AgentDS Technical Report: Benchmarking the Future of Human-AI Collaboration in Domain-Specific Data Science
Mar 19, 2026Data science plays a critical role in transforming complex data into actionable insights across numerous domains. Recent developments in large language models (LLMs) and artificial intelligence (AI) agents have significantly automated data science workflow. However, it remains unclear to what extent AI agents can match the performance of human experts on domain-specific data science tasks, and in which aspects human expertise continues to provide advantages. We introduce AgentDS, a benchmark and competition designed to evaluate both AI agents and human-AI collaboration performance in domain-specific data science. AgentDS consists of 17 challenges across six industries: commerce, food production, healthcare, insurance, manufacturing, and retail banking. We conducted an open competition involving 29 teams and 80 participants, enabling systematic comparison between human-AI collaborative approaches and AI-only baselines. Our results show that current AI agents struggle with domain-specific reasoning. AI-only baselines perform near or below the median of competition participants, while the strongest solutions arise from human-AI collaboration. These findings challenge the narrative of complete automation by AI and underscore the enduring importance of human expertise in data science, while illuminating directions for the next generation of AI. Visit the AgentDS website here: https://agentds.org/ and open source datasets here: https://huggingface.co/datasets/lainmn/AgentDS .
ReTabSyn: Realistic Tabular Data Synthesis via Reinforcement Learning
Mar 11, 2026Deep generative models can help with data scarcity and privacy by producing synthetic training data, but they struggle in low-data, imbalanced tabular settings to fully learn the complex data distribution. We argue that striving for the full joint distribution could be overkill; for greater data efficiency, models should prioritize learning the conditional distribution $P(y\mid \bm{X})$, as suggested by recent theoretical analysis. Therefore, we overcome this limitation with \textbf{ReTabSyn}, a \textbf{Re}inforced \textbf{Tab}ular \textbf{Syn}thesis pipeline that provides direct feedback on feature correlation preservation during synthesizer training. This objective encourages the generator to prioritize the most useful predictive signals when training data is limited, thereby strengthening downstream model utility. We empirically fine-tune a language model-based generator using this approach, and across benchmarks with small sample sizes, class imbalance, and distribution shift, ReTabSyn consistently outperforms state-of-the-art baselines. Moreover, our approach can be readily extended to control various aspects of synthetic tabular data, such as applying expert-specified constraints on generated observations.
HiPER: Hierarchical Reinforcement Learning with Explicit Credit Assignment for Large Language Model Agents
Feb 18, 2026Training LLMs as interactive agents for multi-turn decision-making remains challenging, particularly in long-horizon tasks with sparse and delayed rewards, where agents must execute extended sequences of actions before receiving meaningful feedback. Most existing reinforcement learning (RL) approaches model LLM agents as flat policies operating at a single time scale, selecting one action at each turn. In sparse-reward settings, such flat policies must propagate credit across the entire trajectory without explicit temporal abstraction, which often leads to unstable optimization and inefficient credit assignment. We propose HiPER, a novel Hierarchical Plan-Execute RL framework that explicitly separates high-level planning from low-level execution. HiPER factorizes the policy into a high-level planner that proposes subgoals and a low-level executor that carries them out over multiple action steps. To align optimization with this structure, we introduce a key technique called hierarchical advantage estimation (HAE), which carefully assigns credit at both the planning and execution levels. By aggregating returns over the execution of each subgoal and coordinating updates across the two levels, HAE provides an unbiased gradient estimator and provably reduces variance compared to flat generalized advantage estimation. Empirically, HiPER achieves state-of-the-art performance on challenging interactive benchmarks, reaching 97.4\% success on ALFWorld and 83.3\% on WebShop with Qwen2.5-7B-Instruct (+6.6\% and +8.3\% over the best prior method), with especially large gains on long-horizon tasks requiring multiple dependent subtasks. These results highlight the importance of explicit hierarchical decomposition for scalable RL training of multi-turn LLM agents.
TMS: Trajectory-Mixed Supervision for Reward-Free, On-Policy SFT
Feb 03, 2026Reinforcement Learning (RL) and Supervised Fine-Tuning (SFT) are the two dominant paradigms for enhancing Large Language Model (LLM) performance on downstream tasks. While RL generally preserves broader model capabilities (retention) better than SFT, it comes with significant costs: complex reward engineering, instability, and expensive on-policy sampling. In contrast, SFT is efficient but brittle, often suffering from catastrophic forgetting due to $\textbf{Supervision Mismatch}$: the divergence between the model's evolving policy and static training labels. We address this trade-off with $\textbf{Trajectory-Mixed Supervision (TMS)}$, a reward-free framework that approximates the on-policy benefits of RL by creating a dynamic curriculum from the model's own historical checkpoints. TMS minimizes $\textit{Policy-Label Divergence (PLD)}$, preventing the mode collapse that drives forgetting in standard SFT. Experiments across reasoning (MATH, GSM8K) and instruction-following benchmarks demonstrate that TMS effectively shifts the accuracy--retention Pareto frontier. While RL remains the gold standard for retention, TMS significantly outperforms standard and iterative SFT, bridging the gap to RL without requiring reward models or verifiers. Mechanistic analysis confirms that PLD drift accurately predicts forgetting and that TMS successfully mitigates this drift.
Membership Inference Attacks Against Fine-tuned Diffusion Language Models
Jan 27, 2026Diffusion Language Models (DLMs) represent a promising alternative to autoregressive language models, using bidirectional masked token prediction. Yet their susceptibility to privacy leakage via Membership Inference Attacks (MIA) remains critically underexplored. This paper presents the first systematic investigation of MIA vulnerabilities in DLMs. Unlike the autoregressive models' single fixed prediction pattern, DLMs' multiple maskable configurations exponentially increase attack opportunities. This ability to probe many independent masks dramatically improves detection chances. To exploit this, we introduce SAMA (Subset-Aggregated Membership Attack), which addresses the sparse signal challenge through robust aggregation. SAMA samples masked subsets across progressive densities and applies sign-based statistics that remain effective despite heavy-tailed noise. Through inverse-weighted aggregation prioritizing sparse masks' cleaner signals, SAMA transforms sparse memorization detection into a robust voting mechanism. Experiments on nine datasets show SAMA achieves 30% relative AUC improvement over the best baseline, with up to 8 times improvement at low false positive rates. These findings reveal significant, previously unknown vulnerabilities in DLMs, necessitating the development of tailored privacy defenses.
MEDVISTAGYM: A Scalable Training Environment for Thinking with Medical Images via Tool-Integrated Reinforcement Learning
Jan 12, 2026Vision language models (VLMs) achieve strong performance on general image understanding but struggle to think with medical images, especially when performing multi-step reasoning through iterative visual interaction. Medical VLMs often rely on static visual embeddings and single-pass inference, preventing models from re-examining, verifying, or refining visual evidence during reasoning. While tool-integrated reasoning offers a promising path forward, open-source VLMs lack the training infrastructure to learn effective tool selection, invocation, and coordination in multi-modal medical reasoning. We introduce MedVistaGym, a scalable and interactive training environment that incentivizes tool-integrated visual reasoning for medical image analysis. MedVistaGym equips VLMs to determine when and which tools to invoke, localize task-relevant image regions, and integrate single or multiple sub-image evidence into interleaved multimodal reasoning within a unified, executable interface for agentic training. Using MedVistaGym, we train MedVistaGym-R1 to interleave tool use with agentic reasoning through trajectory sampling and end-to-end reinforcement learning. Across six medical VQA benchmarks, MedVistaGym-R1-8B exceeds comparably sized tool-augmented baselines by 19.10% to 24.21%, demonstrating that structured agentic training--not tool access alone--unlocks effective tool-integrated reasoning for medical image analysis.
Window-based Membership Inference Attacks Against Fine-tuned Large Language Models
Jan 06, 2026Most membership inference attacks (MIAs) against Large Language Models (LLMs) rely on global signals, like average loss, to identify training data. This approach, however, dilutes the subtle, localized signals of memorization, reducing attack effectiveness. We challenge this global-averaging paradigm, positing that membership signals are more pronounced within localized contexts. We introduce WBC (Window-Based Comparison), which exploits this insight through a sliding window approach with sign-based aggregation. Our method slides windows of varying sizes across text sequences, with each window casting a binary vote on membership based on loss comparisons between target and reference models. By ensembling votes across geometrically spaced window sizes, we capture memorization patterns from token-level artifacts to phrase-level structures. Extensive experiments across eleven datasets demonstrate that WBC substantially outperforms established baselines, achieving higher AUC scores and 2-3 times improvements in detection rates at low false positive thresholds. Our findings reveal that aggregating localized evidence is fundamentally more effective than global averaging, exposing critical privacy vulnerabilities in fine-tuned LLMs.
Can Agentic AI Match the Performance of Human Data Scientists?
Dec 24, 2025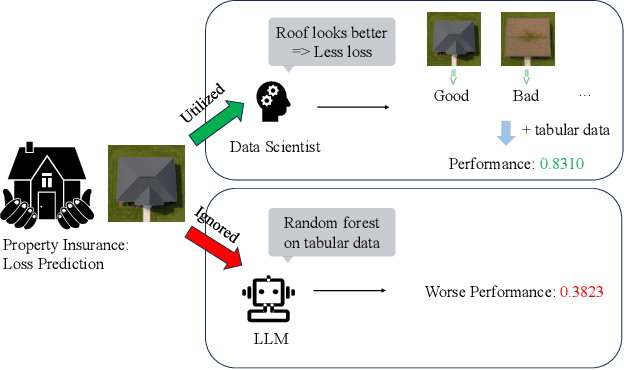

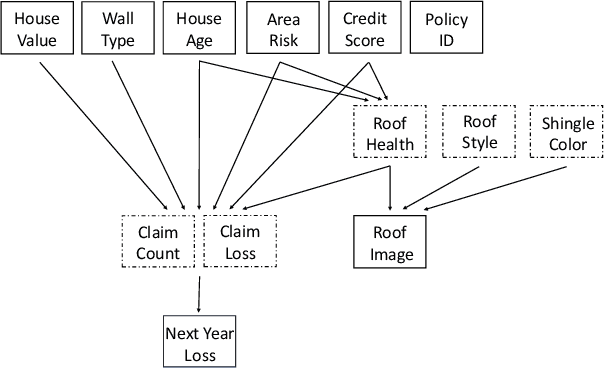

Data science plays a critical role in transforming complex data into actionable insights across numerous domains. Recent developments in large language models (LLMs) have significantly automated data science workflows, but a fundamental question persists: Can these agentic AI systems truly match the performance of human data scientists who routinely leverage domain-specific knowledge? We explore this question by designing a prediction task where a crucial latent variable is hidden in relevant image data instead of tabular features. As a result, agentic AI that generates generic codes for modeling tabular data cannot perform well, while human experts could identify the important hidden variable using domain knowledge. We demonstrate this idea with a synthetic dataset for property insurance. Our experiments show that agentic AI that relies on generic analytics workflow falls short of methods that use domain-specific insights. This highlights a key limitation of the current agentic AI for data science and underscores the need for future research to develop agentic AI systems that can better recognize and incorporate domain knowledge.