 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConQuER: Modular Architectures for Control and Bias Mitigation in IQP Quantum Generative Models
Sep 26, 2025Quantum generative models based on instantaneous quantum polynomial (IQP) circuits show great promise in learning complex distributions while maintaining classical trainability. However, current implementations suffer from two key limitations: lack of controllability over generated outputs and severe generation bias towards certain expected patterns. We present a Controllable Quantum Generative Framework, ConQuER, which addresses both challenges through a modular circuit architecture. ConQuER embeds a lightweight controller circuit that can be directly combined with pre-trained IQP circuits to precisely control the output distribution without full retraining. Leveraging the advantages of IQP, our scheme enables precise control over properties such as the Hamming Weight distribution with minimal parameter and gate overhead. In addition, inspired by the controller design, we extend this modular approach through data-driven optimization to embed implicit control paths in the underlying IQP architecture, significantly reducing generation bias on structured datasets. ConQuER retains efficient classical training properties and high scalability. We experimentally validate ConQuER on multiple quantum state datasets, demonstrating its superior control accuracy and balanced generation performance, only with very low overhead cost over original IQP circuits. Our framework bridges the gap between the advantages of quantum computing and the practical needs of controllable generation modeling.
Taming Diffusion for Dataset Distillation with High Representativeness
May 23, 2025Recent deep learning models demand larger datasets, driving the need for dataset distillation to create compact, cost-efficient datasets while maintaining performance. Due to the powerful image generation capability of diffusion, it has been introduced to this field for generating distilled images. In this paper, we systematically investigate issues present in current diffusion-based dataset distillation methods, including inaccurate distribution matching, distribution deviation with random noise, and separate sampling. Building on this, we propose D^3HR, a novel diffusion-based framework to generate distilled datasets with high representativeness. Specifically, we adopt DDIM inversion to map the latents of the full dataset from a low-normality latent domain to a high-normality Gaussian domain, preserving information and ensuring structural consistency to generate representative latents for the distilled dataset. Furthermore, we propose an efficient sampling scheme to better align the representative latents with the high-normality Gaussian distribution. Our comprehensive experiments demonstrate that D^3HR can achieve higher accuracy across different model architectures compared with state-of-the-art baselines in dataset distillation. Source code: https://github.com/lin-zhao-resoLve/D3HR.
ProDiF: Protecting Domain-Invariant Features to Secure Pre-Trained Models Against Extraction
Mar 17, 2025Pre-trained models are valuable intellectual property, capturing both domain-specific and domain-invariant features within their weight spaces. However, model extraction attacks threaten these assets by enabling unauthorized source-domain inference and facilitating cross-domain transfer via the exploitation of domain-invariant features. In this work, we introduce **ProDiF**, a novel framework that leverages targeted weight space manipulation to secure pre-trained models against extraction attacks. **ProDiF** quantifies the transferability of filters and perturbs the weights of critical filters in unsecured memory, while preserving actual critical weights in a Trusted Execution Environment (TEE) for authorized users. A bi-level optimization further ensures resilience against adaptive fine-tuning attacks. Experimental results show that **ProDiF** reduces source-domain accuracy to near-random levels and decreases cross-domain transferability by 74.65\%, providing robust protection for pre-trained models. This work offers comprehensive protection for pre-trained DNN models and highlights the potential of weight space manipulation as a novel approach to model security.
Towards Vector Optimization on Low-Dimensional Vector Symbolic Architecture
Feb 19, 2025



Vector Symbolic Architecture (VSA) is emerging in machine learning due to its efficiency, but they are hindered by issues of hyperdimensionality and accuracy. As a promising mitigation, the Low-Dimensional Computing (LDC) method significantly reduces the vector dimension by ~100 times while maintaining accuracy, by employing a gradient-based optimization. Despite its potential, LDC optimization for VSA is still underexplored. Our investigation into vector updates underscores the importance of stable, adaptive dynamics in LDC training. We also reveal the overlooked yet critical roles of batch normalization (BN) and knowledge distillation (KD) in standard approaches. Besides the accuracy boost, BN does not add computational overhead during inference, and KD significantly enhances inference confidence. Through extensive experiments and ablation studies across multiple benchmarks, we provide a thorough evaluation of our approach and extend the interpretability of binary neural network optimization similar to LDC, previously unaddressed in BNN literature.
Large Language Model is Secretly a Protein Sequence Optimizer
Jan 16, 2025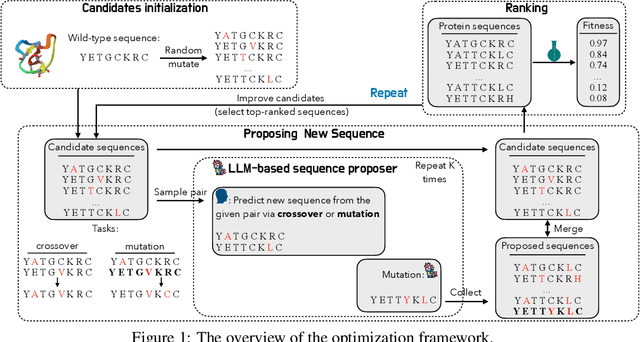
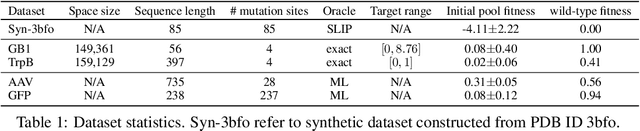
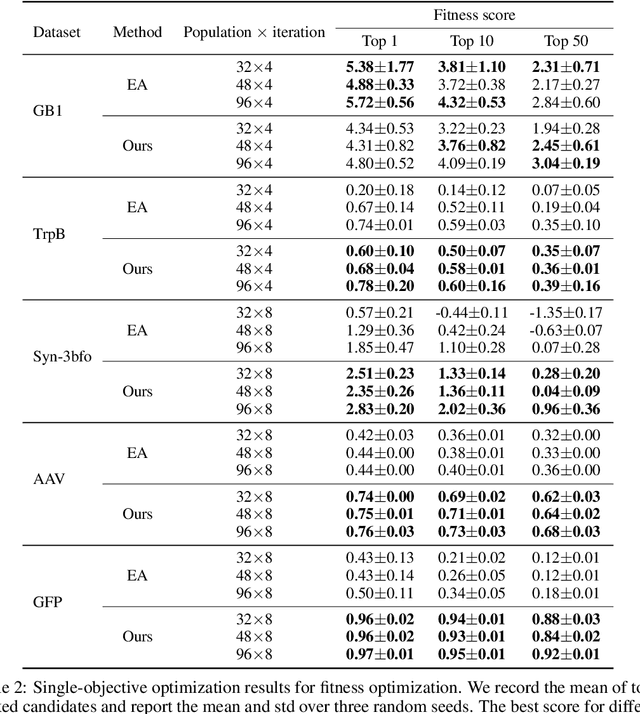
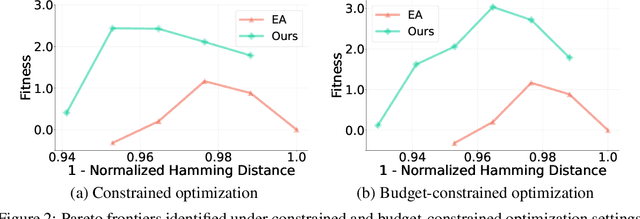
We consider the protein sequence engineering problem, which aims to find protein sequences with high fitness levels, starting from a given wild-type sequence. Directed evolution has been a dominating paradigm in this field which has an iterative process to generate variants and select via experimental feedback. We demonstrate large language models (LLMs), despite being trained on massive texts, are secretly protein sequence optimizers. With a directed evolutionary method, LLM can perform protein engineering through Pareto and experiment-budget constrained optimization, demonstrating success on both synthetic and experimental fitness landscapes.
Graph Generative Pre-trained Transformer
Jan 02, 2025



Graph generation is a critical task in numerous domains, including molecular design and social network analysis, due to its ability to model complex relationships and structured data. While most modern graph generative models utilize adjacency matrix representations, this work revisits an alternative approach that represents graphs as sequences of node set and edge set. We advocate for this approach due to its efficient encoding of graphs and propose a novel representation. Based on this representation, we introduce the Graph Generative Pre-trained Transformer (G2PT), an auto-regressive model that learns graph structures via next-token prediction. To further exploit G2PT's capabilities as a general-purpose foundation model, we explore fine-tuning strategies for two downstream applications: goal-oriented generation and graph property prediction. We conduct extensive experiments across multiple datasets. Results indicate that G2PT achieves superior generative performance on both generic graph and molecule datasets. Furthermore, G2PT exhibits strong adaptability and versatility in downstream tasks from molecular design to property prediction.
GraphCroc: Cross-Correlation Autoencoder for Graph Structural Reconstruction
Oct 04, 2024



Graph-structured data is integral to many applications, prompting the development of various graph representation methods. Graph autoencoders (GAEs), in particular, reconstruct graph structures from node embeddings. Current GAE models primarily utilize self-correlation to represent graph structures and focus on node-level tasks, often overlooking multi-graph scenarios. Our theoretical analysis indicates that self-correlation generally falls short in accurately representing specific graph features such as islands, symmetrical structures, and directional edges, particularly in smaller or multiple graph contexts. To address these limitations, we introduce a cross-correlation mechanism that significantly enhances the GAE representational capabilities. Additionally, we propose GraphCroc, a new GAE that supports flexible encoder architectures tailored for various downstream tasks and ensures robust structural reconstruction, through a mirrored encoding-decoding process. This model also tackles the challenge of representation bias during optimization by implementing a loss-balancing strategy. Both theoretical analysis and numerical evaluations demonstrate that our methodology significantly outperforms existing self-correlation-based GAEs in graph structure reconstruction.
AdaPI: Facilitating DNN Model Adaptivity for Efficient Private Inference in Edge Computing
Jul 08, 2024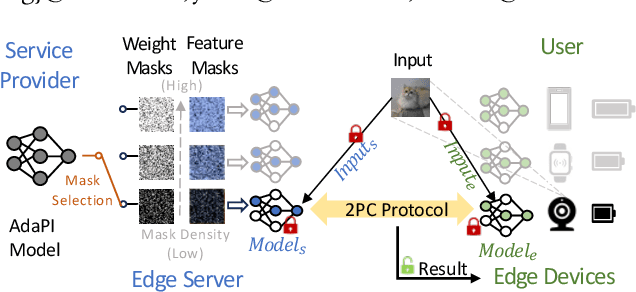
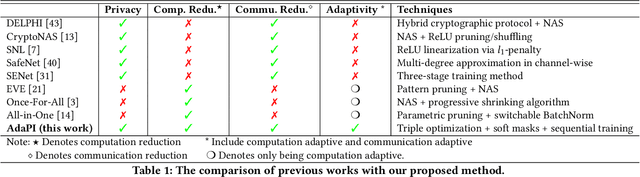
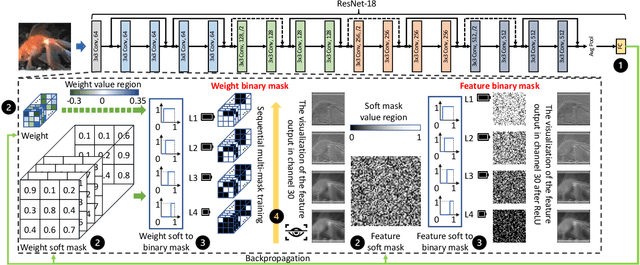
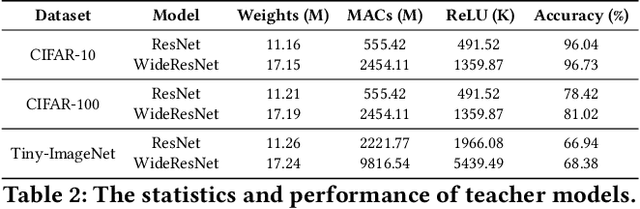
Private inference (PI) has emerged as a promising solution to execute computations on encrypted data, safeguarding user privacy and model parameters in edge computing. However, existing PI methods are predominantly developed considering constant resource constraints, overlooking the varied and dynamic resource constraints in diverse edge devices, like energy budgets. Consequently, model providers have to design specialized models for different devices, where all of them have to be stored on the edge server, resulting in inefficient deployment. To fill this gap, this work presents AdaPI, a novel approach that achieves adaptive PI by allowing a model to perform well across edge devices with diverse energy budgets. AdaPI employs a PI-aware training strategy that optimizes the model weights alongside weight-level and feature-level soft masks. These soft masks are subsequently transformed into multiple binary masks to enable adjustments in communication and computation workloads. Through sequentially training the model with increasingly dense binary masks, AdaPI attains optimal accuracy for each energy budget, which outperforms the state-of-the-art PI methods by 7.3\% in terms of test accuracy on CIFAR-100. The code of AdaPI can be accessed via https://github.com/jiahuiiiiii/AdaPI.
Bileve: Securing Text Provenance in Large Language Models Against Spoofing with Bi-level Signature
Jun 04, 2024



Text watermarks for large language models (LLMs) have been commonly used to identify the origins of machine-generated content, which is promising for assessing liability when combating deepfake or harmful content. While existing watermarking techniques typically prioritize robustness against removal attacks, unfortunately, they are vulnerable to spoofing attacks: malicious actors can subtly alter the meanings of LLM-generated responses or even forge harmful content, potentially misattributing blame to the LLM developer. To overcome this, we introduce a bi-level signature scheme, Bileve, which embeds fine-grained signature bits for integrity checks (mitigating spoofing attacks) as well as a coarse-grained signal to trace text sources when the signature is invalid (enhancing detectability) via a novel rank-based sampling strategy. Compared to conventional watermark detectors that only output binary results, Bileve can differentiate 5 scenarios during detection, reliably tracing text provenance and regulating LLMs. The experiments conducted on OPT-1.3B and LLaMA-7B demonstrate the effectiveness of Bileve in defeating spoofing attacks with enhanced detectability.
SSNet: A Lightweight Multi-Party Computation Scheme for Practical Privacy-Preserving Machine Learning Service in the Cloud
Jun 04, 2024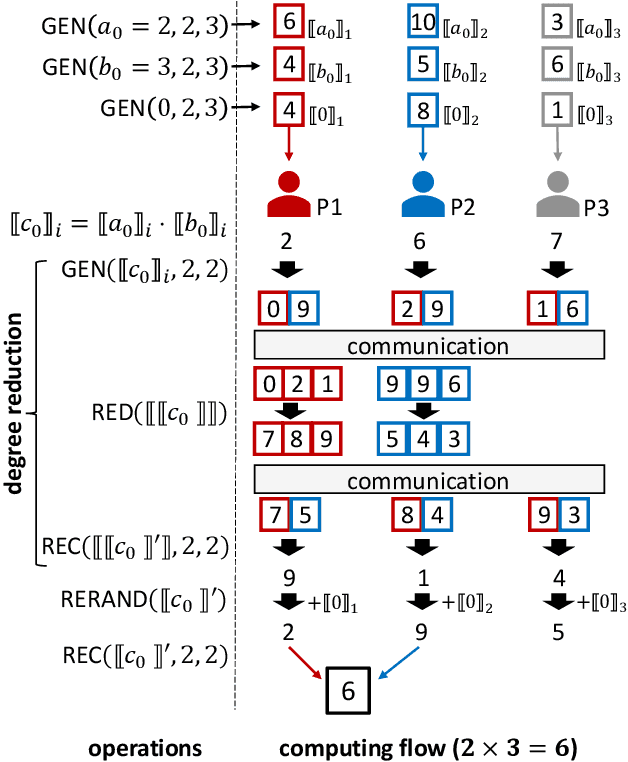
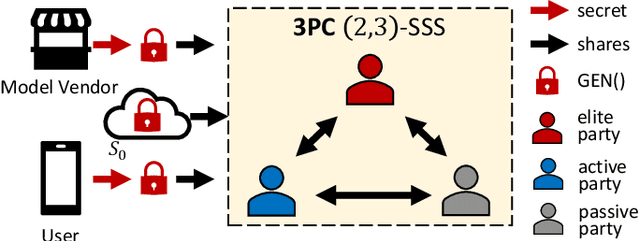
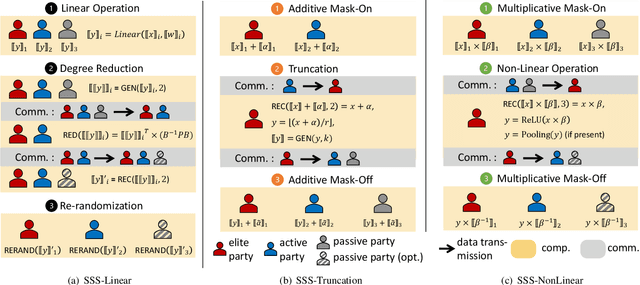
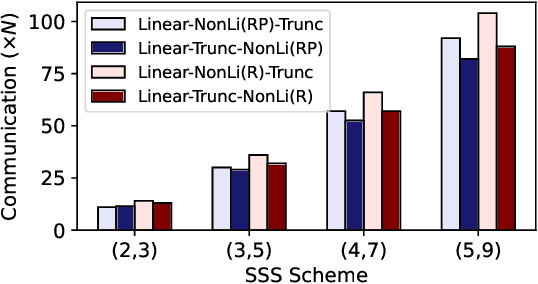
As privacy-preserving becomes a pivotal aspect of deep learning (DL) development, multi-party computation (MPC) has gained prominence for its efficiency and strong security. However, the practice of current MPC frameworks is limited, especially when dealing with large neural networks, exemplified by the prolonged execution time of 25.8 seconds for secure inference on ResNet-152. The primary challenge lies in the reliance of current MPC approaches on additive secret sharing, which incurs significant communication overhead with non-linear operations such as comparisons. Furthermore, additive sharing suffers from poor scalability on party size. In contrast, the evolving landscape of MPC necessitates accommodating a larger number of compute parties and ensuring robust performance against malicious activities or computational failures. In light of these challenges, we propose SSNet, which for the first time, employs Shamir's secret sharing (SSS) as the backbone of MPC-based ML framework. We meticulously develop all framework primitives and operations for secure DL models tailored to seamlessly integrate with the SSS scheme. SSNet demonstrates the ability to scale up party numbers straightforwardly and embeds strategies to authenticate the computation correctness without incurring significant performance overhead. Additionally, SSNet introduces masking strategies designed to reduce communication overhead associated with non-linear operations. We conduct comprehensive experimental evaluations on commercial cloud computing infrastructure from Amazon AWS, as well as across diverse prevalent DNN models and datasets. SSNet demonstrates a substantial performance boost, achieving speed-ups ranging from 3x to 14x compared to SOTA MPC frameworks. Moreover, SSNet also represents the first framework that is evaluated on a five-party computation setup, in the context of secure DL inference.