 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecBridge: Bridging Mass Spectrometry and Molecular Representations via Cross-Modal Alignment
Jan 27, 2026Small-molecule identification from tandem mass spectrometry (MS/MS) remains a bottleneck in untargeted settings where spectral libraries are incomplete. While deep learning offers a solution, current approaches typically fall into two extremes: explicit generative models that construct molecular graphs atom-by-atom, or joint contrastive models that learn cross-modal subspaces from scratch. We introduce SpecBridge, a novel implicit alignment framework that treats structure identification as a geometric alignment problem. SpecBridge fine-tunes a self-supervised spectral encoder (DreaMS) to project directly into the latent space of a frozen molecular foundation model (ChemBERTa), and then performs retrieval by cosine similarity to a fixed bank of precomputed molecular embeddings. Across MassSpecGym, Spectraverse, and MSnLib benchmarks, SpecBridge improves top-1 retrieval accuracy by roughly 20-25% relative to strong neural baselines, while keeping the number of trainable parameters small. These results suggest that aligning to frozen foundation models is a practical, stable alternative to designing new architectures from scratch. The code for SpecBridge is released at https://github.com/HassounLab/SpecBridge.
Large Language Model is Secretly a Protein Sequence Optimizer
Jan 16, 2025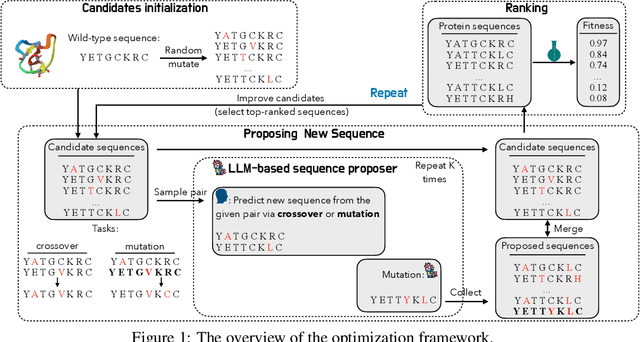
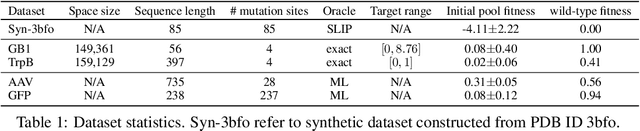
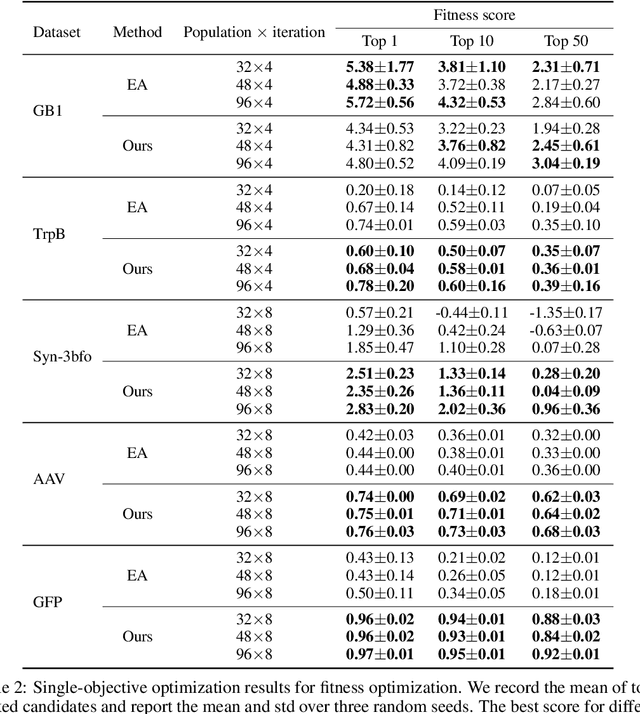
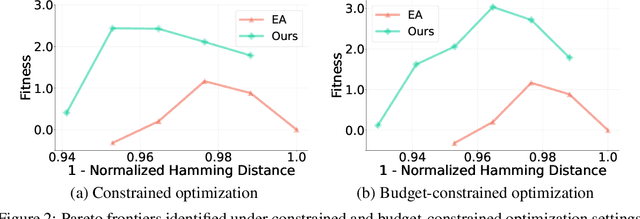
We consider the protein sequence engineering problem, which aims to find protein sequences with high fitness levels, starting from a given wild-type sequence. Directed evolution has been a dominating paradigm in this field which has an iterative process to generate variants and select via experimental feedback. We demonstrate large language models (LLMs), despite being trained on massive texts, are secretly protein sequence optimizers. With a directed evolutionary method, LLM can perform protein engineering through Pareto and experiment-budget constrained optimization, demonstrating success on both synthetic and experimental fitness landscapes.
MADGEN -- Mass-Spec attends to De Novo Molecular generation
Jan 03, 2025The annotation (assigning structural chemical identities) of MS/MS spectra remains a significant challenge due to the enormous molecular diversity in biological samples and the limited scope of reference databases. Currently, the vast majority of spectral measurements remain in the "dark chemical space" without structural annotations. To improve annotation, we propose MADGEN (Mass-spec Attends to De Novo Molecular GENeration), a scaffold-based method for de novo molecular structure generation guided by mass spectrometry data. MADGEN operates in two stages: scaffold retrieval and spectra-conditioned molecular generation starting with the scaffold. In the first stage, given an MS/MS spectrum, we formulate scaffold retrieval as a ranking problem and employ contrastive learning to align mass spectra with candidate molecular scaffolds. In the second stage, starting from the retrieved scaffold, we employ the MS/MS spectrum to guide an attention-based generative model to generate the final molecule. Our approach constrains the molecular generation search space, reducing its complexity and improving generation accuracy. We evaluate MADGEN on three datasets (NIST23, CANOPUS, and MassSpecGym) and evaluate MADGEN's performance with a predictive scaffold retriever and with an oracle retriever. We demonstrate the effectiveness of using attention to integrate spectral information throughout the generation process to achieve strong results with the oracle retriever.
Graph Generative Pre-trained Transformer
Jan 02, 2025



Graph generation is a critical task in numerous domains, including molecular design and social network analysis, due to its ability to model complex relationships and structured data. While most modern graph generative models utilize adjacency matrix representations, this work revisits an alternative approach that represents graphs as sequences of node set and edge set. We advocate for this approach due to its efficient encoding of graphs and propose a novel representation. Based on this representation, we introduce the Graph Generative Pre-trained Transformer (G2PT), an auto-regressive model that learns graph structures via next-token prediction. To further exploit G2PT's capabilities as a general-purpose foundation model, we explore fine-tuning strategies for two downstream applications: goal-oriented generation and graph property prediction. We conduct extensive experiments across multiple datasets. Results indicate that G2PT achieves superior generative performance on both generic graph and molecule datasets. Furthermore, G2PT exhibits strong adaptability and versatility in downstream tasks from molecular design to property prediction.
On Separate Normalization in Self-supervised Transformers
Sep 22, 2023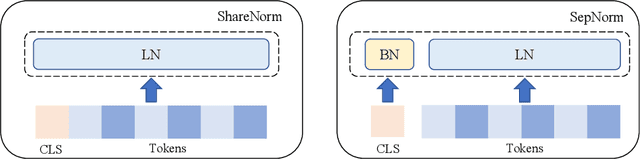

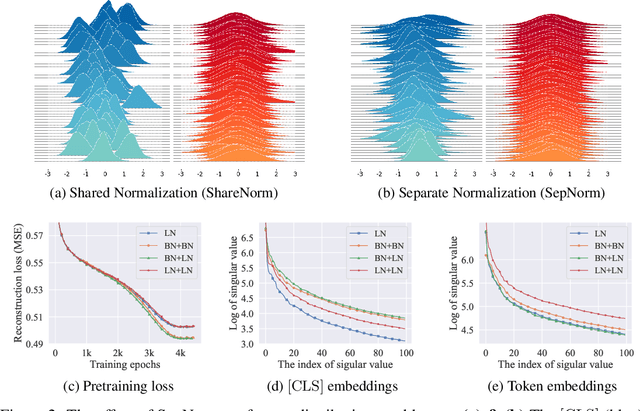
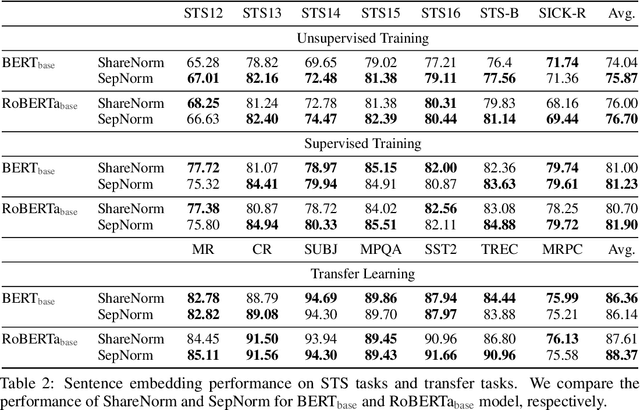
Self-supervised training methods for transformers have demonstrated remarkable performance across various domains. Previous transformer-based models, such as masked autoencoders (MAE), typically utilize a single normalization layer for both the [CLS] symbol and the tokens. We propose in this paper a simple modification that employs separate normalization layers for the tokens and the [CLS] symbol to better capture their distinct characteristics and enhance downstream task performance. Our method aims to alleviate the potential negative effects of using the same normalization statistics for both token types, which may not be optimally aligned with their individual roles. We empirically show that by utilizing a separate normalization layer, the [CLS] embeddings can better encode the global contextual information and are distributed more uniformly in its anisotropic space. When replacing the conventional normalization layer with the two separate layers, we observe an average 2.7% performance improvement over the image, natural language, and graph domains.
Multi-objective Deep Data Generation with Correlated Property Control
Oct 06, 2022



Developing deep generative models has been an emerging field due to the ability to model and generate complex data for various purposes, such as image synthesis and molecular design. However, the advancement of deep generative models is limited by challenges to generate objects that possess multiple desired properties: 1) the existence of complex correlation among real-world properties is common but hard to identify; 2) controlling individual property enforces an implicit partially control of its correlated properties, which is difficult to model; 3) controlling multiple properties under various manners simultaneously is hard and under-explored. We address these challenges by proposing a novel deep generative framework that recovers semantics and the correlation of properties through disentangled latent vectors. The correlation is handled via an explainable mask pooling layer, and properties are precisely retained by generated objects via the mutual dependence between latent vectors and properties. Our generative model preserves properties of interest while handling correlation and conflicts of properties under a multi-objective optimization framework. The experiments demonstrate our model's superior performance in generating data with desired properties.
A Survey on Deep Graph Generation: Methods and Applications
Mar 13, 2022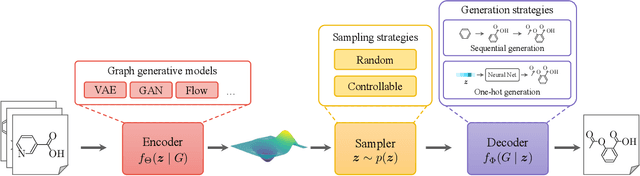

Graphs are ubiquitous in encoding relational information of real-world objects in many domains. Graph generation, whose purpose is to generate new graphs from a distribution similar to the observed graphs, has received increasing attention thanks to the recent advances of deep learning models. In this paper, we conduct a comprehensive review on the existing literature of graph generation from a variety of emerging methods to its wide application areas. Specifically, we first formulate the problem of deep graph generation and discuss its difference with several related graph learning tasks. Secondly, we divide the state-of-the-art methods into three categories based on model architectures and summarize their generation strategies. Thirdly, we introduce three key application areas of deep graph generation. Lastly, we highlight challenges and opportunities in the future study of deep graph generation.
Graph-based Ensemble Machine Learning for Student Performance Prediction
Dec 22, 2021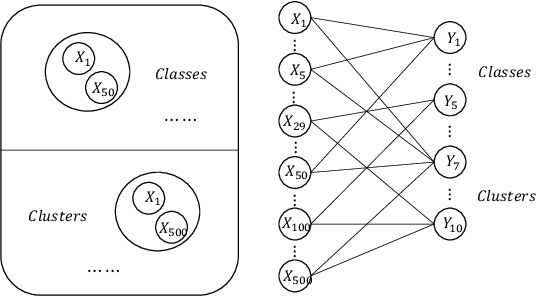
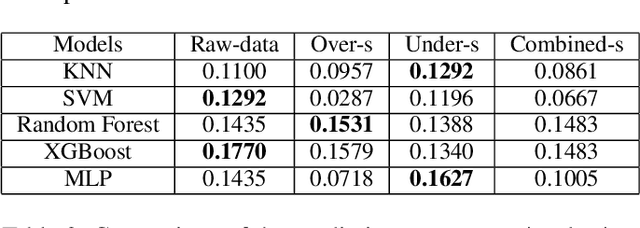

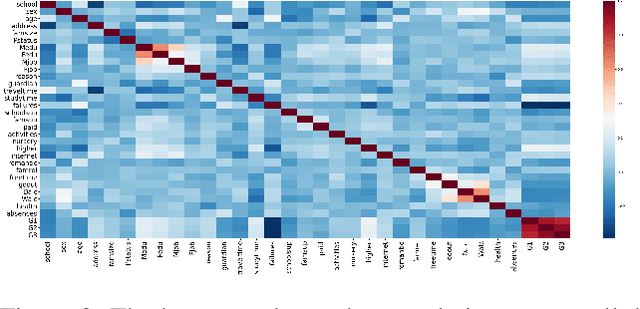
Student performance prediction is a critical research problem to understand the students' needs, present proper learning opportunities/resources, and develop the teaching quality. However, traditional machine learning methods fail to produce stable and accurate prediction results. In this paper, we propose a graph-based ensemble machine learning method that aims to improve the stability of single machine learning methods via the consensus of multiple methods. To be specific, we leverage both supervised prediction methods and unsupervised clustering methods, build an iterative approach that propagates in a bipartite graph as well as converges to more stable and accurate prediction results. Extensive experiments demonstrate the effectiveness of our proposed method in predicting more accurate student performance. Specifically, our model outperforms the best traditional machine learning algorithms by up to 14.8% in prediction accuracy.
Dataset Geography: Mapping Language Data to Language Users
Dec 07, 2021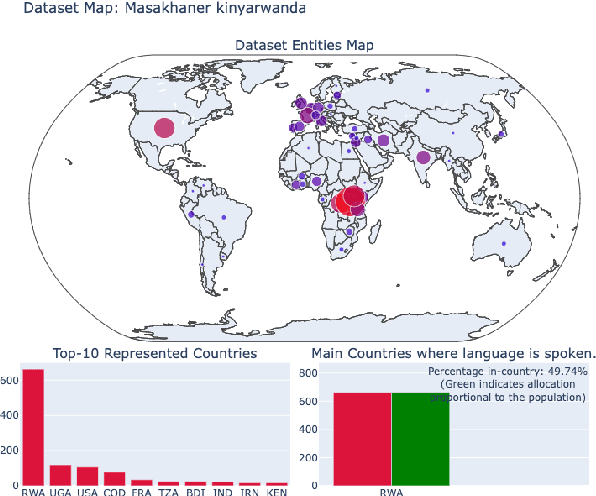
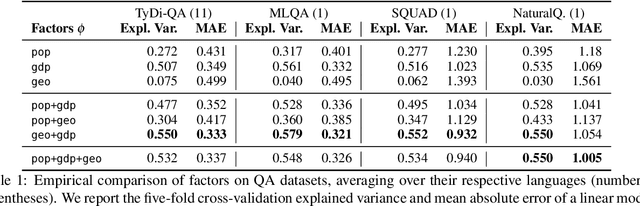
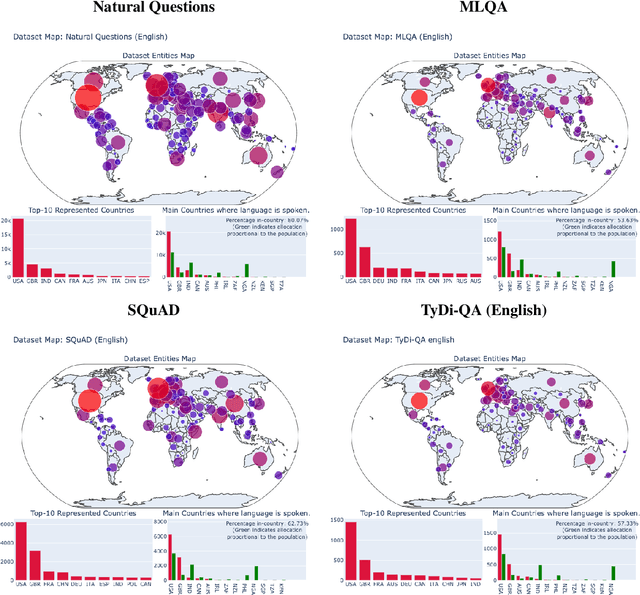
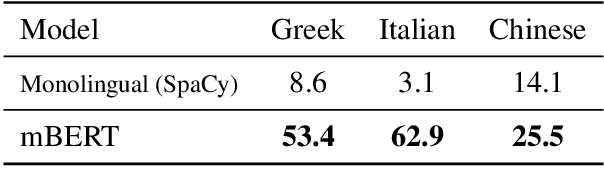
As language technologies become more ubiquitous, there are increasing efforts towards expanding the language diversity and coverage of natural language processing (NLP) systems. Arguably, the most important factor influencing the quality of modern NLP systems is data availability. In this work, we study the geographical representativeness of NLP datasets, aiming to quantify if and by how much do NLP datasets match the expected needs of the language speakers. In doing so, we use entity recognition and linking systems, also making important observations about their cross-lingual consistency and giving suggestions for more robust evaluation. Last, we explore some geographical and economic factors that may explain the observed dataset distributions. Code and data are available here: https://github.com/ffaisal93/dataset_geography. Additional visualizations are available here: https://nlp.cs.gmu.edu/project/datasetmaps/.