 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecBridge: Bridging Mass Spectrometry and Molecular Representations via Cross-Modal Alignment
Jan 27, 2026Small-molecule identification from tandem mass spectrometry (MS/MS) remains a bottleneck in untargeted settings where spectral libraries are incomplete. While deep learning offers a solution, current approaches typically fall into two extremes: explicit generative models that construct molecular graphs atom-by-atom, or joint contrastive models that learn cross-modal subspaces from scratch. We introduce SpecBridge, a novel implicit alignment framework that treats structure identification as a geometric alignment problem. SpecBridge fine-tunes a self-supervised spectral encoder (DreaMS) to project directly into the latent space of a frozen molecular foundation model (ChemBERTa), and then performs retrieval by cosine similarity to a fixed bank of precomputed molecular embeddings. Across MassSpecGym, Spectraverse, and MSnLib benchmarks, SpecBridge improves top-1 retrieval accuracy by roughly 20-25% relative to strong neural baselines, while keeping the number of trainable parameters small. These results suggest that aligning to frozen foundation models is a practical, stable alternative to designing new architectures from scratch. The code for SpecBridge is released at https://github.com/HassounLab/SpecBridge.
Incorporating Inductive Biases to Energy-based Generative Models
May 02, 2025



With the advent of score-matching techniques for model training and Langevin dynamics for sample generation, energy-based models (EBMs) have gained renewed interest as generative models. Recent EBMs usually use neural networks to define their energy functions. In this work, we introduce a novel hybrid approach that combines an EBM with an exponential family model to incorporate inductive bias into data modeling. Specifically, we augment the energy term with a parameter-free statistic function to help the model capture key data statistics. Like an exponential family model, the hybrid model aims to align the distribution statistics with data statistics during model training, even when it only approximately maximizes the data likelihood. This property enables us to impose constraints on the hybrid model. Our empirical study validates the hybrid model's ability to match statistics. Furthermore, experimental results show that data fitting and generation improve when suitable informative statistics are incorporated into the hybrid model.
Large Language Model is Secretly a Protein Sequence Optimizer
Jan 16, 2025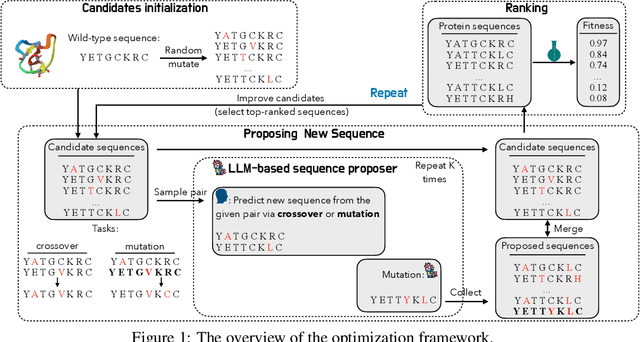
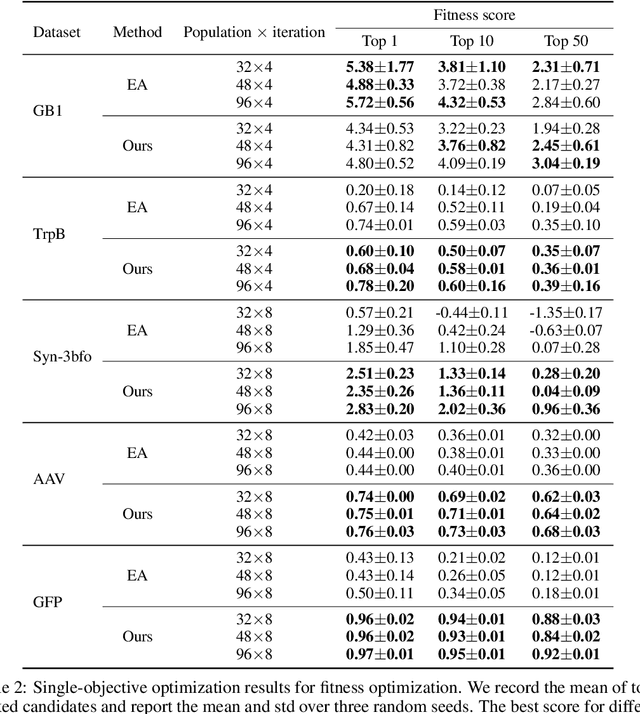
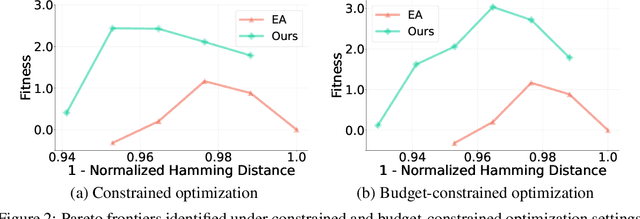
We consider the protein sequence engineering problem, which aims to find protein sequences with high fitness levels, starting from a given wild-type sequence. Directed evolution has been a dominating paradigm in this field which has an iterative process to generate variants and select via experimental feedback. We demonstrate large language models (LLMs), despite being trained on massive texts, are secretly protein sequence optimizers. With a directed evolutionary method, LLM can perform protein engineering through Pareto and experiment-budget constrained optimization, demonstrating success on both synthetic and experimental fitness landscapes.
Graph Generative Pre-trained Transformer
Jan 02, 2025



Graph generation is a critical task in numerous domains, including molecular design and social network analysis, due to its ability to model complex relationships and structured data. While most modern graph generative models utilize adjacency matrix representations, this work revisits an alternative approach that represents graphs as sequences of node set and edge set. We advocate for this approach due to its efficient encoding of graphs and propose a novel representation. Based on this representation, we introduce the Graph Generative Pre-trained Transformer (G2PT), an auto-regressive model that learns graph structures via next-token prediction. To further exploit G2PT's capabilities as a general-purpose foundation model, we explore fine-tuning strategies for two downstream applications: goal-oriented generation and graph property prediction. We conduct extensive experiments across multiple datasets. Results indicate that G2PT achieves superior generative performance on both generic graph and molecule datasets. Furthermore, G2PT exhibits strong adaptability and versatility in downstream tasks from molecular design to property prediction.
Graph-based Confidence Calibration for Large Language Models
Nov 03, 2024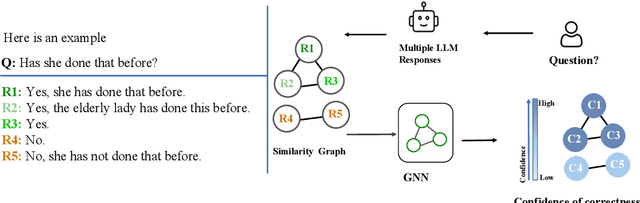
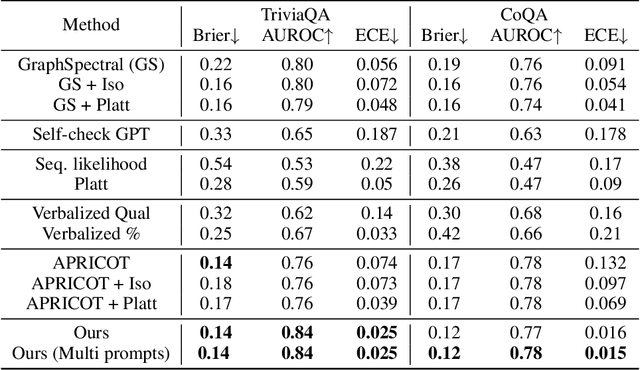
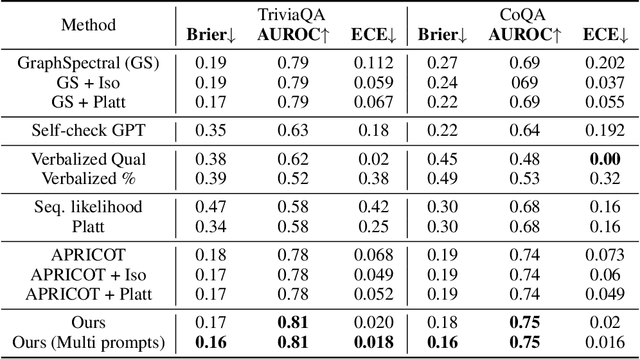
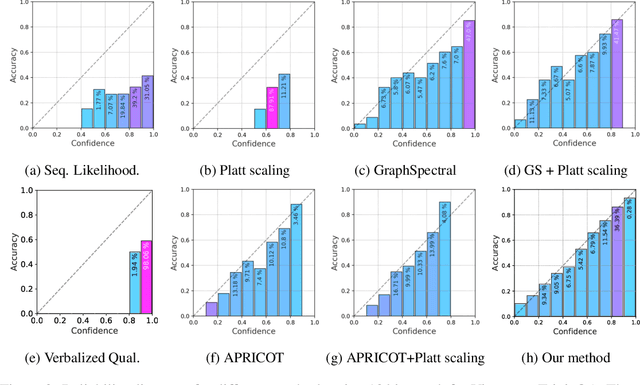
One important approach to improving the reliability of large language models (LLMs) is to provide accurate confidence estimations regarding the correctness of their answers. However, developing a well-calibrated confidence estimation model is challenging, as mistakes made by LLMs can be difficult to detect. We propose a novel method combining the LLM's self-consistency with labeled data and training an auxiliary model to estimate the correctness of its responses to questions. This auxiliary model predicts the correctness of responses based solely on their consistent information. To set up the learning problem, we use a weighted graph to represent the consistency among the LLM's multiple responses to a question. Correctness labels are assigned to these responses based on their similarity to the correct answer. We then train a graph neural network to estimate the probability of correct responses. Experiments demonstrate that the proposed approach substantially outperforms several of the most recent methods in confidence calibration across multiple widely adopted benchmark datasets. Furthermore, the proposed approach significantly improves the generalization capability of confidence calibration on out-of-domain (OOD) data.
MassSpecGym: A benchmark for the discovery and identification of molecules
Oct 30, 2024The discovery and identification of molecules in biological and environmental samples is crucial for advancing biomedical and chemical sciences. Tandem mass spectrometry (MS/MS) is the leading technique for high-throughput elucidation of molecular structures. However, decoding a molecular structure from its mass spectrum is exceptionally challenging, even when performed by human experts. As a result, the vast majority of acquired MS/MS spectra remain uninterpreted, thereby limiting our understanding of the underlying (bio)chemical processes. Despite decades of progress in machine learning applications for predicting molecular structures from MS/MS spectra, the development of new methods is severely hindered by the lack of standard datasets and evaluation protocols. To address this problem, we propose MassSpecGym -- the first comprehensive benchmark for the discovery and identification of molecules from MS/MS data. Our benchmark comprises the largest publicly available collection of high-quality labeled MS/MS spectra and defines three MS/MS annotation challenges: \textit{de novo} molecular structure generation, molecule retrieval, and spectrum simulation. It includes new evaluation metrics and a generalization-demanding data split, therefore standardizing the MS/MS annotation tasks and rendering the problem accessible to the broad machine learning community. MassSpecGym is publicly available at \url{https://github.com/pluskal-lab/MassSpecGym}.
Reason out Your Layout: Evoking the Layout Master from Large Language Models for Text-to-Image Synthesis
Nov 28, 2023



Recent advancements in text-to-image (T2I) generative models have shown remarkable capabilities in producing diverse and imaginative visuals based on text prompts. Despite the advancement, these diffusion models sometimes struggle to translate the semantic content from the text into images entirely. While conditioning on the layout has shown to be effective in improving the compositional ability of T2I diffusion models, they typically require manual layout input. In this work, we introduce a novel approach to improving T2I diffusion models using Large Language Models (LLMs) as layout generators. Our method leverages the Chain-of-Thought prompting of LLMs to interpret text and generate spatially reasonable object layouts. The generated layout is then used to enhance the generated images' composition and spatial accuracy. Moreover, we propose an efficient adapter based on a cross-attention mechanism, which explicitly integrates the layout information into the stable diffusion models. Our experiments demonstrate significant improvements in image quality and layout accuracy, showcasing the potential of LLMs in augmenting generative image models.
Bayesian Conditional Diffusion Models for Versatile Spatiotemporal Turbulence Generation
Nov 14, 2023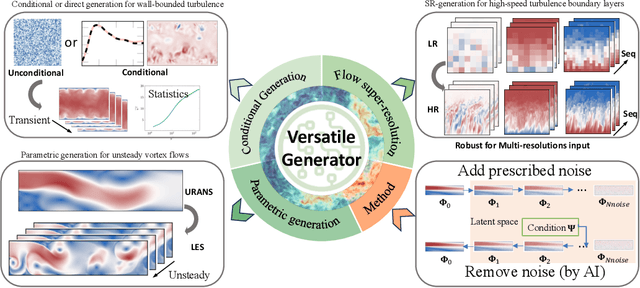


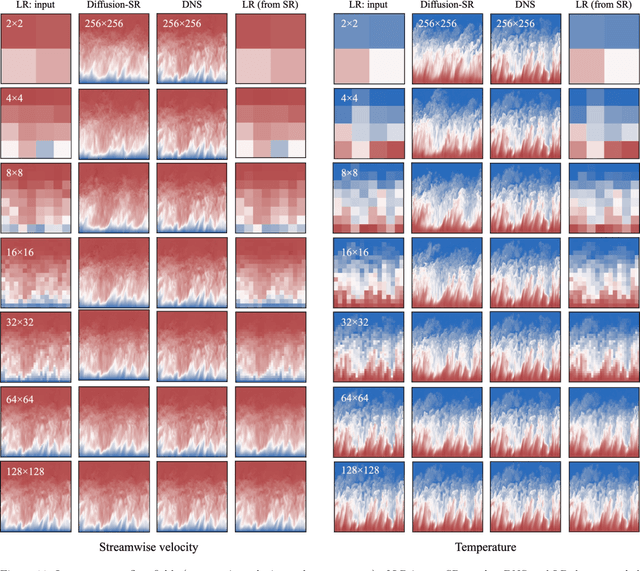
Turbulent flows have historically presented formidable challenges to predictive computational modeling. Traditional numerical simulations often require vast computational resources, making them infeasible for numerous engineering applications. As an alternative, deep learning-based surrogate models have emerged, offering data-drive solutions. However, these are typically constructed within deterministic settings, leading to shortfall in capturing the innate chaotic and stochastic behaviors of turbulent dynamics. We introduce a novel generative framework grounded in probabilistic diffusion models for versatile generation of spatiotemporal turbulence. Our method unifies both unconditional and conditional sampling strategies within a Bayesian framework, which can accommodate diverse conditioning scenarios, including those with a direct differentiable link between specified conditions and generated unsteady flow outcomes, and scenarios lacking such explicit correlations. A notable feature of our approach is the method proposed for long-span flow sequence generation, which is based on autoregressive gradient-based conditional sampling, eliminating the need for cumbersome retraining processes. We showcase the versatile turbulence generation capability of our framework through a suite of numerical experiments, including: 1) the synthesis of LES simulated instantaneous flow sequences from URANS inputs; 2) holistic generation of inhomogeneous, anisotropic wall-bounded turbulence, whether from given initial conditions, prescribed turbulence statistics, or entirely from scratch; 3) super-resolved generation of high-speed turbulent boundary layer flows from low-resolution data across a range of input resolutions. Collectively, our numerical experiments highlight the merit and transformative potential of the proposed methods, making a significant advance in the field of turbulence generation.
EDGE++: Improved Training and Sampling of EDGE
Oct 28, 2023



Recently developed deep neural models like NetGAN, CELL, and Variational Graph Autoencoders have made progress but face limitations in replicating key graph statistics on generating large graphs. Diffusion-based methods have emerged as promising alternatives, however, most of them present challenges in computational efficiency and generative performance. EDGE is effective at modeling large networks, but its current denoising approach can be inefficient, often leading to wasted computational resources and potential mismatches in its generation process. In this paper, we propose enhancements to the EDGE model to address these issues. Specifically, we introduce a degree-specific noise schedule that optimizes the number of active nodes at each timestep, significantly reducing memory consumption. Additionally, we present an improved sampling scheme that fine-tunes the generative process, allowing for better control over the similarity between the synthesized and the true network. Our experimental results demonstrate that the proposed modifications not only improve the efficiency but also enhance the accuracy of the generated graphs, offering a robust and scalable solution for graph generation tasks.
On Separate Normalization in Self-supervised Transformers
Sep 22, 2023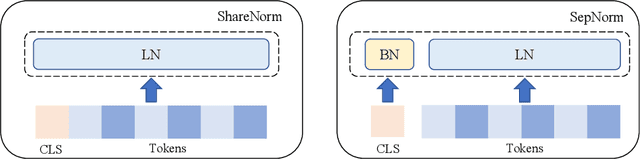

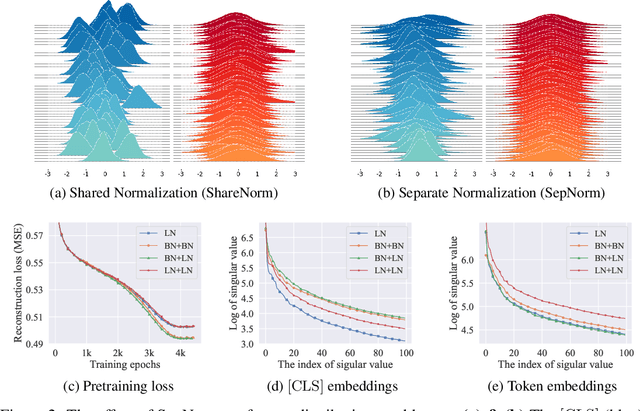
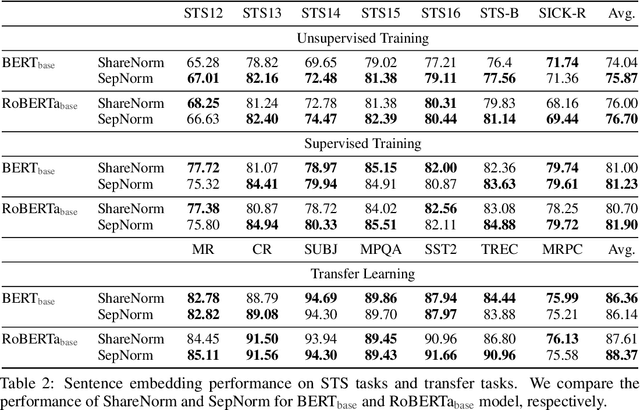
Self-supervised training methods for transformers have demonstrated remarkable performance across various domains. Previous transformer-based models, such as masked autoencoders (MAE), typically utilize a single normalization layer for both the [CLS] symbol and the tokens. We propose in this paper a simple modification that employs separate normalization layers for the tokens and the [CLS] symbol to better capture their distinct characteristics and enhance downstream task performance. Our method aims to alleviate the potential negative effects of using the same normalization statistics for both token types, which may not be optimally aligned with their individual roles. We empirically show that by utilizing a separate normalization layer, the [CLS] embeddings can better encode the global contextual information and are distributed more uniformly in its anisotropic space. When replacing the conventional normalization layer with the two separate layers, we observe an average 2.7% performance improvement over the image, natural language, and graph domains.