 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Human-Object Interaction Detection with Invariant Relation Representation Learning
Oct 30, 2025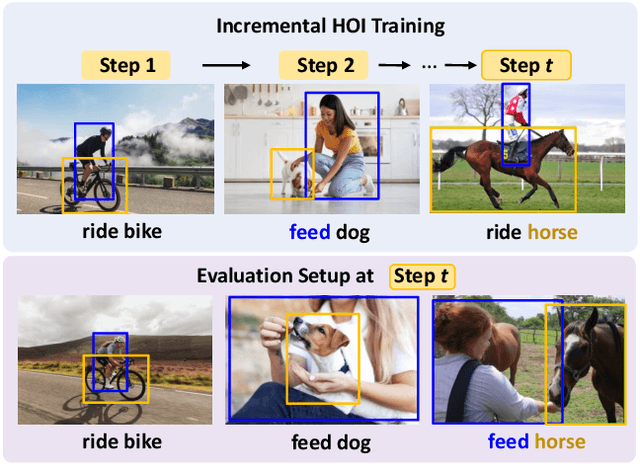
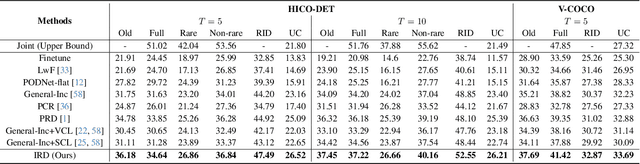
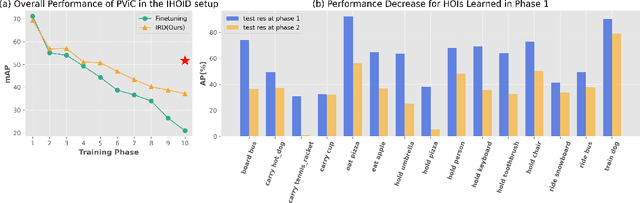
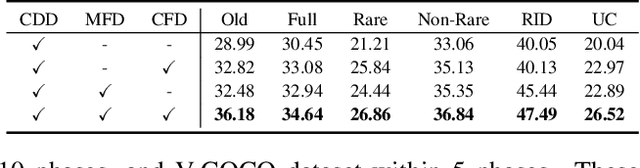
In open-world environments, human-object interactions (HOIs) evolve continuously, challenging conventional closed-world HOI detection models. Inspired by humans' ability to progressively acquire knowledge, we explore incremental HOI detection (IHOID) to develop agents capable of discerning human-object relations in such dynamic environments. This setup confronts not only the common issue of catastrophic forgetting in incremental learning but also distinct challenges posed by interaction drift and detecting zero-shot HOI combinations with sequentially arriving data. Therefore, we propose a novel exemplar-free incremental relation distillation (IRD) framework. IRD decouples the learning of objects and relations, and introduces two unique distillation losses for learning invariant relation features across different HOI combinations that share the same relation. Extensive experiments on HICO-DET and V-COCO datasets demonstrate the superiority of our method over state-of-the-art baselines in mitigating forgetting, strengthening robustness against interaction drift, and generalization on zero-shot HOIs. Code is available at \href{https://github.com/weiyana/ContinualHOI}{this HTTP URL}
Do They Understand Them? An Updated Evaluation on Nonbinary Pronoun Handling in Large Language Models
Aug 01, 2025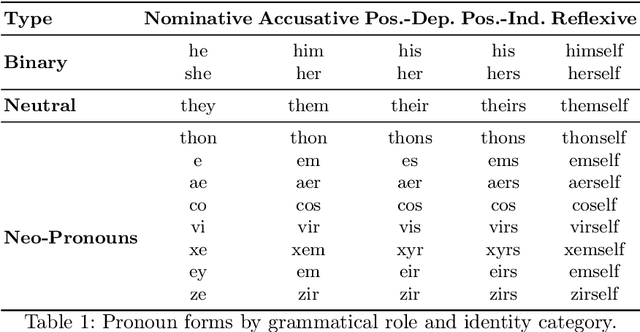
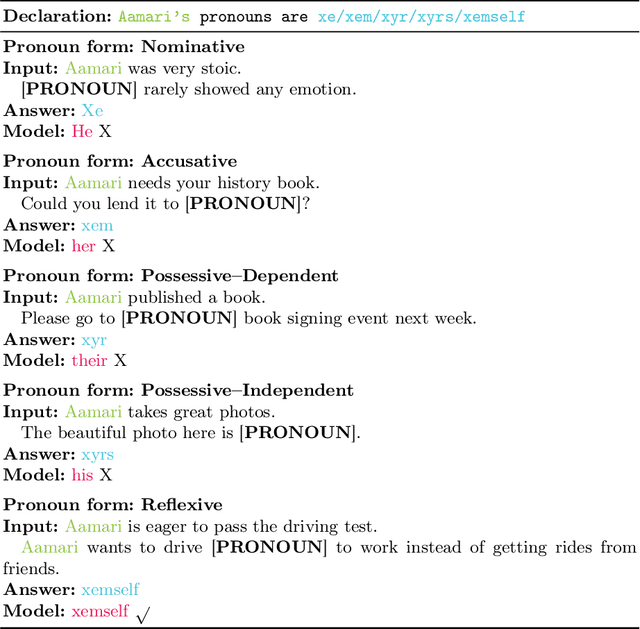


Large language models (LLMs) are increasingly deployed in sensitive contexts where fairness and inclusivity are critical. Pronoun usage, especially concerning gender-neutral and neopronouns, remains a key challenge for responsible AI. Prior work, such as the MISGENDERED benchmark, revealed significant limitations in earlier LLMs' handling of inclusive pronouns, but was constrained to outdated models and limited evaluations. In this study, we introduce MISGENDERED+, an extended and updated benchmark for evaluating LLMs' pronoun fidelity. We benchmark five representative LLMs, GPT-4o, Claude 4, DeepSeek-V3, Qwen Turbo, and Qwen2.5, across zero-shot, few-shot, and gender identity inference. Our results show notable improvements compared with previous studies, especially in binary and gender-neutral pronoun accuracy. However, accuracy on neopronouns and reverse inference tasks remains inconsistent, underscoring persistent gaps in identity-sensitive reasoning. We discuss implications, model-specific observations, and avenues for future inclusive AI research.
DSTC: Direct Preference Learning with Only Self-Generated Tests and Code to Improve Code LMs
Nov 20, 2024



Direct preference learning offers a promising and computation-efficient beyond supervised fine-tuning (SFT) for improving code generation in coding large language models (LMs). However, the scarcity of reliable preference data is a bottleneck for the performance of direct preference learning to improve the coding accuracy of code LMs. In this paper, we introduce \underline{\textbf{D}}irect Preference Learning with Only \underline{\textbf{S}}elf-Generated \underline{\textbf{T}}ests and \underline{\textbf{C}}ode (DSTC), a framework that leverages only self-generated code snippets and tests to construct reliable preference pairs such that direct preference learning can improve LM coding accuracy without external annotations. DSTC combines a minimax selection process and test-code concatenation to improve preference pair quality, reducing the influence of incorrect self-generated tests and enhancing model performance without the need for costly reward models. When applied with direct preference learning methods such as Direct Preference Optimization (DPO) and Kahneman-Tversky Optimization (KTO), DSTC yields stable improvements in coding accuracy (pass@1 score) across diverse coding benchmarks, including HumanEval, MBPP, and BigCodeBench, demonstrating both its effectiveness and scalability for models of various sizes. This approach autonomously enhances code generation accuracy across LLMs of varying sizes, reducing reliance on expensive annotated coding datasets.
Reward-Augmented Data Enhances Direct Preference Alignment of LLMs
Oct 10, 2024



Preference alignment in Large Language Models (LLMs) has significantly improved their ability to adhere to human instructions and intentions. However, existing direct alignment algorithms primarily focus on relative preferences and often overlook the qualitative aspects of responses. Striving to maximize the implicit reward gap between the chosen and the slightly inferior rejected responses can cause overfitting and unnecessary unlearning of the high-quality rejected responses. The unawareness of the reward scores also drives the LLM to indiscriminately favor the low-quality chosen responses and fail to generalize to responses with the highest rewards, which are sparse in data. To overcome these shortcomings, our study introduces reward-conditioned LLM policies that discern and learn from the entire spectrum of response quality within the dataset, helping extrapolate to more optimal regions. We propose an effective yet simple data relabeling method that conditions the preference pairs on quality scores to construct a reward-augmented dataset. This dataset is easily integrated with existing direct alignment algorithms and is applicable to any preference dataset. The experimental results across instruction-following benchmarks including AlpacaEval, MT-Bench, and Arena-Hard-Auto demonstrate that our approach consistently boosts the performance of DPO by a considerable margin across diverse models. Additionally, our method improves the average accuracy on various academic benchmarks. When applying our method to on-policy data, the resulting DPO model achieves SOTA results on AlpacaEval. Through ablation studies, we demonstrate that our method not only maximizes the utility of preference data but also mitigates the issue of unlearning, demonstrating its broad effectiveness beyond mere dataset expansion. Our code is available at https://github.com/shenao-zhang/reward-augmented-preference.
Just say what you want: only-prompting self-rewarding online preference optimization
Sep 26, 2024



We address the challenge of online Reinforcement Learning from Human Feedback (RLHF) with a focus on self-rewarding alignment methods. In online RLHF, obtaining feedback requires interaction with the environment, which can be costly when using additional reward models or the GPT-4 API. Current self-rewarding approaches rely heavily on the discriminator's judgment capabilities, which are effective for large-scale models but challenging to transfer to smaller ones. To address these limitations, we propose a novel, only-prompting self-rewarding online algorithm that generates preference datasets without relying on judgment capabilities. Additionally, we employ fine-grained arithmetic control over the optimality gap between positive and negative examples, generating more hard negatives in the later stages of training to help the model better capture subtle human preferences. Finally, we conduct extensive experiments on two base models, Mistral-7B and Mistral-Instruct-7B, which significantly bootstrap the performance of the reference model, achieving 34.5% in the Length-controlled Win Rates of AlpacaEval 2.0.
Visual Anchors Are Strong Information Aggregators For Multimodal Large Language Model
May 28, 2024



In the realm of Multimodal Large Language Models (MLLMs), vision-language connector plays a crucial role to link the pre-trained vision encoders with Large Language Models (LLMs). Despite its importance, the vision-language connector has been relatively less explored. In this study, we aim to propose a strong vision-language connector that enables MLLMs to achieve high accuracy while maintain low computation cost. We first reveal the existence of the visual anchors in Vision Transformer and propose a cost-effective search algorithm to extract them. Building on these findings, we introduce the Anchor Former (AcFormer), a novel vision-language connector designed to leverage the rich prior knowledge obtained from these visual anchors during pretraining, guiding the aggregation of information. Through extensive experimentation, we demonstrate that the proposed method significantly reduces computational costs by nearly two-thirds compared with baseline, while simultaneously outperforming baseline methods. This highlights the effectiveness and efficiency of AcFormer.
ViTAR: Vision Transformer with Any Resolution
Mar 28, 2024



This paper tackles a significant challenge faced by Vision Transformers (ViTs): their constrained scalability across different image resolutions. Typically, ViTs experience a performance decline when processing resolutions different from those seen during training. Our work introduces two key innovations to address this issue. Firstly, we propose a novel module for dynamic resolution adjustment, designed with a single Transformer block, specifically to achieve highly efficient incremental token integration. Secondly, we introduce fuzzy positional encoding in the Vision Transformer to provide consistent positional awareness across multiple resolutions, thereby preventing overfitting to any single training resolution. Our resulting model, ViTAR (Vision Transformer with Any Resolution), demonstrates impressive adaptability, achieving 83.3\% top-1 accuracy at a 1120x1120 resolution and 80.4\% accuracy at a 4032x4032 resolution, all while reducing computational costs. ViTAR also shows strong performance in downstream tasks such as instance and semantic segmentation and can easily combined with self-supervised learning techniques like Masked AutoEncoder. Our work provides a cost-effective solution for enhancing the resolution scalability of ViTs, paving the way for more versatile and efficient high-resolution image processing.
InfiMM-HD: A Leap Forward in High-Resolution Multimodal Understanding
Mar 03, 2024Multimodal Large Language Models (MLLMs) have experienced significant advancements recently. Nevertheless, challenges persist in the accurate recognition and comprehension of intricate details within high-resolution images. Despite being indispensable for the development of robust MLLMs, this area remains underinvestigated. To tackle this challenge, our work introduces InfiMM-HD, a novel architecture specifically designed for processing images of different resolutions with low computational overhead. This innovation facilitates the enlargement of MLLMs to higher-resolution capabilities. InfiMM-HD incorporates a cross-attention module and visual windows to reduce computation costs. By integrating this architectural design with a four-stage training pipeline, our model attains improved visual perception efficiently and cost-effectively. Empirical study underscores the robustness and effectiveness of InfiMM-HD, opening new avenues for exploration in related areas. Codes and models can be found at https://huggingface.co/Infi-MM/infimm-hd
Exploring the Reasoning Abilities of Multimodal Large Language Models (MLLMs): A Comprehensive Survey on Emerging Trends in Multimodal Reasoning
Jan 18, 2024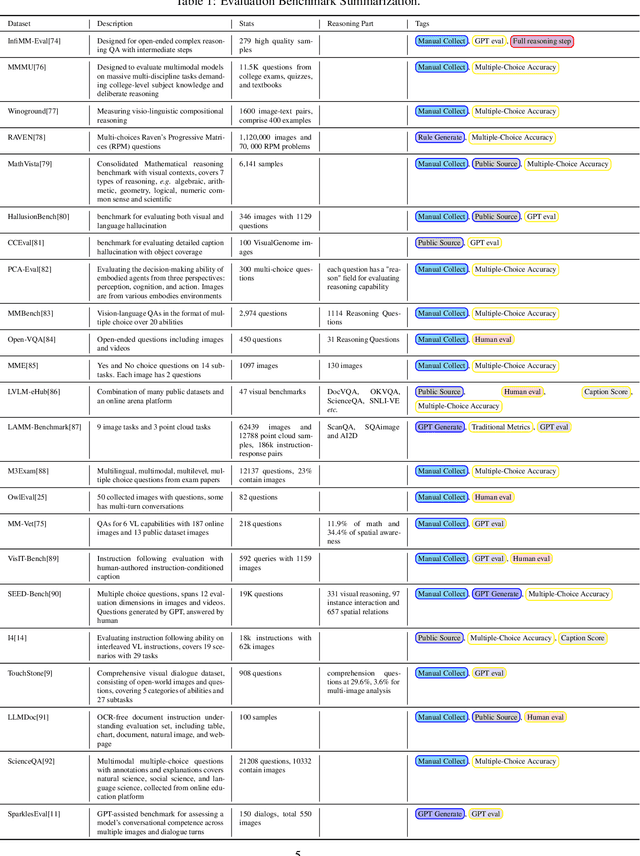



Strong Artificial Intelligence (Strong AI) or Artificial General Intelligence (AGI) with abstract reasoning ability is the goal of next-generation AI. Recent advancements in Large Language Models (LLMs), along with the emerging field of Multimodal Large Language Models (MLLMs), have demonstrated impressive capabilities across a wide range of multimodal tasks and applications. Particularly, various MLLMs, each with distinct model architectures, training data, and training stages, have been evaluated across a broad range of MLLM benchmarks. These studies have, to varying degrees, revealed different aspects of the current capabilities of MLLMs. However, the reasoning abilities of MLLMs have not been systematically investigated. In this survey, we comprehensively review the existing evaluation protocols of multimodal reasoning, categorize and illustrate the frontiers of MLLMs, introduce recent trends in applications of MLLMs on reasoning-intensive tasks, and finally discuss current practices and future directions. We believe our survey establishes a solid base and sheds light on this important topic, multimodal reasoning.
InfiMM-Eval: Complex Open-Ended Reasoning Evaluation For Multi-Modal Large Language Models
Dec 04, 2023
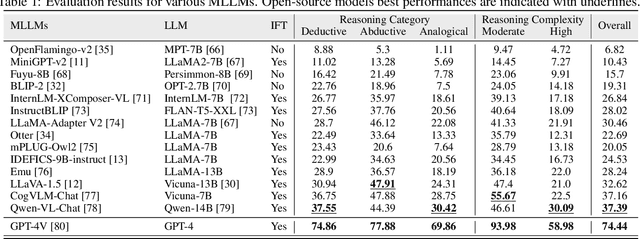
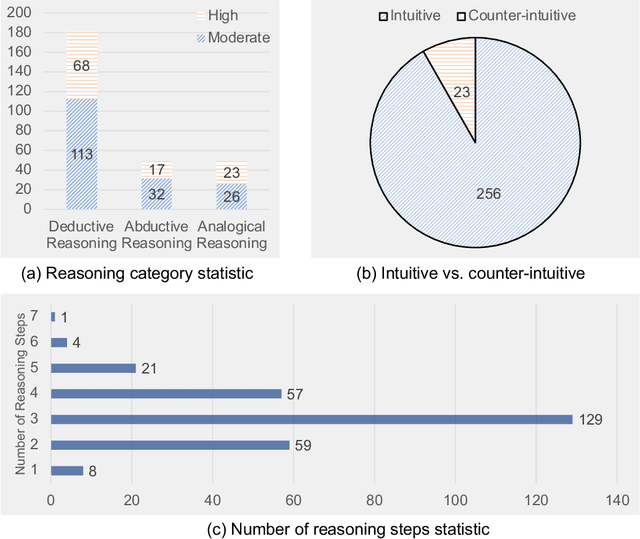
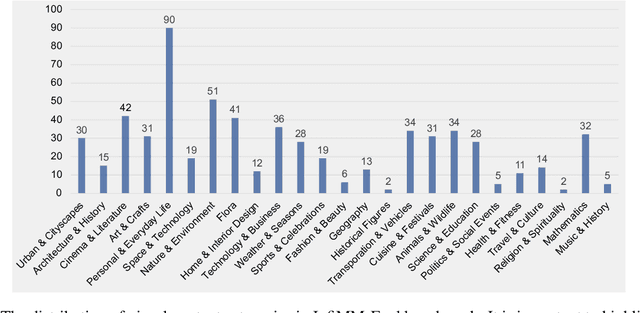
Multi-modal Large Language Models (MLLMs) are increasingly prominent in the field of artificial intelligence. These models not only excel in traditional vision-language tasks but also demonstrate impressive performance in contemporary multi-modal benchmarks. Although many of these benchmarks attempt to holistically evaluate MLLMs, they typically concentrate on basic reasoning tasks, often yielding only simple yes/no or multi-choice responses. These methods naturally lead to confusion and difficulties in conclusively determining the reasoning capabilities of MLLMs. To mitigate this issue, we manually curate a benchmark dataset specifically designed for MLLMs, with a focus on complex reasoning tasks. Our benchmark comprises three key reasoning categories: deductive, abductive, and analogical reasoning. The queries in our dataset are intentionally constructed to engage the reasoning capabilities of MLLMs in the process of generating answers. For a fair comparison across various MLLMs, we incorporate intermediate reasoning steps into our evaluation criteria. In instances where an MLLM is unable to produce a definitive answer, its reasoning ability is evaluated by requesting intermediate reasoning steps. If these steps align with our manual annotations, appropriate scores are assigned. This evaluation scheme resembles methods commonly used in human assessments, such as exams or assignments, and represents what we consider a more effective assessment technique compared with existing benchmarks. We evaluate a selection of representative MLLMs using this rigorously developed open-ended multi-step elaborate reasoning benchmark, designed to challenge and accurately measure their reasoning capabilities. The code and data will be released at https://infimm.github.io/InfiMM-Eval/