 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Human-Object Interaction Detection with Invariant Relation Representation Learning
Oct 30, 2025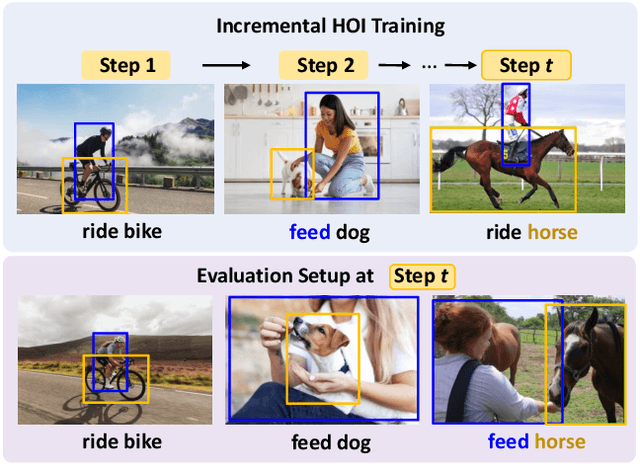
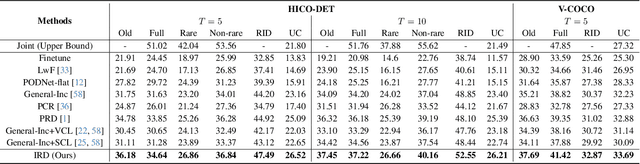
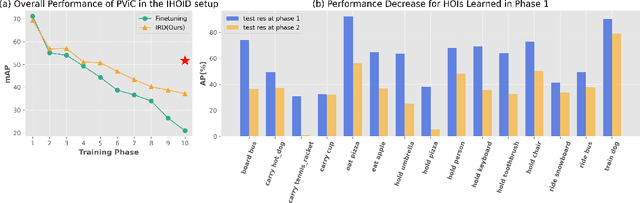
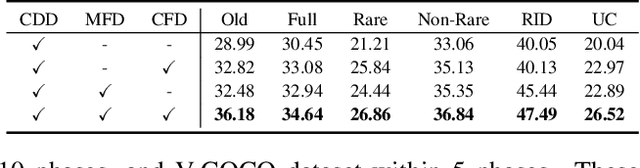
In open-world environments, human-object interactions (HOIs) evolve continuously, challenging conventional closed-world HOI detection models. Inspired by humans' ability to progressively acquire knowledge, we explore incremental HOI detection (IHOID) to develop agents capable of discerning human-object relations in such dynamic environments. This setup confronts not only the common issue of catastrophic forgetting in incremental learning but also distinct challenges posed by interaction drift and detecting zero-shot HOI combinations with sequentially arriving data. Therefore, we propose a novel exemplar-free incremental relation distillation (IRD) framework. IRD decouples the learning of objects and relations, and introduces two unique distillation losses for learning invariant relation features across different HOI combinations that share the same relation. Extensive experiments on HICO-DET and V-COCO datasets demonstrate the superiority of our method over state-of-the-art baselines in mitigating forgetting, strengthening robustness against interaction drift, and generalization on zero-shot HOIs. Code is available at \href{https://github.com/weiyana/ContinualHOI}{this HTTP URL}
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
Just say what you want: only-prompting self-rewarding online preference optimization
Sep 26, 2024



We address the challenge of online Reinforcement Learning from Human Feedback (RLHF) with a focus on self-rewarding alignment methods. In online RLHF, obtaining feedback requires interaction with the environment, which can be costly when using additional reward models or the GPT-4 API. Current self-rewarding approaches rely heavily on the discriminator's judgment capabilities, which are effective for large-scale models but challenging to transfer to smaller ones. To address these limitations, we propose a novel, only-prompting self-rewarding online algorithm that generates preference datasets without relying on judgment capabilities. Additionally, we employ fine-grained arithmetic control over the optimality gap between positive and negative examples, generating more hard negatives in the later stages of training to help the model better capture subtle human preferences. Finally, we conduct extensive experiments on two base models, Mistral-7B and Mistral-Instruct-7B, which significantly bootstrap the performance of the reference model, achieving 34.5% in the Length-controlled Win Rates of AlpacaEval 2.0.
MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs
Feb 23, 2024



We present the design, implementation and engineering experience in building and deploying MegaScale, a production system for training large language models (LLMs) at the scale of more than 10,000 GPUs. Training LLMs at this scale brings unprecedented challenges to training efficiency and stability. We take a full-stack approach that co-designs the algorithmic and system components across model block and optimizer design, computation and communication overlapping, operator optimization, data pipeline, and network performance tuning. Maintaining high efficiency throughout the training process (i.e., stability) is an important consideration in production given the long extent of LLM training jobs. Many hard stability issues only emerge at large scale, and in-depth observability is the key to address them. We develop a set of diagnosis tools to monitor system components and events deep in the stack, identify root causes, and derive effective techniques to achieve fault tolerance and mitigate stragglers. MegaScale achieves 55.2% Model FLOPs Utilization (MFU) when training a 175B LLM model on 12,288 GPUs, improving the MFU by 1.34x compared to Megatron-LM. We share our operational experience in identifying and fixing failures and stragglers. We hope by articulating the problems and sharing our experience from a systems perspective, this work can inspire future LLM systems research.
ATTA: Anomaly-aware Test-Time Adaptation for Out-of-Distribution Detection in Segmentation
Sep 12, 2023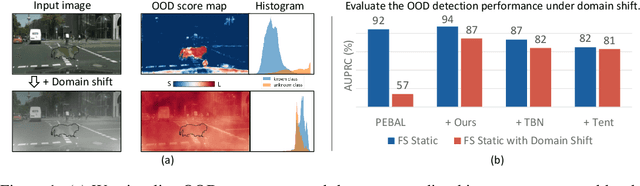

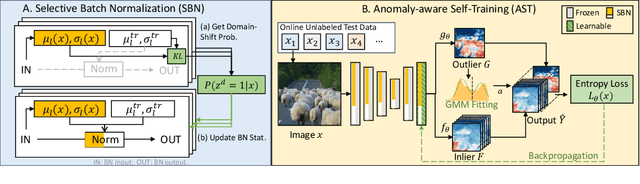
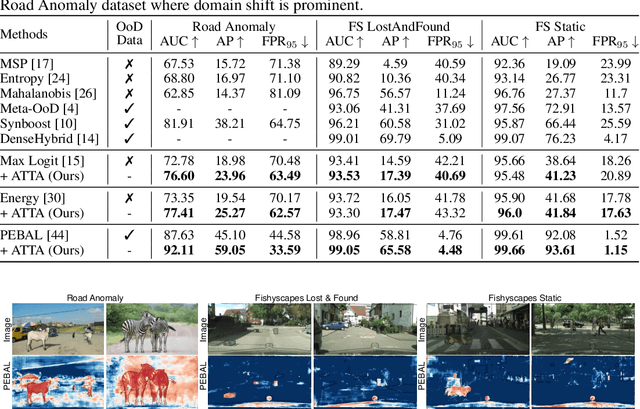
Recent advancements in dense out-of-distribution (OOD) detection have primarily focused on scenarios where the training and testing datasets share a similar domain, with the assumption that no domain shift exists between them. However, in real-world situations, domain shift often exits and significantly affects the accuracy of existing out-of-distribution (OOD) detection models. In this work, we propose a dual-level OOD detection framework to handle domain shift and semantic shift jointly. The first level distinguishes whether domain shift exists in the image by leveraging global low-level features, while the second level identifies pixels with semantic shift by utilizing dense high-level feature maps. In this way, we can selectively adapt the model to unseen domains as well as enhance model's capacity in detecting novel classes. We validate the efficacy of our proposed method on several OOD segmentation benchmarks, including those with significant domain shifts and those without, observing consistent performance improvements across various baseline models.
MILD: Modeling the Instance Learning Dynamics for Learning with Noisy Labels
Jun 20, 2023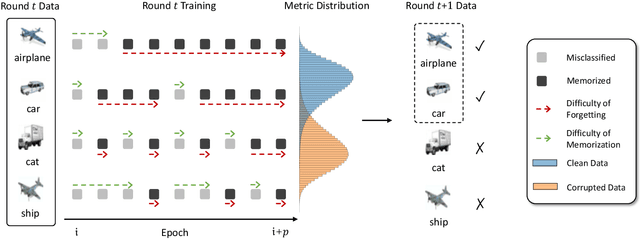
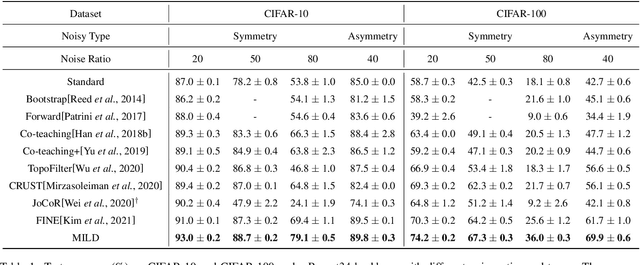

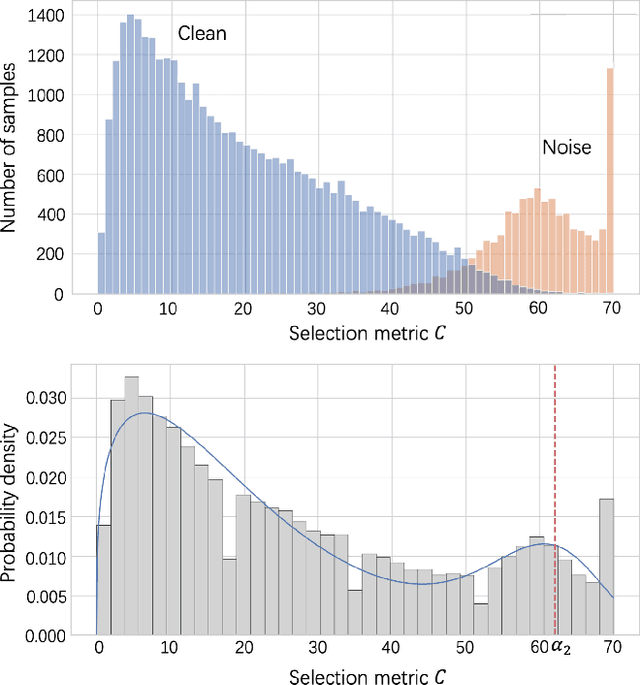
Despite deep learning has achieved great success, it often relies on a large amount of training data with accurate labels, which are expensive and time-consuming to collect. A prominent direction to reduce the cost is to learn with noisy labels, which are ubiquitous in the real-world applications. A critical challenge for such a learning task is to reduce the effect of network memorization on the falsely-labeled data. In this work, we propose an iterative selection approach based on the Weibull mixture model, which identifies clean data by considering the overall learning dynamics of each data instance. In contrast to the previous small-loss heuristics, we leverage the observation that deep network is easy to memorize and hard to forget clean data. In particular, we measure the difficulty of memorization and forgetting for each instance via the transition times between being misclassified and being memorized in training, and integrate them into a novel metric for selection. Based on the proposed metric, we retain a subset of identified clean data and repeat the selection procedure to iteratively refine the clean subset, which is finally used for model training. To validate our method, we perform extensive experiments on synthetic noisy datasets and real-world web data, and our strategy outperforms existing noisy-label learning methods.
Generative Negative Text Replay for Continual Vision-Language Pretraining
Oct 31, 2022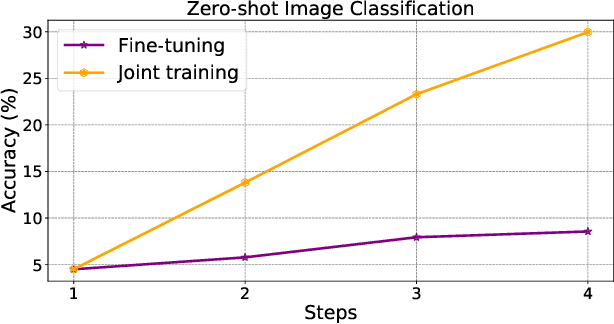
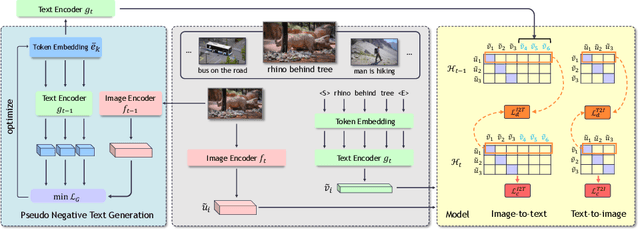
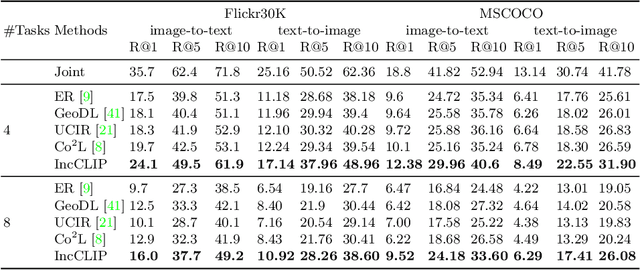
Vision-language pre-training (VLP) has attracted increasing attention recently. With a large amount of image-text pairs, VLP models trained with contrastive loss have achieved impressive performance in various tasks, especially the zero-shot generalization on downstream datasets. In practical applications, however, massive data are usually collected in a streaming fashion, requiring VLP models to continuously integrate novel knowledge from incoming data and retain learned knowledge. In this work, we focus on learning a VLP model with sequential chunks of image-text pair data. To tackle the catastrophic forgetting issue in this multi-modal continual learning setting, we first introduce pseudo text replay that generates hard negative texts conditioned on the training images in memory, which not only better preserves learned knowledge but also improves the diversity of negative samples in the contrastive loss. Moreover, we propose multi-modal knowledge distillation between images and texts to align the instance-wise prediction between old and new models. We incrementally pre-train our model on both the instance and class incremental splits of the Conceptual Caption dataset, and evaluate the model on zero-shot image classification and image-text retrieval tasks. Our method consistently outperforms the existing baselines with a large margin, which demonstrates its superiority. Notably, we realize an average performance boost of $4.60\%$ on image-classification downstream datasets for the class incremental split.
General Incremental Learning with Domain-aware Categorical Representations
Apr 08, 2022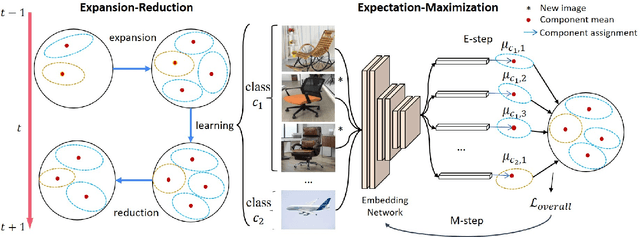
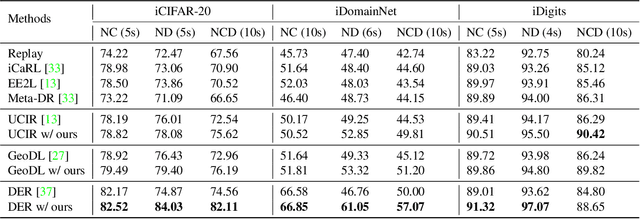
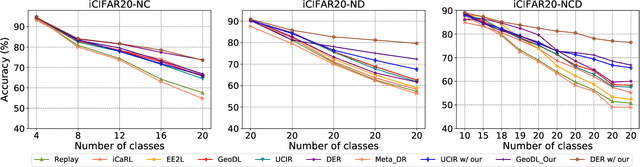

Continual learning is an important problem for achieving human-level intelligence in real-world applications as an agent must continuously accumulate knowledge in response to streaming data/tasks. In this work, we consider a general and yet under-explored incremental learning problem in which both the class distribution and class-specific domain distribution change over time. In addition to the typical challenges in class incremental learning, this setting also faces the intra-class stability-plasticity dilemma and intra-class domain imbalance problems. To address above issues, we develop a novel domain-aware continual learning method based on the EM framework. Specifically, we introduce a flexible class representation based on the von Mises-Fisher mixture model to capture the intra-class structure, using an expansion-and-reduction strategy to dynamically increase the number of components according to the class complexity. Moreover, we design a bi-level balanced memory to cope with data imbalances within and across classes, which combines with a distillation loss to achieve better inter- and intra-class stability-plasticity trade-off. We conduct exhaustive experiments on three benchmarks: iDigits, iDomainNet and iCIFAR-20. The results show that our approach consistently outperforms previous methods by a significant margin, demonstrating its superiority.
Budget-aware Few-shot Learning via Graph Convolutional Network
Jan 07, 2022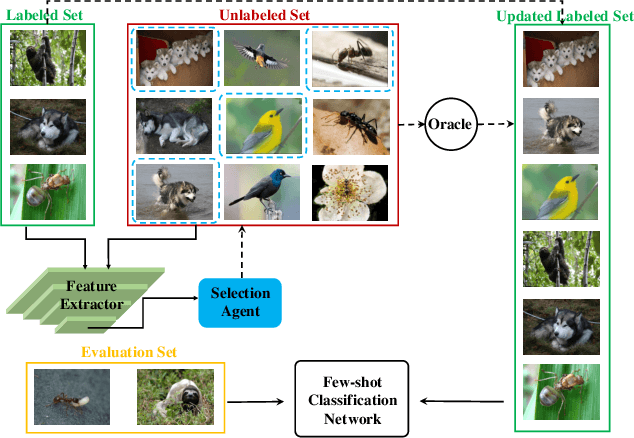
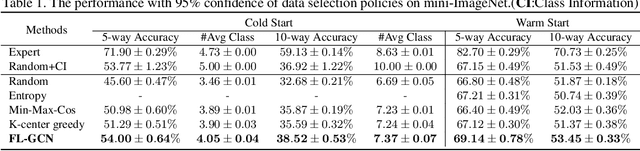
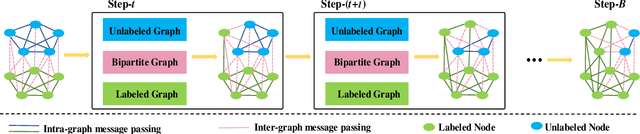
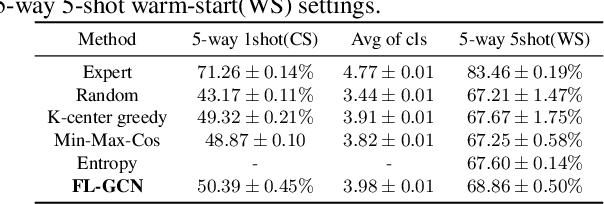
This paper tackles the problem of few-shot learning, which aims to learn new visual concepts from a few examples. A common problem setting in few-shot classification assumes random sampling strategy in acquiring data labels, which is inefficient in practical applications. In this work, we introduce a new budget-aware few-shot learning problem that not only aims to learn novel object categories, but also needs to select informative examples to annotate in order to achieve data efficiency. We develop a meta-learning strategy for our budget-aware few-shot learning task, which jointly learns a novel data selection policy based on a Graph Convolutional Network (GCN) and an example-based few-shot classifier. Our selection policy computes a context-sensitive representation for each unlabeled data by graph message passing, which is then used to predict an informativeness score for sequential selection. We validate our method by extensive experiments on the mini-ImageNet, tiered-ImageNet and Omniglot datasets. The results show our few-shot learning strategy outperforms baselines by a sizable margin, which demonstrates the efficacy of our method.
An EM Framework for Online Incremental Learning of Semantic Segmentation
Aug 08, 2021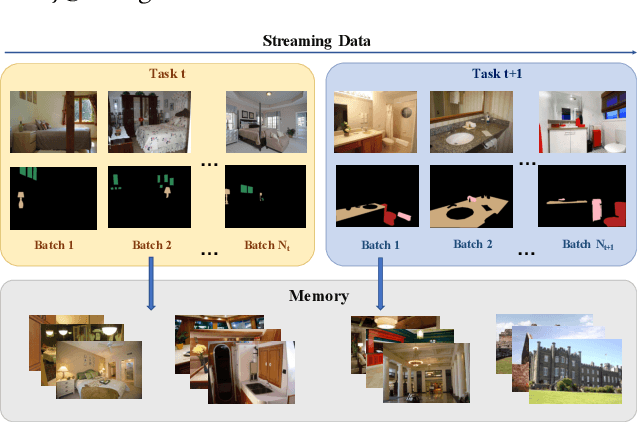
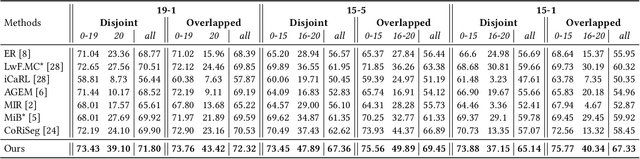
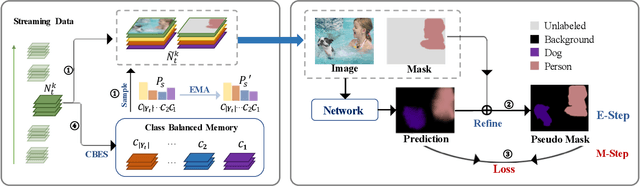
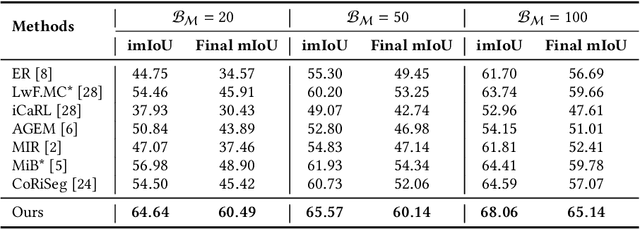
Incremental learning of semantic segmentation has emerged as a promising strategy for visual scene interpretation in the open- world setting. However, it remains challenging to acquire novel classes in an online fashion for the segmentation task, mainly due to its continuously-evolving semantic label space, partial pixelwise ground-truth annotations, and constrained data availability. To ad- dress this, we propose an incremental learning strategy that can fast adapt deep segmentation models without catastrophic forgetting, using a streaming input data with pixel annotations on the novel classes only. To this end, we develop a uni ed learning strategy based on the Expectation-Maximization (EM) framework, which integrates an iterative relabeling strategy that lls in the missing labels and a rehearsal-based incremental learning step that balances the stability-plasticity of the model. Moreover, our EM algorithm adopts an adaptive sampling method to select informative train- ing data and a class-balancing training strategy in the incremental model updates, both improving the e cacy of model learning. We validate our approach on the PASCAL VOC 2012 and ADE20K datasets, and the results demonstrate its superior performance over the existing incremental methods.