 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge (Vision) Language Models are Unsupervised In-Context Learners
Apr 03, 2025Recent advances in large language and vision-language models have enabled zero-shot inference, allowing models to solve new tasks without task-specific training. Various adaptation techniques such as prompt engineering, In-Context Learning (ICL), and supervised fine-tuning can further enhance the model's performance on a downstream task, but they require substantial manual effort to construct effective prompts or labeled examples. In this work, we introduce a joint inference framework for fully unsupervised adaptation, eliminating the need for manual prompt engineering and labeled examples. Unlike zero-shot inference, which makes independent predictions, the joint inference makes predictions simultaneously for all inputs in a given task. Since direct joint inference involves computationally expensive optimization, we develop efficient approximation techniques, leading to two unsupervised adaptation methods: unsupervised fine-tuning and unsupervised ICL. We demonstrate the effectiveness of our methods across diverse tasks and models, including language-only Llama-3.1 on natural language processing tasks, reasoning-oriented Qwen2.5-Math on grade school math problems, vision-language OpenFlamingo on vision tasks, and the API-only access GPT-4o model on massive multi-discipline tasks. Our experiments demonstrate substantial improvements over the standard zero-shot approach, including 39% absolute improvement on the challenging GSM8K math reasoning dataset. Remarkably, despite being fully unsupervised, our framework often performs on par with supervised approaches that rely on ground truth labels.
Generalize or Detect? Towards Robust Semantic Segmentation Under Multiple Distribution Shifts
Nov 06, 2024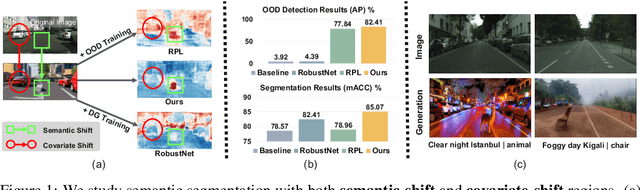
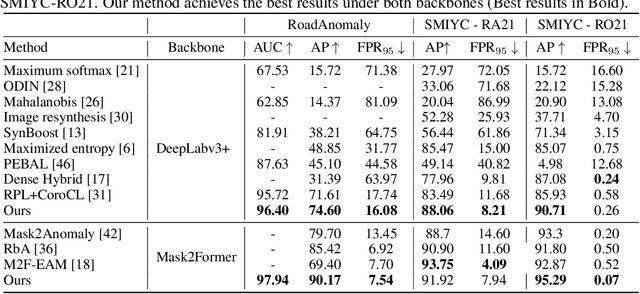
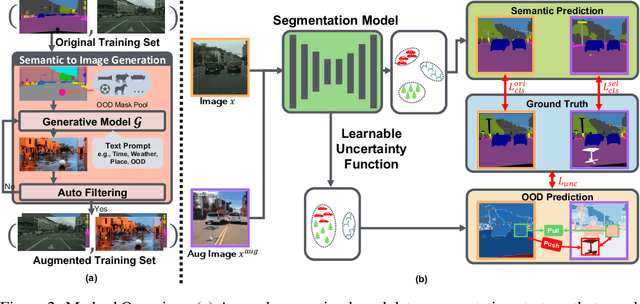
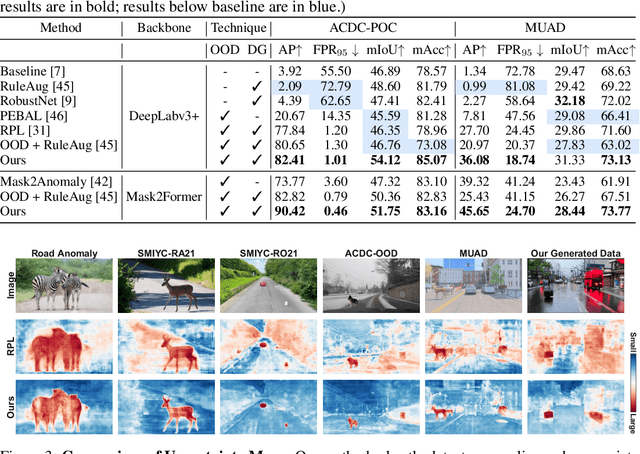
In open-world scenarios, where both novel classes and domains may exist, an ideal segmentation model should detect anomaly classes for safety and generalize to new domains. However, existing methods often struggle to distinguish between domain-level and semantic-level distribution shifts, leading to poor out-of-distribution (OOD) detection or domain generalization performance. In this work, we aim to equip the model to generalize effectively to covariate-shift regions while precisely identifying semantic-shift regions. To achieve this, we design a novel generative augmentation method to produce coherent images that incorporate both anomaly (or novel) objects and various covariate shifts at both image and object levels. Furthermore, we introduce a training strategy that recalibrates uncertainty specifically for semantic shifts and enhances the feature extractor to align features associated with domain shifts. We validate the effectiveness of our method across benchmarks featuring both semantic and domain shifts. Our method achieves state-of-the-art performance across all benchmarks for both OOD detection and domain generalization. Code is available at https://github.com/gaozhitong/MultiShiftSeg.
Gradient-Map-Guided Adaptive Domain Generalization for Cross Modality MRI Segmentation
Nov 16, 2023Cross-modal MRI segmentation is of great value for computer-aided medical diagnosis, enabling flexible data acquisition and model generalization. However, most existing methods have difficulty in handling local variations in domain shift and typically require a significant amount of data for training, which hinders their usage in practice. To address these problems, we propose a novel adaptive domain generalization framework, which integrates a learning-free cross-domain representation based on image gradient maps and a class prior-informed test-time adaptation strategy for mitigating local domain shift. We validate our approach on two multi-modal MRI datasets with six cross-modal segmentation tasks. Across all the task settings, our method consistently outperforms competing approaches and shows a stable performance even with limited training data.
The Robust Semantic Segmentation UNCV2023 Challenge Results
Sep 27, 2023



This paper outlines the winning solutions employed in addressing the MUAD uncertainty quantification challenge held at ICCV 2023. The challenge was centered around semantic segmentation in urban environments, with a particular focus on natural adversarial scenarios. The report presents the results of 19 submitted entries, with numerous techniques drawing inspiration from cutting-edge uncertainty quantification methodologies presented at prominent conferences in the fields of computer vision and machine learning and journals over the past few years. Within this document, the challenge is introduced, shedding light on its purpose and objectives, which primarily revolved around enhancing the robustness of semantic segmentation in urban scenes under varying natural adversarial conditions. The report then delves into the top-performing solutions. Moreover, the document aims to provide a comprehensive overview of the diverse solutions deployed by all participants. By doing so, it seeks to offer readers a deeper insight into the array of strategies that can be leveraged to effectively handle the inherent uncertainties associated with autonomous driving and semantic segmentation, especially within urban environments.
ATTA: Anomaly-aware Test-Time Adaptation for Out-of-Distribution Detection in Segmentation
Sep 12, 2023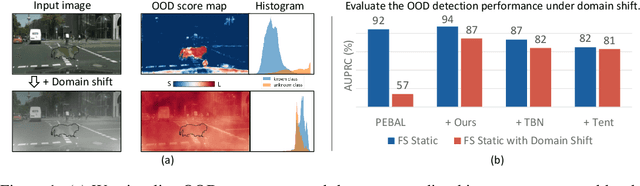

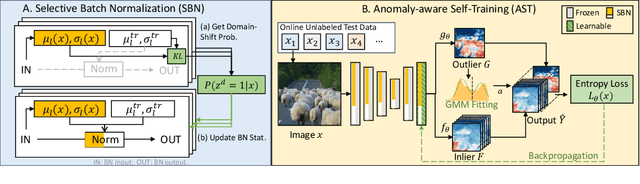
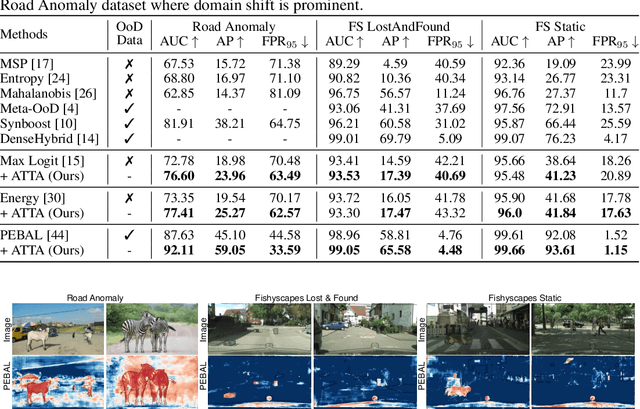
Recent advancements in dense out-of-distribution (OOD) detection have primarily focused on scenarios where the training and testing datasets share a similar domain, with the assumption that no domain shift exists between them. However, in real-world situations, domain shift often exits and significantly affects the accuracy of existing out-of-distribution (OOD) detection models. In this work, we propose a dual-level OOD detection framework to handle domain shift and semantic shift jointly. The first level distinguishes whether domain shift exists in the image by leveraging global low-level features, while the second level identifies pixels with semantic shift by utilizing dense high-level feature maps. In this way, we can selectively adapt the model to unseen domains as well as enhance model's capacity in detecting novel classes. We validate the efficacy of our proposed method on several OOD segmentation benchmarks, including those with significant domain shifts and those without, observing consistent performance improvements across various baseline models.
MILD: Modeling the Instance Learning Dynamics for Learning with Noisy Labels
Jun 20, 2023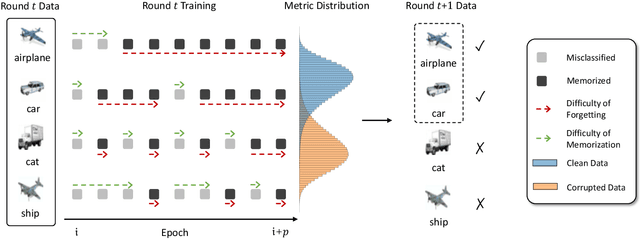
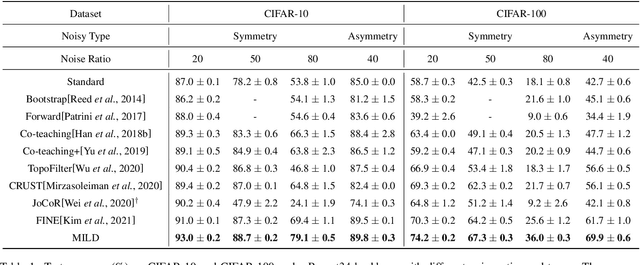

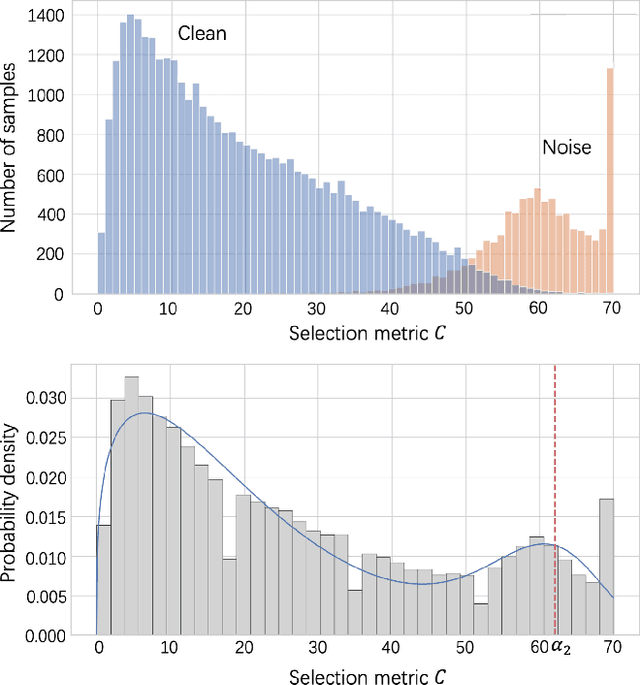
Despite deep learning has achieved great success, it often relies on a large amount of training data with accurate labels, which are expensive and time-consuming to collect. A prominent direction to reduce the cost is to learn with noisy labels, which are ubiquitous in the real-world applications. A critical challenge for such a learning task is to reduce the effect of network memorization on the falsely-labeled data. In this work, we propose an iterative selection approach based on the Weibull mixture model, which identifies clean data by considering the overall learning dynamics of each data instance. In contrast to the previous small-loss heuristics, we leverage the observation that deep network is easy to memorize and hard to forget clean data. In particular, we measure the difficulty of memorization and forgetting for each instance via the transition times between being misclassified and being memorized in training, and integrate them into a novel metric for selection. Based on the proposed metric, we retain a subset of identified clean data and repeat the selection procedure to iteratively refine the clean subset, which is finally used for model training. To validate our method, we perform extensive experiments on synthetic noisy datasets and real-world web data, and our strategy outperforms existing noisy-label learning methods.
Modeling Multimodal Aleatoric Uncertainty in Segmentation with Mixture of Stochastic Expert
Dec 14, 2022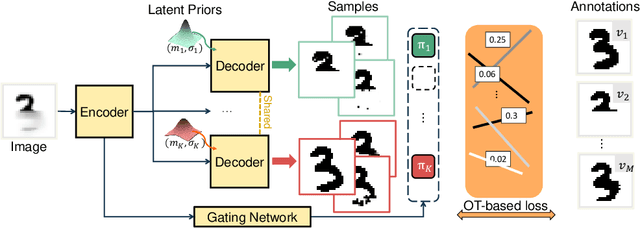

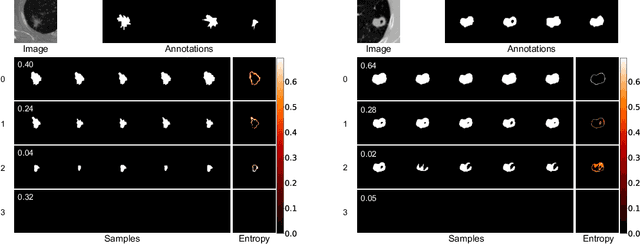

Equipping predicted segmentation with calibrated uncertainty is essential for safety-critical applications. In this work, we focus on capturing the data-inherent uncertainty (aka aleatoric uncertainty) in segmentation, typically when ambiguities exist in input images. Due to the high-dimensional output space and potential multiple modes in segmenting ambiguous images, it remains challenging to predict well-calibrated uncertainty for segmentation. To tackle this problem, we propose a novel mixture of stochastic experts (MoSE) model, where each expert network estimates a distinct mode of the aleatoric uncertainty and a gating network predicts the probabilities of an input image being segmented in those modes. This yields an efficient two-level uncertainty representation. To learn the model, we develop a Wasserstein-like loss that directly minimizes the distribution distance between the MoSE and ground truth annotations. The loss can easily integrate traditional segmentation quality measures and be efficiently optimized via constraint relaxation. We validate our method on the LIDC-IDRI dataset and a modified multimodal Cityscapes dataset. Results demonstrate that our method achieves the state-of-the-art or competitive performance on all metrics.
Mutual Information-guided Knowledge Transfer for Novel Class Discovery
Jun 24, 2022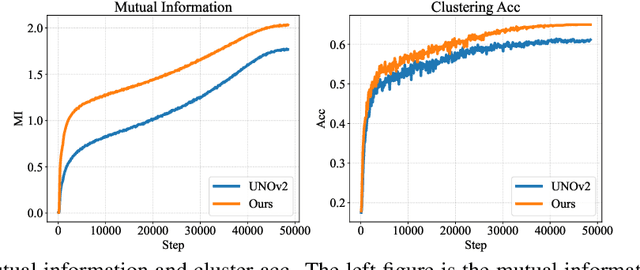
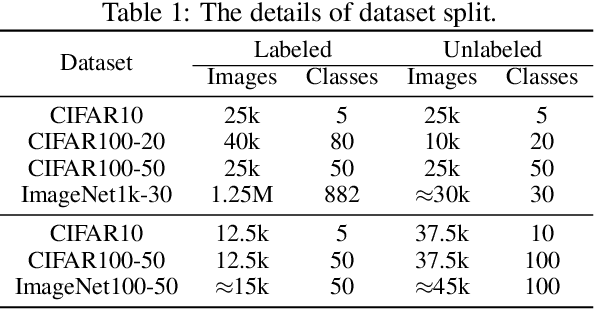
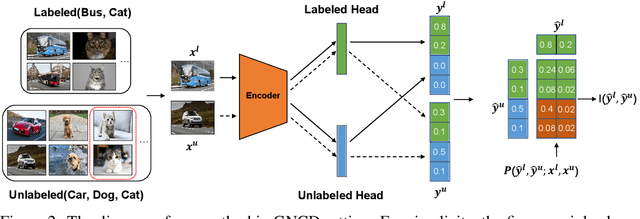
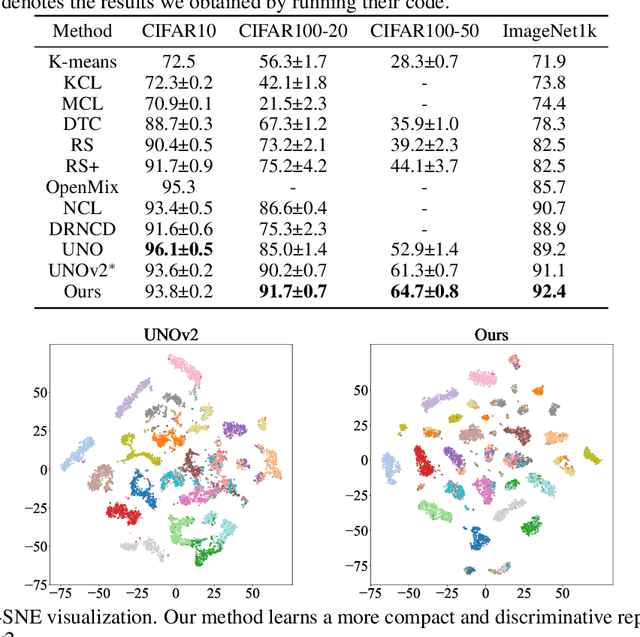
We tackle the novel class discovery problem, aiming to discover novel classes in unlabeled data based on labeled data from seen classes. The main challenge is to transfer knowledge contained in the seen classes to unseen ones. Previous methods mostly transfer knowledge through sharing representation space or joint label space. However, they tend to neglect the class relation between seen and unseen categories, and thus the learned representations are less effective for clustering unseen classes. In this paper, we propose a principle and general method to transfer semantic knowledge between seen and unseen classes. Our insight is to utilize mutual information to measure the relation between seen classes and unseen classes in a restricted label space and maximizing mutual information promotes transferring semantic knowledge. To validate the effectiveness and generalization of our method, we conduct extensive experiments both on novel class discovery and general novel class discovery settings. Our results show that the proposed method outperforms previous SOTA by a significant margin on several benchmarks.
Superpixel-guided Iterative Learning from Noisy Labels for Medical Image Segmentation
Jul 21, 2021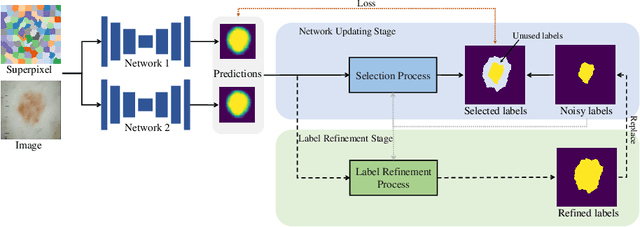


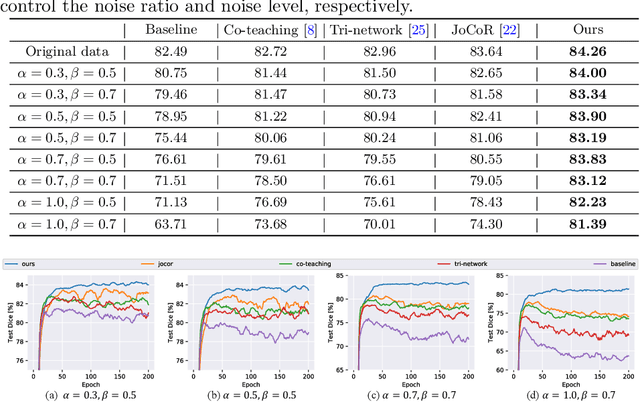
Learning segmentation from noisy labels is an important task for medical image analysis due to the difficulty in acquiring highquality annotations. Most existing methods neglect the pixel correlation and structural prior in segmentation, often producing noisy predictions around object boundaries. To address this, we adopt a superpixel representation and develop a robust iterative learning strategy that combines noise-aware training of segmentation network and noisy label refinement, both guided by the superpixels. This design enables us to exploit the structural constraints in segmentation labels and effectively mitigate the impact of label noise in learning. Experiments on two benchmarks show that our method outperforms recent state-of-the-art approaches, and achieves superior robustness in a wide range of label noises. Code is available at https://github.com/gaozhitong/SP_guided_Noisy_Label_Seg.