 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLM-Eval: A General Evaluation on Video Large Language Models
Nov 20, 2023


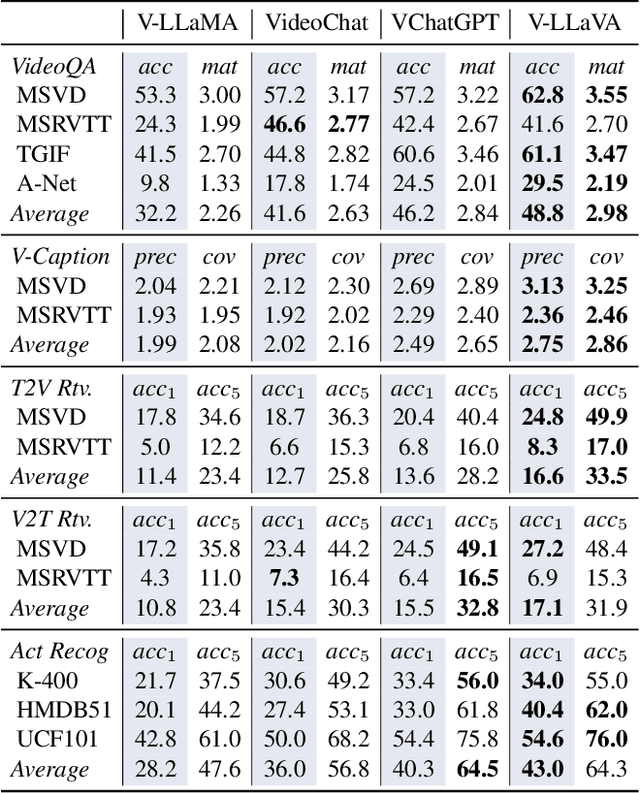
Despite the rapid development of video Large Language Models (LLMs), a comprehensive evaluation is still absent. In this paper, we introduce a unified evaluation that encompasses multiple video tasks, including captioning, question and answering, retrieval, and action recognition. In addition to conventional metrics, we showcase how GPT-based evaluation can match human-like performance in assessing response quality across multiple aspects. We propose a simple baseline: Video-LLaVA, which uses a single linear projection and outperforms existing video LLMs. Finally, we evaluate video LLMs beyond academic datasets, which show encouraging recognition and reasoning capabilities in driving scenarios with only hundreds of video-instruction pairs for fine-tuning. We hope our work can serve as a unified evaluation for video LLMs, and help expand more practical scenarios. The evaluation code will be available soon.
Far3D: Expanding the Horizon for Surround-view 3D Object Detection
Aug 18, 2023
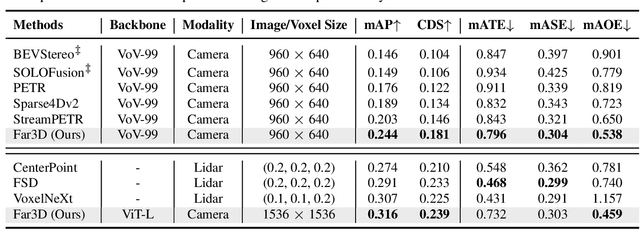
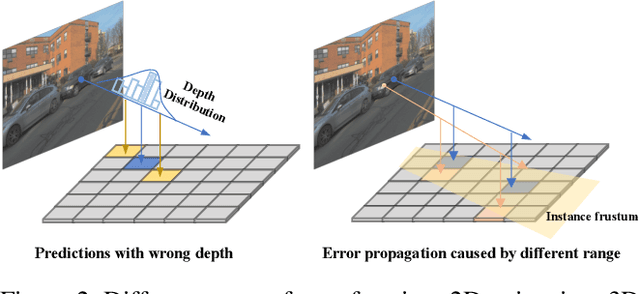
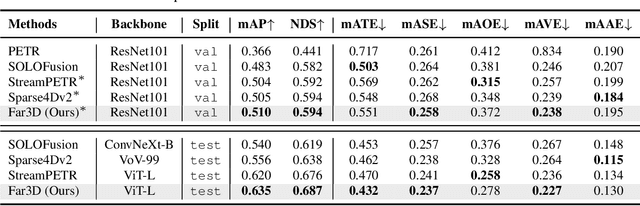
Recently 3D object detection from surround-view images has made notable advancements with its low deployment cost. However, most works have primarily focused on close perception range while leaving long-range detection less explored. Expanding existing methods directly to cover long distances poses challenges such as heavy computation costs and unstable convergence. To address these limitations, this paper proposes a novel sparse query-based framework, dubbed Far3D. By utilizing high-quality 2D object priors, we generate 3D adaptive queries that complement the 3D global queries. To efficiently capture discriminative features across different views and scales for long-range objects, we introduce a perspective-aware aggregation module. Additionally, we propose a range-modulated 3D denoising approach to address query error propagation and mitigate convergence issues in long-range tasks. Significantly, Far3D demonstrates SoTA performance on the challenging Argoverse 2 dataset, covering a wide range of 150 meters, surpassing several LiDAR-based approaches. Meanwhile, Far3D exhibits superior performance compared to previous methods on the nuScenes dataset. The code will be available soon.
The 1st-place Solution for CVPR 2023 OpenLane Topology in Autonomous Driving Challenge
Jun 16, 2023We present the 1st-place solution of OpenLane Topology in Autonomous Driving Challenge. Considering that topology reasoning is based on centerline detection and traffic element detection, we develop a multi-stage framework for high performance. Specifically, the centerline is detected by the powerful PETRv2 detector and the popular YOLOv8 is employed to detect the traffic elements. Further, we design a simple yet effective MLP-based head for topology prediction. Our method achieves 55\% OLS on the OpenLaneV2 test set, surpassing the 2nd solution by 8 points.
Cross Modal Transformer via Coordinates Encoding for 3D Object Dectection
Jan 03, 2023In this paper, we propose a robust 3D detector, named Cross Modal Transformer (CMT), for end-to-end 3D multi-modal detection. Without explicit view transformation, CMT takes the image and point clouds tokens as inputs and directly outputs accurate 3D bounding boxes. The spatial alignment of multi-modal tokens is performed implicitly, by encoding the 3D points into multi-modal features. The core design of CMT is quite simple while its performance is impressive. CMT obtains 73.0% NDS on nuScenes benchmark. Moreover, CMT has a strong robustness even if the LiDAR is missing. Code will be released at https://github.com/junjie18/CMT.
PETRv2: A Unified Framework for 3D Perception from Multi-Camera Images
Jun 02, 2022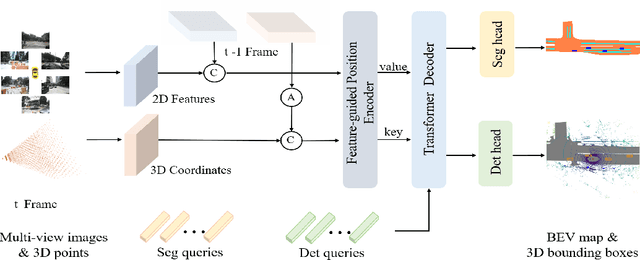
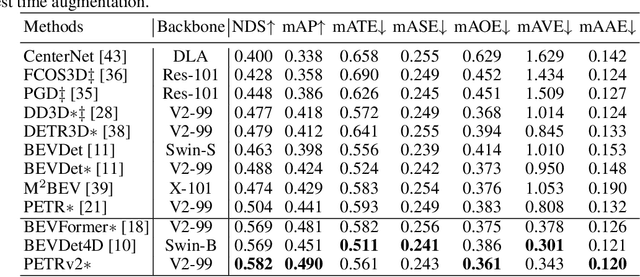
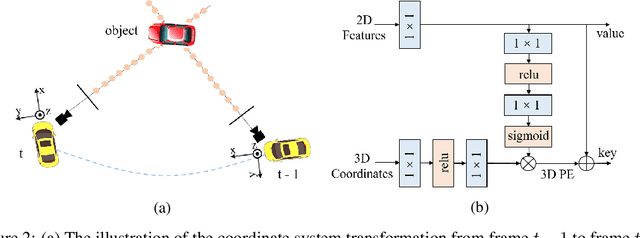
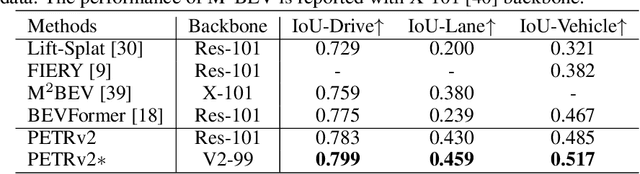
In this paper, we propose PETRv2, a unified framework for 3D perception from multi-view images. Based on PETR, PETRv2 explores the effectiveness of temporal modeling, which utilizes the temporal information of previous frames to boost 3D object detection. More specifically, we extend the 3D position embedding (3D PE) in PETR for temporal modeling. The 3D PE achieves the temporal alignment on object position of different frames. A feature-guided position encoder is further introduced to improve the data adaptability of 3D PE. To support for high-quality BEV segmentation, PETRv2 provides a simply yet effective solution by adding a set of segmentation queries. Each segmentation query is responsible for segmenting one specific patch of BEV map. PETRv2 achieves state-of-the-art performance on 3D object detection and BEV segmentation. Detailed robustness analysis is also conducted on PETR framework. We hope PETRv2 can serve as a unified framework for 3D perception.
Superpixel-guided Iterative Learning from Noisy Labels for Medical Image Segmentation
Jul 21, 2021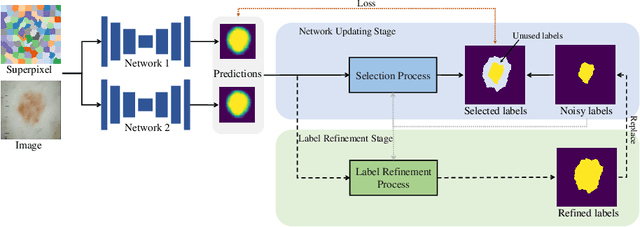


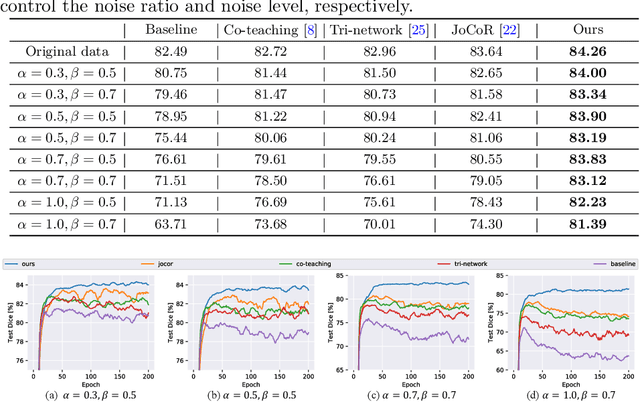
Learning segmentation from noisy labels is an important task for medical image analysis due to the difficulty in acquiring highquality annotations. Most existing methods neglect the pixel correlation and structural prior in segmentation, often producing noisy predictions around object boundaries. To address this, we adopt a superpixel representation and develop a robust iterative learning strategy that combines noise-aware training of segmentation network and noisy label refinement, both guided by the superpixels. This design enables us to exploit the structural constraints in segmentation labels and effectively mitigate the impact of label noise in learning. Experiments on two benchmarks show that our method outperforms recent state-of-the-art approaches, and achieves superior robustness in a wide range of label noises. Code is available at https://github.com/gaozhitong/SP_guided_Noisy_Label_Seg.
Weakly Supervised Volumetric Segmentation via Self-taught Shape Denoising Model
May 06, 2021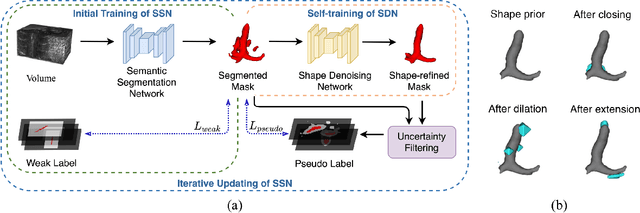
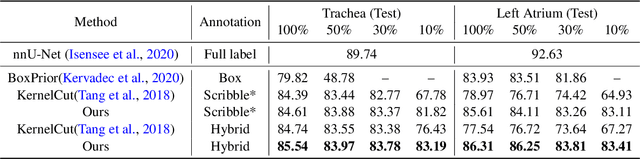


Weakly supervised segmentation is an important problem in medical image analysis due to the high cost of pixelwise annotation. Prior methods, while often focusing on weak labels of 2D images, exploit few structural cues of volumetric medical images. To address this, we propose a novel weakly-supervised segmentation strategy capable of better capturing 3D shape prior in both model prediction and learning. Our main idea is to extract a self-taught shape representation by leveraging weak labels, and then integrate this representation into segmentation prediction for shape refinement. To this end, we design a deep network consisting of a segmentation module and a shape denoising module, which are trained by an iterative learning strategy. Moreover, we introduce a weak annotation scheme with a hybrid label design for volumetric images, which improves model learning without increasing the overall annotation cost. The empirical experiments show that our approach outperforms existing SOTA strategies on three organ segmentation benchmarks with distinctive shape properties. Notably, we can achieve strong performance with even 10\% labeled slices, which is significantly superior to other methods.
Shape-aware Semi-supervised 3D Semantic Segmentation for Medical Images
Jul 21, 2020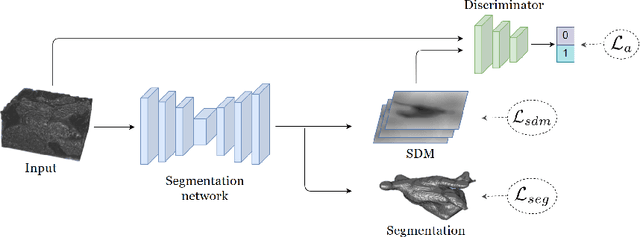
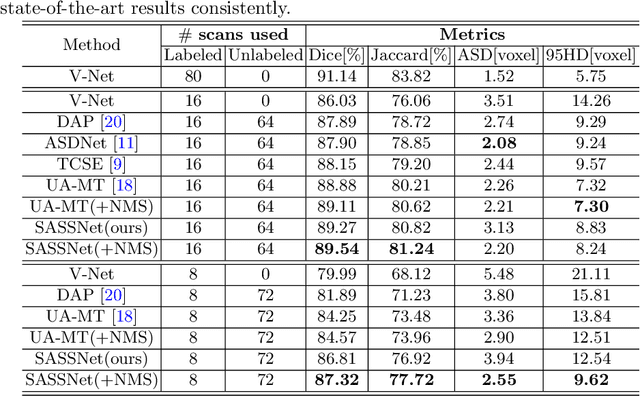
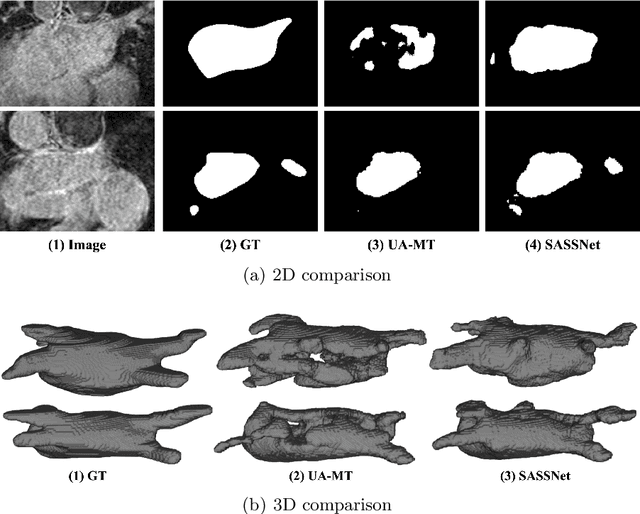
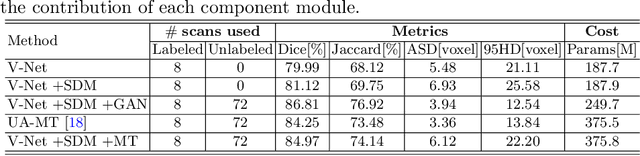
Semi-supervised learning has attracted much attention in medical image segmentation due to challenges in acquiring pixel-wise image annotations, which is a crucial step for building high-performance deep learning methods. Most existing semi-supervised segmentation approaches either tend to neglect geometric constraint in object segments, leading to incomplete object coverage, or impose strong shape prior that requires extra alignment. In this work, we propose a novel shapeaware semi-supervised segmentation strategy to leverage abundant unlabeled data and to enforce a geometric shape constraint on the segmentation output. To achieve this, we develop a multi-task deep network that jointly predicts semantic segmentation and signed distance map(SDM) of object surfaces. During training, we introduce an adversarial loss between the predicted SDMs of labeled and unlabeled data so that our network is able to capture shape-aware features more effectively. Experiments on the Atrial Segmentation Challenge dataset show that our method outperforms current state-of-the-art approaches with improved shape estimation, which validates its efficacy. Code is available at https://github.com/kleinzcy/SASSnet.