 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEI-Part: Explode for Completion and Implode for Refinement
Mar 14, 2026Part-level 3D generation is crucial for various downstream applications, including gaming, film production, and industrial design. However, decomposing a 3D shape into geometrically plausible and meaningful components remains a significant challenge. Previous part-based generation methods often struggle to produce well-constructed parts, exhibiting poor structural coherence, geometric implausibility, inaccuracy, or inefficiency. To address these challenges, we introduce EI-Part, a novel framework specifically designed to generate high-quality 3D shapes with components, characterized by strong structural coherence, geometric plausibility, geometric fidelity, and generation efficiency. We propose utilizing distinct representations at different stages: an Explode state for part completion and an Implode state for geometry refinement. This strategy fully leverages spatial resolution, enabling flexible part completion and fine geometric detail generation. To maintain structural coherence between parts, a self-attention mechanism is incorporated in both exploded and imploded states, facilitating effective information perception and feature fusion among components during generation. Extensive experiments on multiple benchmarks demonstrate that EI-Part efficiently produces semantically meaningful and structurally coherent parts with fine-grained geometric details, achieving state-of-the-art performance in part-level 3D generation. Project page: https://cvhadessun.github.io/EI-Part/
MLLM-4D: Towards Visual-based Spatial-Temporal Intelligence
Feb 28, 2026Humans are born with vision-based 4D spatial-temporal intelligence, which enables us to perceive and reason about the evolution of 3D space over time from purely visual inputs. Despite its importance, this capability remains a significant bottleneck for current multimodal large language models (MLLMs). To tackle this challenge, we introduce MLLM-4D, a comprehensive framework designed to bridge the gaps in training data curation and model post-training for spatiotemporal understanding and reasoning. On the data front, we develop a cost-efficient data curation pipeline that repurposes existing stereo video datasets into high-quality 4D spatiotemporal instructional data. This results in the MLLM4D-2M and MLLM4D-R1-30k datasets for Supervised Fine-Tuning (SFT) and Reinforcement Fine-Tuning (RFT), alongside MLLM4D-Bench for comprehensive evaluation. Regarding model training, our post-training strategy establishes a foundational 4D understanding via SFT and further catalyzes 4D reasoning capabilities by employing Group Relative Policy Optimization (GRPO) with specialized Spatiotemporal Chain of Thought (ST-CoT) prompting and Spatiotemporal reward functions (ST-reward) without involving the modification of architecture. Extensive experiments demonstrate that MLLM-4D achieves state-of-the-art spatial-temporal understanding and reasoning capabilities from purely 2D RGB inputs. Project page: https://github.com/GVCLab/MLLM-4D.
ForeHOI: Feed-forward 3D Object Reconstruction from Daily Hand-Object Interaction Videos
Feb 05, 2026The ubiquity of monocular videos capturing daily hand-object interactions presents a valuable resource for embodied intelligence. While 3D hand reconstruction from in-the-wild videos has seen significant progress, reconstructing the involved objects remains challenging due to severe occlusions and the complex, coupled motion of the camera, hands, and object. In this paper, we introduce ForeHOI, a novel feed-forward model that directly reconstructs 3D object geometry from monocular hand-object interaction videos within one minute of inference time, eliminating the need for any pre-processing steps. Our key insight is that, the joint prediction of 2D mask inpainting and 3D shape completion in a feed-forward framework can effectively address the problem of severe occlusion in monocular hand-held object videos, thereby achieving results that outperform the performance of optimization-based methods. The information exchanges between the 2D and 3D shape completion boosts the overall reconstruction quality, enabling the framework to effectively handle severe hand-object occlusion. Furthermore, to support the training of our model, we contribute the first large-scale, high-fidelity synthetic dataset of hand-object interactions with comprehensive annotations. Extensive experiments demonstrate that ForeHOI achieves state-of-the-art performance in object reconstruction, significantly outperforming previous methods with around a 100x speedup. Code and data are available at: https://github.com/Tao-11-chen/ForeHOI.
MV-Performer: Taming Video Diffusion Model for Faithful and Synchronized Multi-view Performer Synthesis
Oct 08, 2025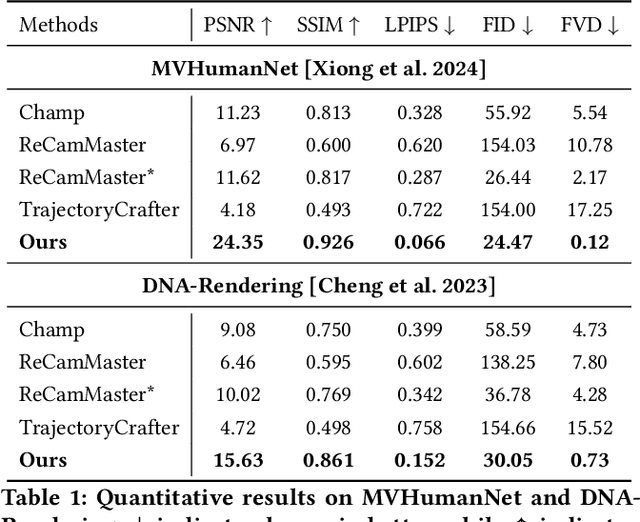

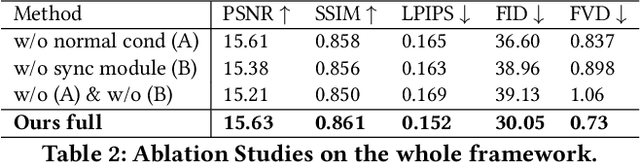
Recent breakthroughs in video generation, powered by large-scale datasets and diffusion techniques, have shown that video diffusion models can function as implicit 4D novel view synthesizers. Nevertheless, current methods primarily concentrate on redirecting camera trajectory within the front view while struggling to generate 360-degree viewpoint changes. In this paper, we focus on human-centric subdomain and present MV-Performer, an innovative framework for creating synchronized novel view videos from monocular full-body captures. To achieve a 360-degree synthesis, we extensively leverage the MVHumanNet dataset and incorporate an informative condition signal. Specifically, we use the camera-dependent normal maps rendered from oriented partial point clouds, which effectively alleviate the ambiguity between seen and unseen observations. To maintain synchronization in the generated videos, we propose a multi-view human-centric video diffusion model that fuses information from the reference video, partial rendering, and different viewpoints. Additionally, we provide a robust inference procedure for in-the-wild video cases, which greatly mitigates the artifacts induced by imperfect monocular depth estimation. Extensive experiments on three datasets demonstrate our MV-Performer's state-of-the-art effectiveness and robustness, setting a strong model for human-centric 4D novel view synthesis.
Hi3DGen: High-fidelity 3D Geometry Generation from Images via Normal Bridging
Mar 31, 2025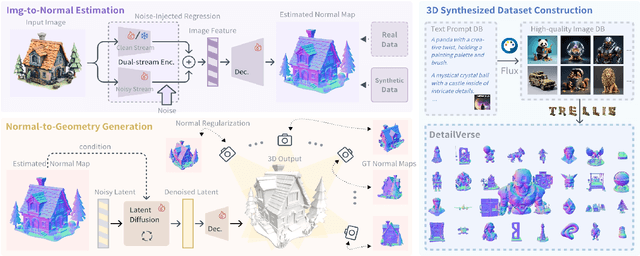
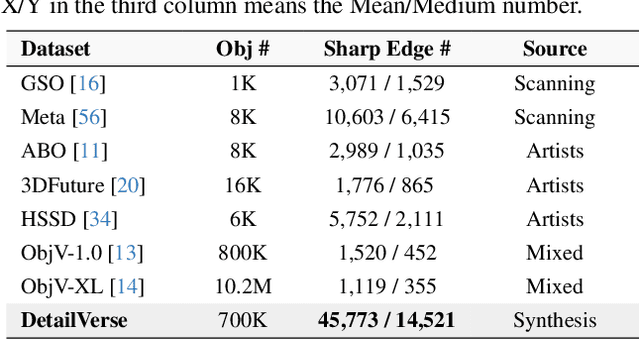
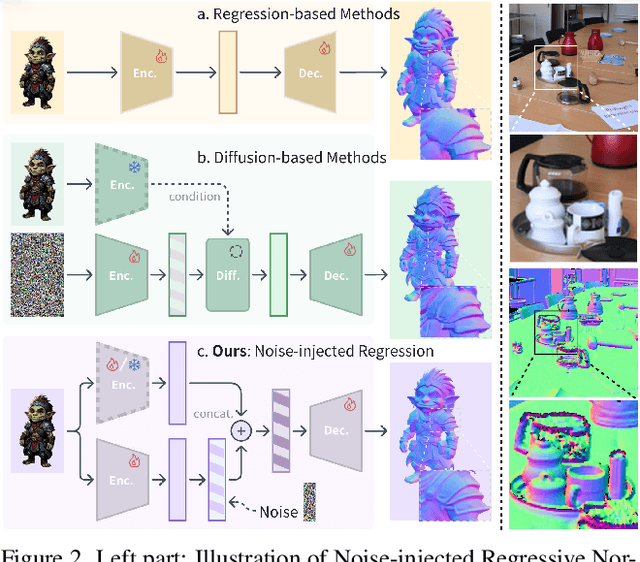
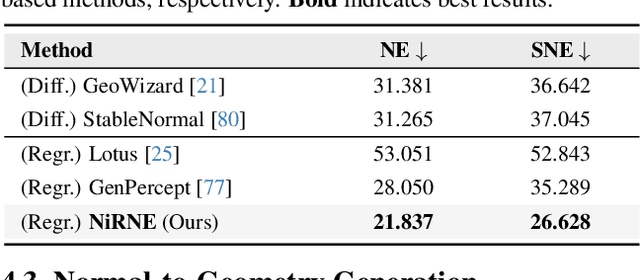
With the growing demand for high-fidelity 3D models from 2D images, existing methods still face significant challenges in accurately reproducing fine-grained geometric details due to limitations in domain gaps and inherent ambiguities in RGB images. To address these issues, we propose Hi3DGen, a novel framework for generating high-fidelity 3D geometry from images via normal bridging. Hi3DGen consists of three key components: (1) an image-to-normal estimator that decouples the low-high frequency image pattern with noise injection and dual-stream training to achieve generalizable, stable, and sharp estimation; (2) a normal-to-geometry learning approach that uses normal-regularized latent diffusion learning to enhance 3D geometry generation fidelity; and (3) a 3D data synthesis pipeline that constructs a high-quality dataset to support training. Extensive experiments demonstrate the effectiveness and superiority of our framework in generating rich geometric details, outperforming state-of-the-art methods in terms of fidelity. Our work provides a new direction for high-fidelity 3D geometry generation from images by leveraging normal maps as an intermediate representation.
GaussReg: Fast 3D Registration with Gaussian Splatting
Jul 07, 2024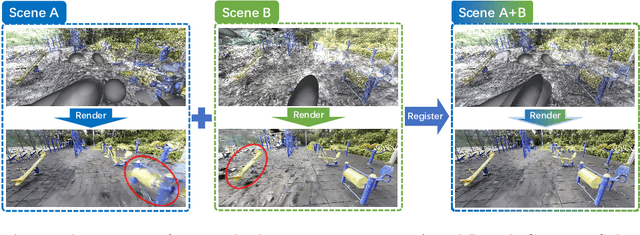
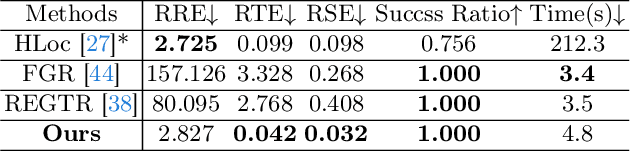
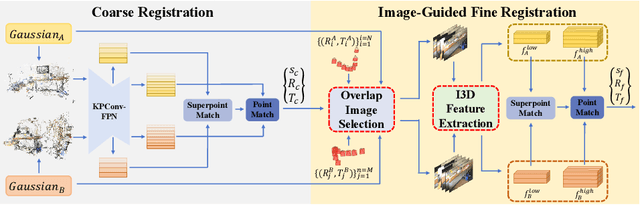
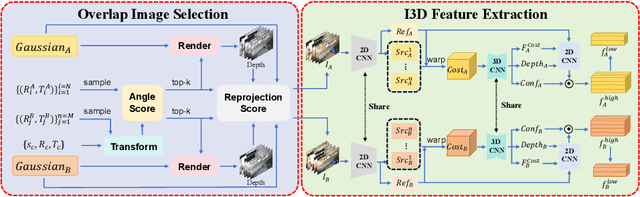
Point cloud registration is a fundamental problem for large-scale 3D scene scanning and reconstruction. With the help of deep learning, registration methods have evolved significantly, reaching a nearly-mature stage. As the introduction of Neural Radiance Fields (NeRF), it has become the most popular 3D scene representation as its powerful view synthesis capabilities. Regarding NeRF representation, its registration is also required for large-scale scene reconstruction. However, this topic extremly lacks exploration. This is due to the inherent challenge to model the geometric relationship among two scenes with implicit representations. The existing methods usually convert the implicit representation to explicit representation for further registration. Most recently, Gaussian Splatting (GS) is introduced, employing explicit 3D Gaussian. This method significantly enhances rendering speed while maintaining high rendering quality. Given two scenes with explicit GS representations, in this work, we explore the 3D registration task between them. To this end, we propose GaussReg, a novel coarse-to-fine framework, both fast and accurate. The coarse stage follows existing point cloud registration methods and estimates a rough alignment for point clouds from GS. We further newly present an image-guided fine registration approach, which renders images from GS to provide more detailed geometric information for precise alignment. To support comprehensive evaluation, we carefully build a scene-level dataset called ScanNet-GSReg with 1379 scenes obtained from the ScanNet dataset and collect an in-the-wild dataset called GSReg. Experimental results demonstrate our method achieves state-of-the-art performance on multiple datasets. Our GaussReg is 44 times faster than HLoc (SuperPoint as the feature extractor and SuperGlue as the matcher) with comparable accuracy.
GauStudio: A Modular Framework for 3D Gaussian Splatting and Beyond
Mar 28, 2024We present GauStudio, a novel modular framework for modeling 3D Gaussian Splatting (3DGS) to provide standardized, plug-and-play components for users to easily customize and implement a 3DGS pipeline. Supported by our framework, we propose a hybrid Gaussian representation with foreground and skyball background models. Experiments demonstrate this representation reduces artifacts in unbounded outdoor scenes and improves novel view synthesis. Finally, we propose Gaussian Splatting Surface Reconstruction (GauS), a novel render-then-fuse approach for high-fidelity mesh reconstruction from 3DGS inputs without fine-tuning. Overall, our GauStudio framework, hybrid representation, and GauS approach enhance 3DGS modeling and rendering capabilities, enabling higher-quality novel view synthesis and surface reconstruction.
TIFace: Improving Facial Reconstruction through Tensorial Radiance Fields and Implicit Surfaces
Dec 15, 2023
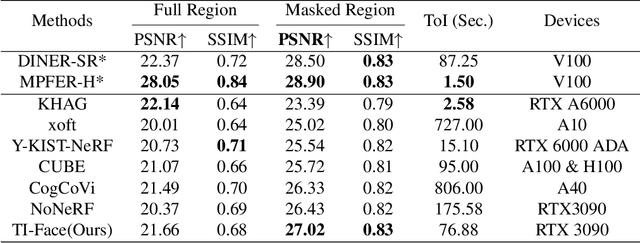
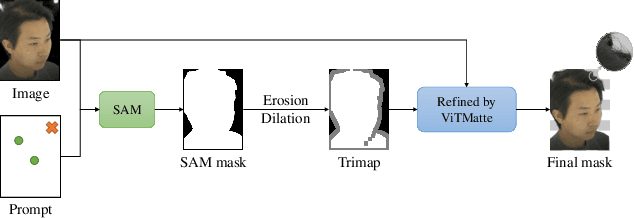
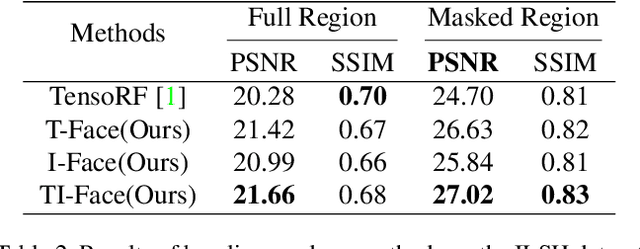
This report describes the solution that secured the first place in the "View Synthesis Challenge for Human Heads (VSCHH)" at the ICCV 2023 workshop. Given the sparse view images of human heads, the objective of this challenge is to synthesize images from novel viewpoints. Due to the complexity of textures on the face and the impact of lighting, the baseline method TensoRF yields results with significant artifacts, seriously affecting facial reconstruction. To address this issue, we propose TI-Face, which improves facial reconstruction through tensorial radiance fields (T-Face) and implicit surfaces (I-Face), respectively. Specifically, we employ an SAM-based approach to obtain the foreground mask, thereby filtering out intense lighting in the background. Additionally, we design mask-based constraints and sparsity constraints to eliminate rendering artifacts effectively. The experimental results demonstrate the effectiveness of the proposed improvements and superior performance of our method on face reconstruction. The code will be available at https://github.com/RuijieZhu94/TI-Face.
TopoMLP: An Simple yet Strong Pipeline for Driving Topology Reasoning
Oct 10, 2023



Topology reasoning aims to comprehensively understand road scenes and present drivable routes in autonomous driving. It requires detecting road centerlines (lane) and traffic elements, further reasoning their topology relationship, i.e., lane-lane topology, and lane-traffic topology. In this work, we first present that the topology score relies heavily on detection performance on lane and traffic elements. Therefore, we introduce a powerful 3D lane detector and an improved 2D traffic element detector to extend the upper limit of topology performance. Further, we propose TopoMLP, a simple yet high-performance pipeline for driving topology reasoning. Based on the impressive detection performance, we develop two simple MLP-based heads for topology generation. TopoMLP achieves state-of-the-art performance on OpenLane-V2 benchmark, i.e., 41.2% OLS with ResNet-50 backbone. It is also the 1st solution for 1st OpenLane Topology in Autonomous Driving Challenge. We hope such simple and strong pipeline can provide some new insights to the community. Code is at https://github.com/wudongming97/TopoMLP.
The 1st-place Solution for CVPR 2023 OpenLane Topology in Autonomous Driving Challenge
Jun 16, 2023We present the 1st-place solution of OpenLane Topology in Autonomous Driving Challenge. Considering that topology reasoning is based on centerline detection and traffic element detection, we develop a multi-stage framework for high performance. Specifically, the centerline is detected by the powerful PETRv2 detector and the popular YOLOv8 is employed to detect the traffic elements. Further, we design a simple yet effective MLP-based head for topology prediction. Our method achieves 55\% OLS on the OpenLaneV2 test set, surpassing the 2nd solution by 8 points.