 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Video Matting
Aug 11, 2025Video matting has traditionally been limited by the lack of high-quality ground-truth data. Most existing video matting datasets provide only human-annotated imperfect alpha and foreground annotations, which must be composited to background images or videos during the training stage. Thus, the generalization capability of previous methods in real-world scenarios is typically poor. In this work, we propose to solve the problem from two perspectives. First, we emphasize the importance of large-scale pre-training by pursuing diverse synthetic and pseudo-labeled segmentation datasets. We also develop a scalable synthetic data generation pipeline that can render diverse human bodies and fine-grained hairs, yielding around 200 video clips with a 3-second duration for fine-tuning. Second, we introduce a novel video matting approach that can effectively leverage the rich priors from pre-trained video diffusion models. This architecture offers two key advantages. First, strong priors play a critical role in bridging the domain gap between synthetic and real-world scenes. Second, unlike most existing methods that process video matting frame-by-frame and use an independent decoder to aggregate temporal information, our model is inherently designed for video, ensuring strong temporal consistency. We provide a comprehensive quantitative evaluation across three benchmark datasets, demonstrating our approach's superior performance, and present comprehensive qualitative results in diverse real-world scenes, illustrating the strong generalization capability of our method. The code is available at https://github.com/aim-uofa/GVM.
POMATO: Marrying Pointmap Matching with Temporal Motion for Dynamic 3D Reconstruction
Apr 08, 20253D reconstruction in dynamic scenes primarily relies on the combination of geometry estimation and matching modules where the latter task is pivotal for distinguishing dynamic regions which can help to mitigate the interference introduced by camera and object motion. Furthermore, the matching module explicitly models object motion, enabling the tracking of specific targets and advancing motion understanding in complex scenarios. Recently, the proposed representation of pointmap in DUSt3R suggests a potential solution to unify both geometry estimation and matching in 3D space, but it still struggles with ambiguous matching in dynamic regions, which may hamper further improvement. In this work, we present POMATO, a unified framework for dynamic 3D reconstruction by marrying pointmap matching with temporal motion. Specifically, our method first learns an explicit matching relationship by mapping RGB pixels from both dynamic and static regions across different views to 3D pointmaps within a unified coordinate system. Furthermore, we introduce a temporal motion module for dynamic motions that ensures scale consistency across different frames and enhances performance in tasks requiring both precise geometry and reliable matching, most notably 3D point tracking. We show the effectiveness of the proposed pointmap matching and temporal fusion paradigm by demonstrating the remarkable performance across multiple downstream tasks, including video depth estimation, 3D point tracking, and pose estimation. Code and models are publicly available at https://github.com/wyddmw/POMATO.
Unleashing the Potential of the Diffusion Model in Few-shot Semantic Segmentation
Oct 03, 2024



The Diffusion Model has not only garnered noteworthy achievements in the realm of image generation but has also demonstrated its potential as an effective pretraining method utilizing unlabeled data. Drawing from the extensive potential unveiled by the Diffusion Model in both semantic correspondence and open vocabulary segmentation, our work initiates an investigation into employing the Latent Diffusion Model for Few-shot Semantic Segmentation. Recently, inspired by the in-context learning ability of large language models, Few-shot Semantic Segmentation has evolved into In-context Segmentation tasks, morphing into a crucial element in assessing generalist segmentation models. In this context, we concentrate on Few-shot Semantic Segmentation, establishing a solid foundation for the future development of a Diffusion-based generalist model for segmentation. Our initial focus lies in understanding how to facilitate interaction between the query image and the support image, resulting in the proposal of a KV fusion method within the self-attention framework. Subsequently, we delve deeper into optimizing the infusion of information from the support mask and simultaneously re-evaluating how to provide reasonable supervision from the query mask. Based on our analysis, we establish a simple and effective framework named DiffewS, maximally retaining the original Latent Diffusion Model's generative framework and effectively utilizing the pre-training prior. Experimental results demonstrate that our method significantly outperforms the previous SOTA models in multiple settings.
GeoBench: Benchmarking and Analyzing Monocular Geometry Estimation Models
Jun 18, 2024



Recent advances in discriminative and generative pretraining have yielded geometry estimation models with strong generalization capabilities. While discriminative monocular geometry estimation methods rely on large-scale fine-tuning data to achieve zero-shot generalization, several generative-based paradigms show the potential of achieving impressive generalization performance on unseen scenes by leveraging pre-trained diffusion models and fine-tuning on even a small scale of synthetic training data. Frustratingly, these models are trained with different recipes on different datasets, making it hard to find out the critical factors that determine the evaluation performance. Besides, current geometry evaluation benchmarks have two main drawbacks that may prevent the development of the field, i.e., limited scene diversity and unfavorable label quality. To resolve the above issues, (1) we build fair and strong baselines in a unified codebase for evaluating and analyzing the geometry estimation models; (2) we evaluate monocular geometry estimators on more challenging benchmarks for geometry estimation task with diverse scenes and high-quality annotations. Our results reveal that pre-trained using large data, discriminative models such as DINOv2, can outperform generative counterparts with a small amount of high-quality synthetic data under the same training configuration, which suggests that fine-tuning data quality is a more important factor than the data scale and model architecture. Our observation also raises a question: if simply fine-tuning a general vision model such as DINOv2 using a small amount of synthetic depth data produces SOTA results, do we really need complex generative models for depth estimation? We believe this work can propel advancements in geometry estimation tasks as well as a wide range of downstream applications.
DiffCalib: Reformulating Monocular Camera Calibration as Diffusion-Based Dense Incident Map Generation
May 24, 2024Monocular camera calibration is a key precondition for numerous 3D vision applications. Despite considerable advancements, existing methods often hinge on specific assumptions and struggle to generalize across varied real-world scenarios, and the performance is limited by insufficient training data. Recently, diffusion models trained on expansive datasets have been confirmed to maintain the capability to generate diverse, high-quality images. This success suggests a strong potential of the models to effectively understand varied visual information. In this work, we leverage the comprehensive visual knowledge embedded in pre-trained diffusion models to enable more robust and accurate monocular camera intrinsic estimation. Specifically, we reformulate the problem of estimating the four degrees of freedom (4-DoF) of camera intrinsic parameters as a dense incident map generation task. The map details the angle of incidence for each pixel in the RGB image, and its format aligns well with the paradigm of diffusion models. The camera intrinsic then can be derived from the incident map with a simple non-learning RANSAC algorithm during inference. Moreover, to further enhance the performance, we jointly estimate a depth map to provide extra geometric information for the incident map estimation. Extensive experiments on multiple testing datasets demonstrate that our model achieves state-of-the-art performance, gaining up to a 40% reduction in prediction errors. Besides, the experiments also show that the precise camera intrinsic and depth maps estimated by our pipeline can greatly benefit practical applications such as 3D reconstruction from a single in-the-wild image.
Diffusion Models Trained with Large Data Are Transferable Visual Models
Mar 15, 2024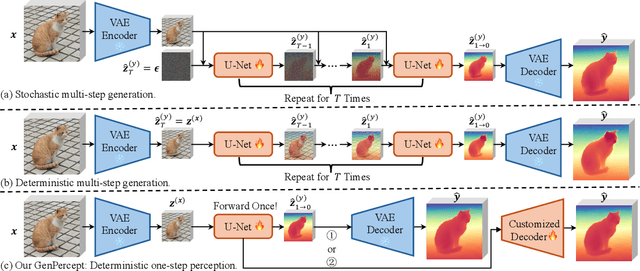


We show that, simply initializing image understanding models using a pre-trained UNet (or transformer) of diffusion models, it is possible to achieve remarkable transferable performance on fundamental vision perception tasks using a moderate amount of target data (even synthetic data only), including monocular depth, surface normal, image segmentation, matting, human pose estimation, among virtually many others. Previous works have adapted diffusion models for various perception tasks, often reformulating these tasks as generation processes to align with the diffusion process. In sharp contrast, we demonstrate that fine-tuning these models with minimal adjustments can be a more effective alternative, offering the advantages of being embarrassingly simple and significantly faster. As the backbone network of Stable Diffusion models is trained on giant datasets comprising billions of images, we observe very robust generalization capabilities of the diffusion backbone. Experimental results showcase the remarkable transferability of the backbone of diffusion models across diverse tasks and real-world datasets.
Improving Neural Indoor Surface Reconstruction with Mask-Guided Adaptive Consistency Constraints
Sep 18, 2023



3D scene reconstruction from 2D images has been a long-standing task. Instead of estimating per-frame depth maps and fusing them in 3D, recent research leverages the neural implicit surface as a unified representation for 3D reconstruction. Equipped with data-driven pre-trained geometric cues, these methods have demonstrated promising performance. However, inaccurate prior estimation, which is usually inevitable, can lead to suboptimal reconstruction quality, particularly in some geometrically complex regions. In this paper, we propose a two-stage training process, decouple view-dependent and view-independent colors, and leverage two novel consistency constraints to enhance detail reconstruction performance without requiring extra priors. Additionally, we introduce an essential mask scheme to adaptively influence the selection of supervision constraints, thereby improving performance in a self-supervised paradigm. Experiments on synthetic and real-world datasets show the capability of reducing the interference from prior estimation errors and achieving high-quality scene reconstruction with rich geometric details.
FrozenRecon: Pose-free 3D Scene Reconstruction with Frozen Depth Models
Aug 10, 20233D scene reconstruction is a long-standing vision task. Existing approaches can be categorized into geometry-based and learning-based methods. The former leverages multi-view geometry but can face catastrophic failures due to the reliance on accurate pixel correspondence across views. The latter was proffered to mitigate these issues by learning 2D or 3D representation directly. However, without a large-scale video or 3D training data, it can hardly generalize to diverse real-world scenarios due to the presence of tens of millions or even billions of optimization parameters in the deep network. Recently, robust monocular depth estimation models trained with large-scale datasets have been proven to possess weak 3D geometry prior, but they are insufficient for reconstruction due to the unknown camera parameters, the affine-invariant property, and inter-frame inconsistency. Here, we propose a novel test-time optimization approach that can transfer the robustness of affine-invariant depth models such as LeReS to challenging diverse scenes while ensuring inter-frame consistency, with only dozens of parameters to optimize per video frame. Specifically, our approach involves freezing the pre-trained affine-invariant depth model's depth predictions, rectifying them by optimizing the unknown scale-shift values with a geometric consistency alignment module, and employing the resulting scale-consistent depth maps to robustly obtain camera poses and achieve dense scene reconstruction, even in low-texture regions. Experiments show that our method achieves state-of-the-art cross-dataset reconstruction on five zero-shot testing datasets.
The Second Monocular Depth Estimation Challenge
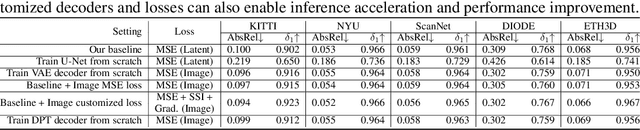
Apr 26, 2023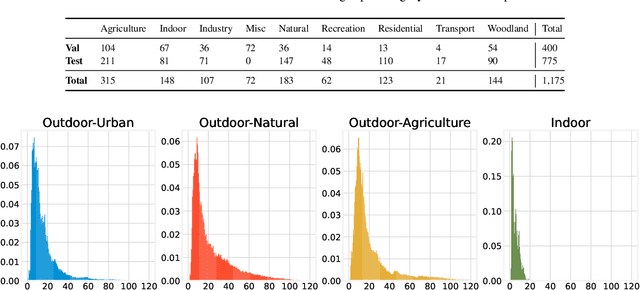
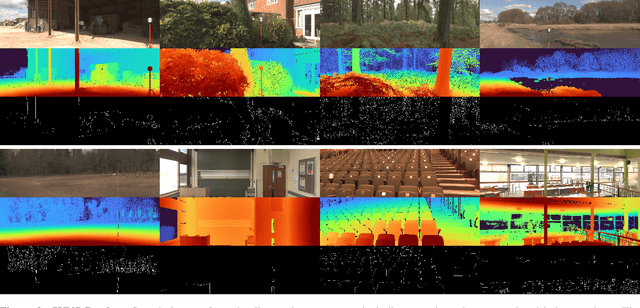
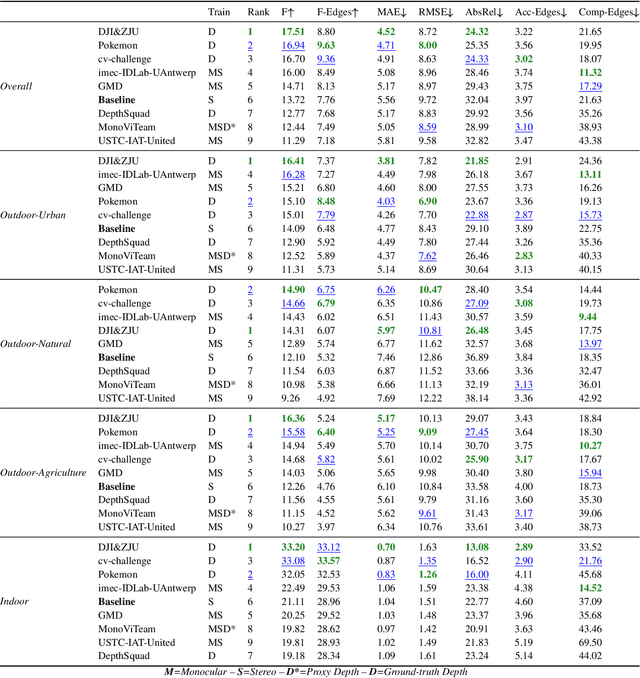
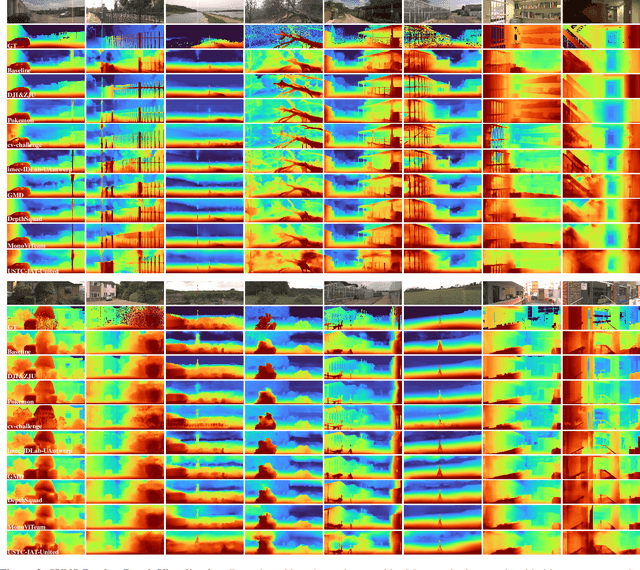
This paper discusses the results for the second edition of the Monocular Depth Estimation Challenge (MDEC). This edition was open to methods using any form of supervision, including fully-supervised, self-supervised, multi-task or proxy depth. The challenge was based around the SYNS-Patches dataset, which features a wide diversity of environments with high-quality dense ground-truth. This includes complex natural environments, e.g. forests or fields, which are greatly underrepresented in current benchmarks. The challenge received eight unique submissions that outperformed the provided SotA baseline on any of the pointcloud- or image-based metrics. The top supervised submission improved relative F-Score by 27.62%, while the top self-supervised improved it by 16.61%. Supervised submissions generally leveraged large collections of datasets to improve data diversity. Self-supervised submissions instead updated the network architecture and pretrained backbones. These results represent a significant progress in the field, while highlighting avenues for future research, such as reducing interpolation artifacts at depth boundaries, improving self-supervised indoor performance and overall natural image accuracy.
DETRDistill: A Universal Knowledge Distillation Framework for DETR-families
Nov 21, 2022Transformer-based detectors (DETRs) have attracted great attention due to their sparse training paradigm and the removal of post-processing operations, but the huge model can be computationally time-consuming and difficult to be deployed in real-world applications. To tackle this problem, knowledge distillation (KD) can be employed to compress the huge model by constructing a universal teacher-student learning framework. Different from the traditional CNN detectors, where the distillation targets can be naturally aligned through the feature map, DETR regards object detection as a set prediction problem, leading to an unclear relationship between teacher and student during distillation. In this paper, we propose DETRDistill, a novel knowledge distillation dedicated to DETR-families. We first explore a sparse matching paradigm with progressive stage-by-stage instance distillation. Considering the diverse attention mechanisms adopted in different DETRs, we propose attention-agnostic feature distillation module to overcome the ineffectiveness of conventional feature imitation. Finally, to fully leverage the intermediate products from the teacher, we introduce teacher-assisted assignment distillation, which uses the teacher's object queries and assignment results for a group with additional guidance. Extensive experiments demonstrate that our distillation method achieves significant improvement on various competitive DETR approaches, without introducing extra consumption in the inference phase. To the best of our knowledge, this is the first systematic study to explore a general distillation method for DETR-style detectors.