 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Second Monocular Depth Estimation Challenge
Apr 26, 2023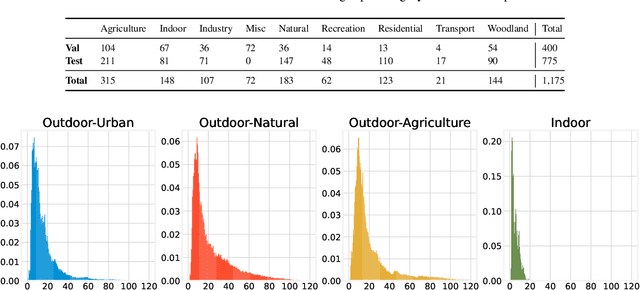
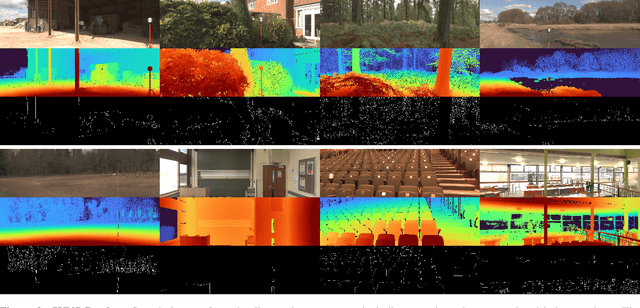
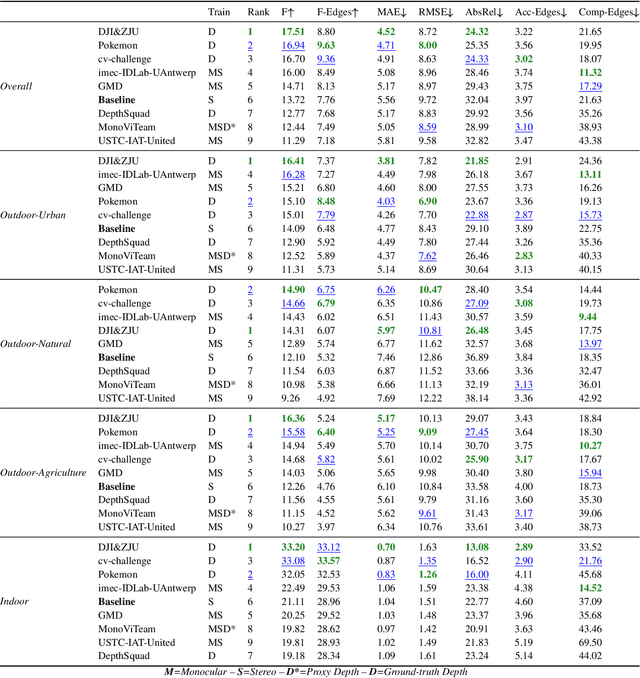
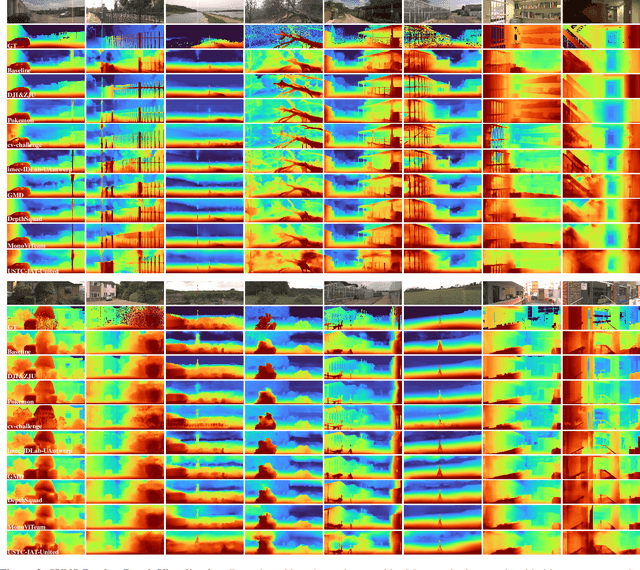
This paper discusses the results for the second edition of the Monocular Depth Estimation Challenge (MDEC). This edition was open to methods using any form of supervision, including fully-supervised, self-supervised, multi-task or proxy depth. The challenge was based around the SYNS-Patches dataset, which features a wide diversity of environments with high-quality dense ground-truth. This includes complex natural environments, e.g. forests or fields, which are greatly underrepresented in current benchmarks. The challenge received eight unique submissions that outperformed the provided SotA baseline on any of the pointcloud- or image-based metrics. The top supervised submission improved relative F-Score by 27.62%, while the top self-supervised improved it by 16.61%. Supervised submissions generally leveraged large collections of datasets to improve data diversity. Self-supervised submissions instead updated the network architecture and pretrained backbones. These results represent a significant progress in the field, while highlighting avenues for future research, such as reducing interpolation artifacts at depth boundaries, improving self-supervised indoor performance and overall natural image accuracy.
The Monocular Depth Estimation Challenge
Nov 22, 2022



This paper summarizes the results of the first Monocular Depth Estimation Challenge (MDEC) organized at WACV2023. This challenge evaluated the progress of self-supervised monocular depth estimation on the challenging SYNS-Patches dataset. The challenge was organized on CodaLab and received submissions from 4 valid teams. Participants were provided a devkit containing updated reference implementations for 16 State-of-the-Art algorithms and 4 novel techniques. The threshold for acceptance for novel techniques was to outperform every one of the 16 SotA baselines. All participants outperformed the baseline in traditional metrics such as MAE or AbsRel. However, pointcloud reconstruction metrics were challenging to improve upon. We found predictions were characterized by interpolation artefacts at object boundaries and errors in relative object positioning. We hope this challenge is a valuable contribution to the community and encourage authors to participate in future editions.
Transformer-based Network for RGB-D Saliency Detection
Dec 01, 2021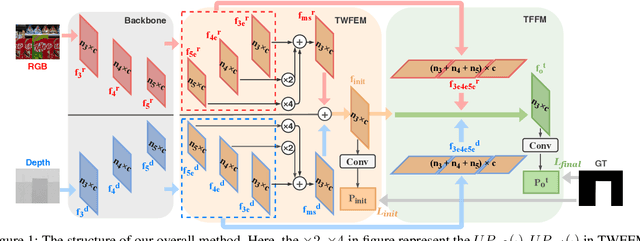
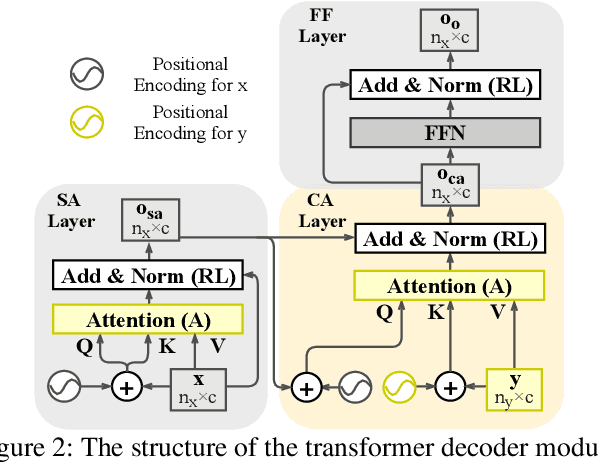

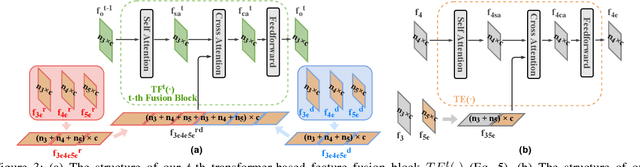
RGB-D saliency detection integrates information from both RGB images and depth maps to improve prediction of salient regions under challenging conditions. The key to RGB-D saliency detection is to fully mine and fuse information at multiple scales across the two modalities. Previous approaches tend to apply the multi-scale and multi-modal fusion separately via local operations, which fails to capture long-range dependencies. Here we propose a transformer-based network to address this issue. Our proposed architecture is composed of two modules: a transformer-based within-modality feature enhancement module (TWFEM) and a transformer-based feature fusion module (TFFM). TFFM conducts a sufficient feature fusion by integrating features from multiple scales and two modalities over all positions simultaneously. TWFEM enhances feature on each scale by selecting and integrating complementary information from other scales within the same modality before TFFM. We show that transformer is a uniform operation which presents great efficacy in both feature fusion and feature enhancement, and simplifies the model design. Extensive experimental results on six benchmark datasets demonstrate that our proposed network performs favorably against state-of-the-art RGB-D saliency detection methods.