 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Fourth Monocular Depth Estimation Challenge
Apr 24, 2025


This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
The Third Monocular Depth Estimation Challenge
Apr 27, 2024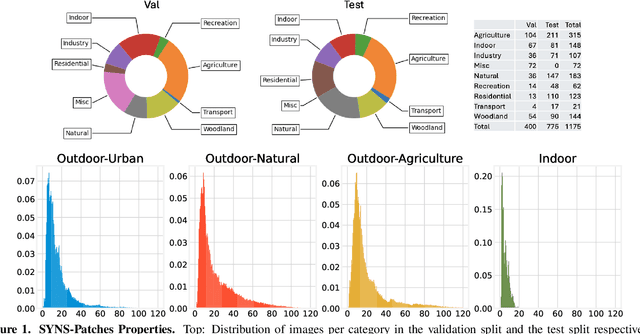

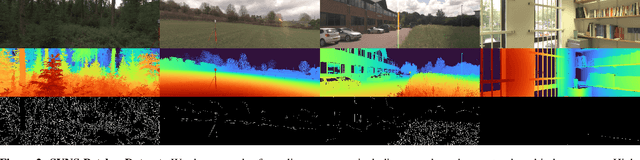
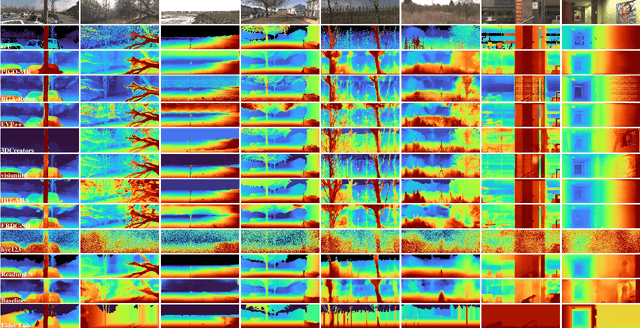
This paper discusses the results of the third edition of the Monocular Depth Estimation Challenge (MDEC). The challenge focuses on zero-shot generalization to the challenging SYNS-Patches dataset, featuring complex scenes in natural and indoor settings. As with the previous edition, methods can use any form of supervision, i.e. supervised or self-supervised. The challenge received a total of 19 submissions outperforming the baseline on the test set: 10 among them submitted a report describing their approach, highlighting a diffused use of foundational models such as Depth Anything at the core of their method. The challenge winners drastically improved 3D F-Score performance, from 17.51% to 23.72%.
Kick Back & Relax++: Scaling Beyond Ground-Truth Depth with SlowTV & CribsTV
Mar 03, 2024
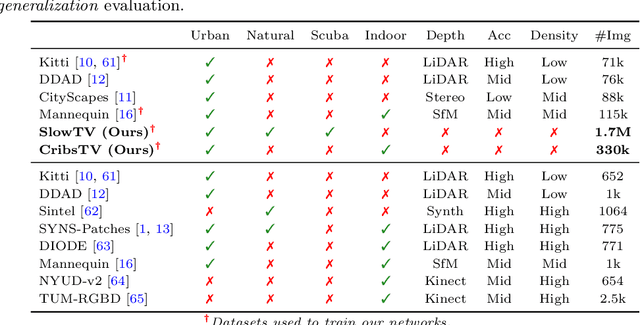

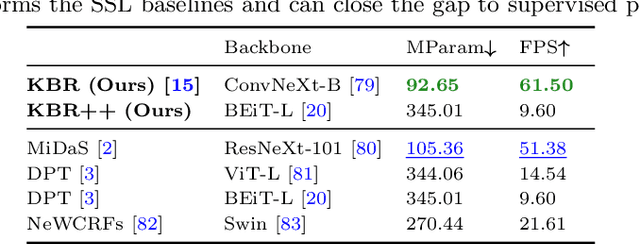
Self-supervised learning is the key to unlocking generic computer vision systems. By eliminating the reliance on ground-truth annotations, it allows scaling to much larger data quantities. Unfortunately, self-supervised monocular depth estimation (SS-MDE) has been limited by the absence of diverse training data. Existing datasets have focused exclusively on urban driving in densely populated cities, resulting in models that fail to generalize beyond this domain. To address these limitations, this paper proposes two novel datasets: SlowTV and CribsTV. These are large-scale datasets curated from publicly available YouTube videos, containing a total of 2M training frames. They offer an incredibly diverse set of environments, ranging from snowy forests to coastal roads, luxury mansions and even underwater coral reefs. We leverage these datasets to tackle the challenging task of zero-shot generalization, outperforming every existing SS-MDE approach and even some state-of-the-art supervised methods. The generalization capabilities of our models are further enhanced by a range of components and contributions: 1) learning the camera intrinsics, 2) a stronger augmentation regime targeting aspect ratio changes, 3) support frame randomization, 4) flexible motion estimation, 5) a modern transformer-based architecture. We demonstrate the effectiveness of each component in extensive ablation experiments. To facilitate the development of future research, we make the datasets, code and pretrained models available to the public at https://github.com/jspenmar/slowtv_monodepth.
Kick Back & Relax: Learning to Reconstruct the World by Watching SlowTV
Jul 20, 2023



Self-supervised monocular depth estimation (SS-MDE) has the potential to scale to vast quantities of data. Unfortunately, existing approaches limit themselves to the automotive domain, resulting in models incapable of generalizing to complex environments such as natural or indoor settings. To address this, we propose a large-scale SlowTV dataset curated from YouTube, containing an order of magnitude more data than existing automotive datasets. SlowTV contains 1.7M images from a rich diversity of environments, such as worldwide seasonal hiking, scenic driving and scuba diving. Using this dataset, we train an SS-MDE model that provides zero-shot generalization to a large collection of indoor/outdoor datasets. The resulting model outperforms all existing SSL approaches and closes the gap on supervised SoTA, despite using a more efficient architecture. We additionally introduce a collection of best-practices to further maximize performance and zero-shot generalization. This includes 1) aspect ratio augmentation, 2) camera intrinsic estimation, 3) support frame randomization and 4) flexible motion estimation. Code is available at https://github.com/jspenmar/slowtv_monodepth.
The Second Monocular Depth Estimation Challenge
Apr 26, 2023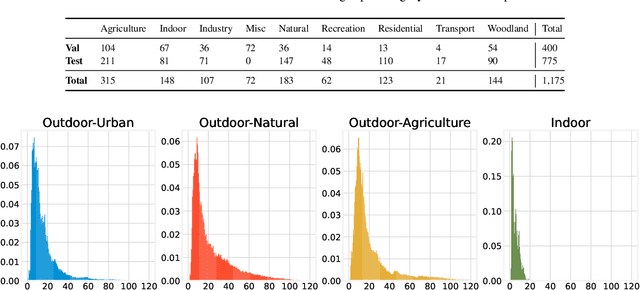
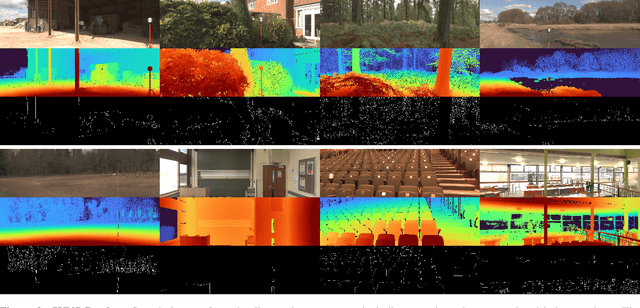
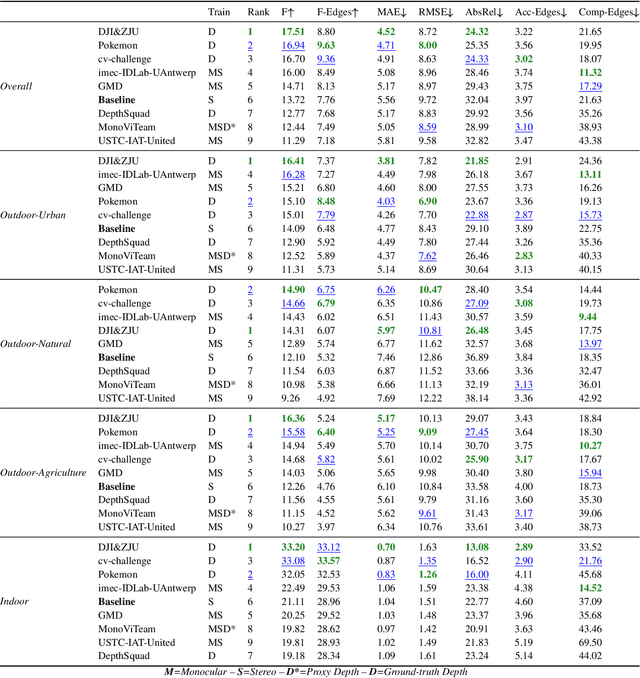
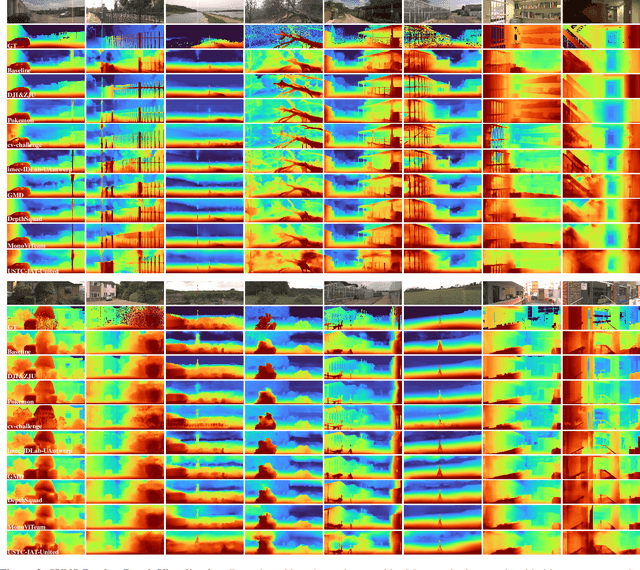
This paper discusses the results for the second edition of the Monocular Depth Estimation Challenge (MDEC). This edition was open to methods using any form of supervision, including fully-supervised, self-supervised, multi-task or proxy depth. The challenge was based around the SYNS-Patches dataset, which features a wide diversity of environments with high-quality dense ground-truth. This includes complex natural environments, e.g. forests or fields, which are greatly underrepresented in current benchmarks. The challenge received eight unique submissions that outperformed the provided SotA baseline on any of the pointcloud- or image-based metrics. The top supervised submission improved relative F-Score by 27.62%, while the top self-supervised improved it by 16.61%. Supervised submissions generally leveraged large collections of datasets to improve data diversity. Self-supervised submissions instead updated the network architecture and pretrained backbones. These results represent a significant progress in the field, while highlighting avenues for future research, such as reducing interpolation artifacts at depth boundaries, improving self-supervised indoor performance and overall natural image accuracy.
The Monocular Depth Estimation Challenge
Nov 22, 2022



This paper summarizes the results of the first Monocular Depth Estimation Challenge (MDEC) organized at WACV2023. This challenge evaluated the progress of self-supervised monocular depth estimation on the challenging SYNS-Patches dataset. The challenge was organized on CodaLab and received submissions from 4 valid teams. Participants were provided a devkit containing updated reference implementations for 16 State-of-the-Art algorithms and 4 novel techniques. The threshold for acceptance for novel techniques was to outperform every one of the 16 SotA baselines. All participants outperformed the baseline in traditional metrics such as MAE or AbsRel. However, pointcloud reconstruction metrics were challenging to improve upon. We found predictions were characterized by interpolation artefacts at object boundaries and errors in relative object positioning. We hope this challenge is a valuable contribution to the community and encourage authors to participate in future editions.
Medusa: Universal Feature Learning via Attentional Multitasking
Apr 12, 2022
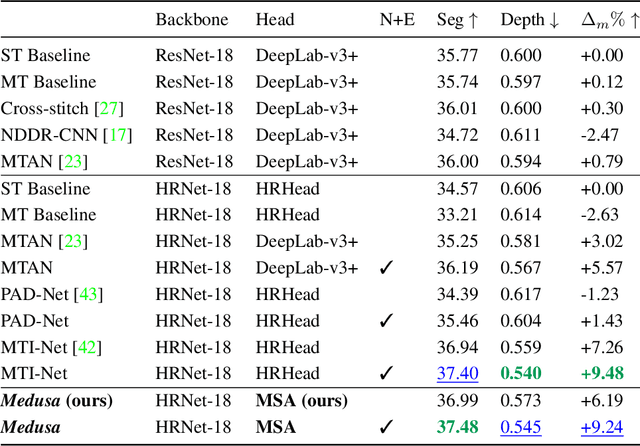
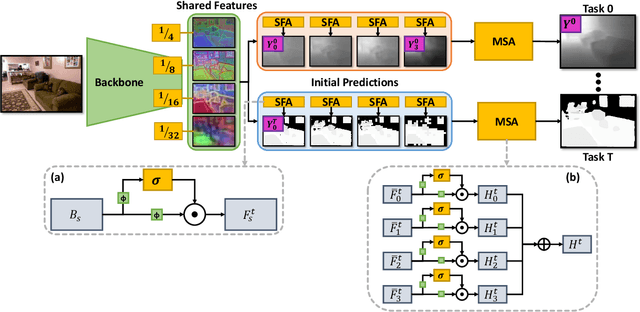
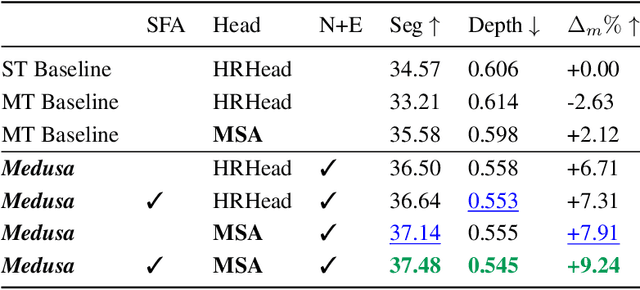
Recent approaches to multi-task learning (MTL) have focused on modelling connections between tasks at the decoder level. This leads to a tight coupling between tasks, which need retraining if a new task is inserted or removed. We argue that MTL is a stepping stone towards universal feature learning (UFL), which is the ability to learn generic features that can be applied to new tasks without retraining. We propose Medusa to realize this goal, designing task heads with dual attention mechanisms. The shared feature attention masks relevant backbone features for each task, allowing it to learn a generic representation. Meanwhile, a novel Multi-Scale Attention head allows the network to better combine per-task features from different scales when making the final prediction. We show the effectiveness of Medusa in UFL (+13.18% improvement), while maintaining MTL performance and being 25% more efficient than previous approaches.
DeFeat-Net: General Monocular Depth via Simultaneous Unsupervised Representation Learning
Mar 30, 2020
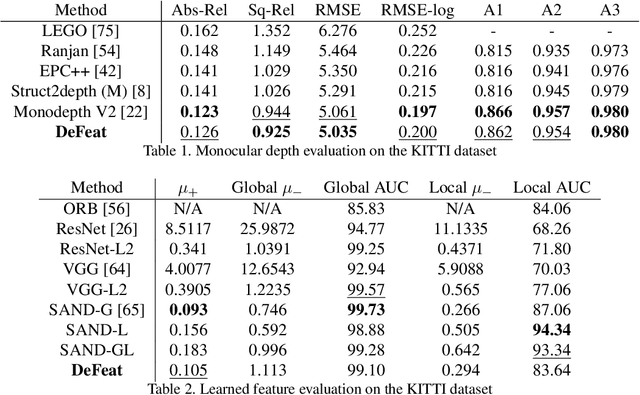
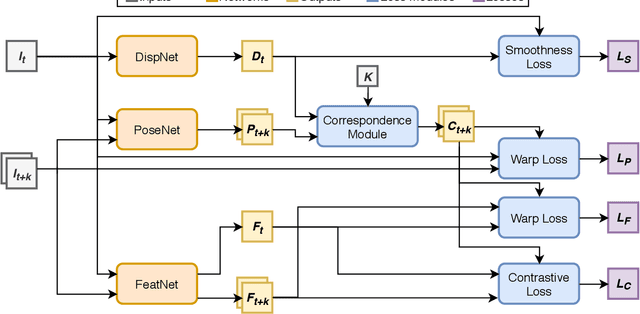

In the current monocular depth research, the dominant approach is to employ unsupervised training on large datasets, driven by warped photometric consistency. Such approaches lack robustness and are unable to generalize to challenging domains such as nighttime scenes or adverse weather conditions where assumptions about photometric consistency break down. We propose DeFeat-Net (Depth & Feature network), an approach to simultaneously learn a cross-domain dense feature representation, alongside a robust depth-estimation framework based on warped feature consistency. The resulting feature representation is learned in an unsupervised manner with no explicit ground-truth correspondences required. We show that within a single domain, our technique is comparable to both the current state of the art in monocular depth estimation and supervised feature representation learning. However, by simultaneously learning features, depth and motion, our technique is able to generalize to challenging domains, allowing DeFeat-Net to outperform the current state-of-the-art with around 10% reduction in all error measures on more challenging sequences such as nighttime driving.
Same Features, Different Day: Weakly Supervised Feature Learning for Seasonal Invariance
Mar 30, 2020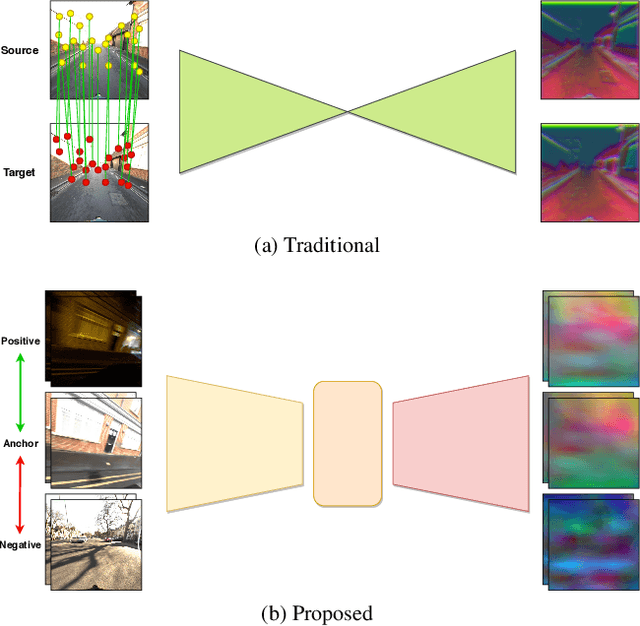


"Like night and day" is a commonly used expression to imply that two things are completely different. Unfortunately, this tends to be the case for current visual feature representations of the same scene across varying seasons or times of day. The aim of this paper is to provide a dense feature representation that can be used to perform localization, sparse matching or image retrieval, regardless of the current seasonal or temporal appearance. Recently, there have been several proposed methodologies for deep learning dense feature representations. These methods make use of ground truth pixel-wise correspondences between pairs of images and focus on the spatial properties of the features. As such, they don't address temporal or seasonal variation. Furthermore, obtaining the required pixel-wise correspondence data to train in cross-seasonal environments is highly complex in most scenarios. We propose Deja-Vu, a weakly supervised approach to learning season invariant features that does not require pixel-wise ground truth data. The proposed system only requires coarse labels indicating if two images correspond to the same location or not. From these labels, the network is trained to produce "similar" dense feature maps for corresponding locations despite environmental changes. Code will be made available at: https://github.com/jspenmar/DejaVu_Features
Scale-Adaptive Neural Dense Features: Learning via Hierarchical Context Aggregation
Mar 25, 2019
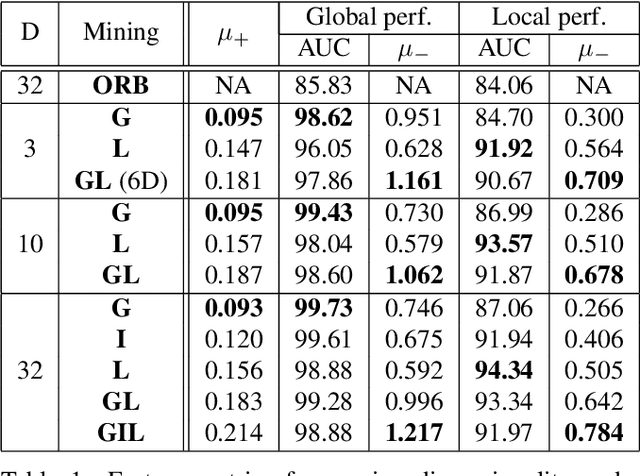

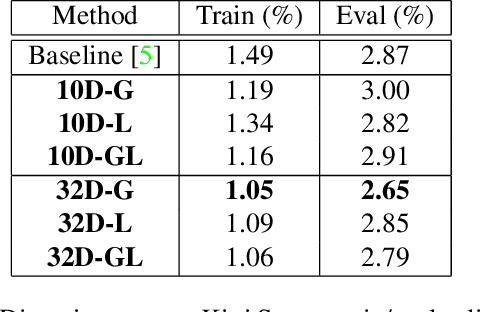
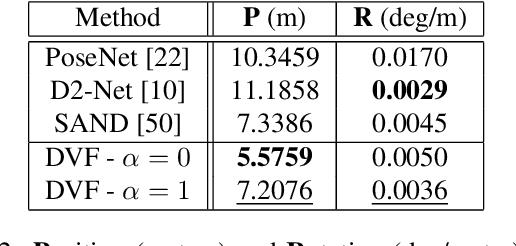
How do computers and intelligent agents view the world around them? Feature extraction and representation constitutes one the basic building blocks towards answering this question. Traditionally, this has been done with carefully engineered hand-crafted techniques such as HOG, SIFT or ORB. However, there is no ``one size fits all'' approach that satisfies all requirements. In recent years, the rising popularity of deep learning has resulted in a myriad of end-to-end solutions to many computer vision problems. These approaches, while successful, tend to lack scalability and can't easily exploit information learned by other systems. Instead, we propose SAND features, a dedicated deep learning solution to feature extraction capable of providing hierarchical context information. This is achieved by employing sparse relative labels indicating relationships of similarity/dissimilarity between image locations. The nature of these labels results in an almost infinite set of dissimilar examples to choose from. We demonstrate how the selection of negative examples during training can be used to modify the feature space and vary it's properties. To demonstrate the generality of this approach, we apply the proposed features to a multitude of tasks, each requiring different properties. This includes disparity estimation, semantic segmentation, self-localisation and SLAM. In all cases, we show how incorporating SAND features results in better or comparable results to the baseline, whilst requiring little to no additional training. Code can be found at: https://github.com/jspenmar/SAND_features