 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedusa: Universal Feature Learning via Attentional Multitasking
Paper and Code
Apr 12, 2022
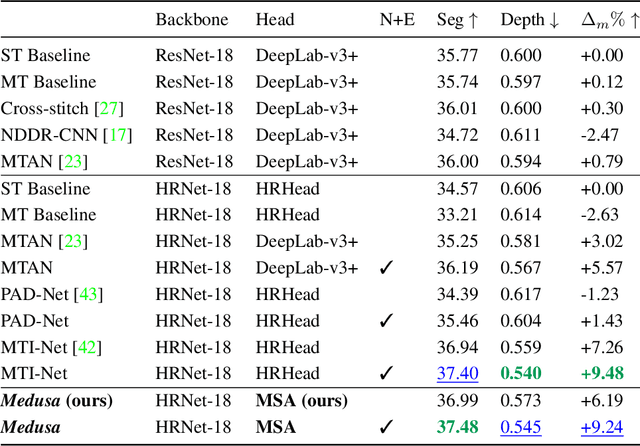
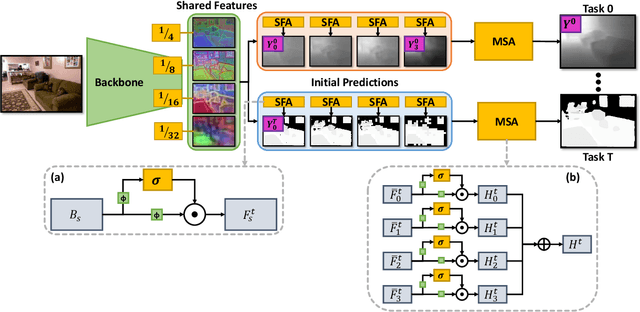
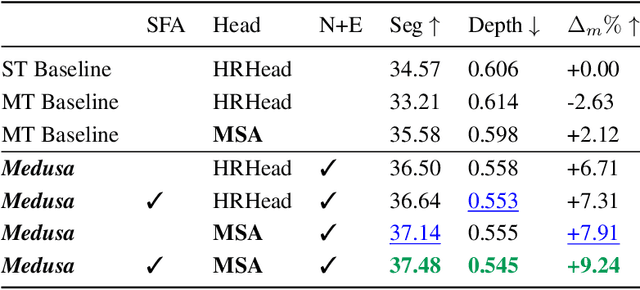
Recent approaches to multi-task learning (MTL) have focused on modelling connections between tasks at the decoder level. This leads to a tight coupling between tasks, which need retraining if a new task is inserted or removed. We argue that MTL is a stepping stone towards universal feature learning (UFL), which is the ability to learn generic features that can be applied to new tasks without retraining. We propose Medusa to realize this goal, designing task heads with dual attention mechanisms. The shared feature attention masks relevant backbone features for each task, allowing it to learn a generic representation. Meanwhile, a novel Multi-Scale Attention head allows the network to better combine per-task features from different scales when making the final prediction. We show the effectiveness of Medusa in UFL (+13.18% improvement), while maintaining MTL performance and being 25% more efficient than previous approaches.