 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereoSpace: Depth-Free Synthesis of Stereo Geometry via End-to-End Diffusion in a Canonical Space
Dec 11, 2025We introduce StereoSpace, a diffusion-based framework for monocular-to-stereo synthesis that models geometry purely through viewpoint conditioning, without explicit depth or warping. A canonical rectified space and the conditioning guide the generator to infer correspondences and fill disocclusions end-to-end. To ensure fair and leakage-free evaluation, we introduce an end-to-end protocol that excludes any ground truth or proxy geometry estimates at test time. The protocol emphasizes metrics reflecting downstream relevance: iSQoE for perceptual comfort and MEt3R for geometric consistency. StereoSpace surpasses other methods from the warp & inpaint, latent-warping, and warped-conditioning categories, achieving sharp parallax and strong robustness on layered and non-Lambertian scenes. This establishes viewpoint-conditioned diffusion as a scalable, depth-free solution for stereo generation.
Marigold: Affordable Adaptation of Diffusion-Based Image Generators for Image Analysis
May 14, 2025The success of deep learning in computer vision over the past decade has hinged on large labeled datasets and strong pretrained models. In data-scarce settings, the quality of these pretrained models becomes crucial for effective transfer learning. Image classification and self-supervised learning have traditionally been the primary methods for pretraining CNNs and transformer-based architectures. Recently, the rise of text-to-image generative models, particularly those using denoising diffusion in a latent space, has introduced a new class of foundational models trained on massive, captioned image datasets. These models' ability to generate realistic images of unseen content suggests they possess a deep understanding of the visual world. In this work, we present Marigold, a family of conditional generative models and a fine-tuning protocol that extracts the knowledge from pretrained latent diffusion models like Stable Diffusion and adapts them for dense image analysis tasks, including monocular depth estimation, surface normals prediction, and intrinsic decomposition. Marigold requires minimal modification of the pre-trained latent diffusion model's architecture, trains with small synthetic datasets on a single GPU over a few days, and demonstrates state-of-the-art zero-shot generalization. Project page: https://marigoldcomputervision.github.io
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025


This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
Marigold-DC: Zero-Shot Monocular Depth Completion with Guided Diffusion
Dec 18, 2024



Depth completion upgrades sparse depth measurements into dense depth maps guided by a conventional image. Existing methods for this highly ill-posed task operate in tightly constrained settings and tend to struggle when applied to images outside the training domain or when the available depth measurements are sparse, irregularly distributed, or of varying density. Inspired by recent advances in monocular depth estimation, we reframe depth completion as an image-conditional depth map generation guided by sparse measurements. Our method, Marigold-DC, builds on a pretrained latent diffusion model for monocular depth estimation and injects the depth observations as test-time guidance via an optimization scheme that runs in tandem with the iterative inference of denoising diffusion. The method exhibits excellent zero-shot generalization across a diverse range of environments and handles even extremely sparse guidance effectively. Our results suggest that contemporary monocular depth priors greatly robustify depth completion: it may be better to view the task as recovering dense depth from (dense) image pixels, guided by sparse depth; rather than as inpainting (sparse) depth, guided by an image. Project website: https://MarigoldDepthCompletion.github.io/
Video Depth without Video Models
Nov 28, 2024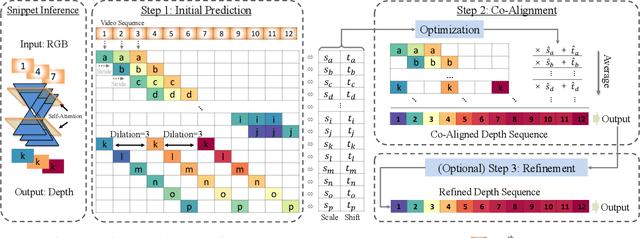
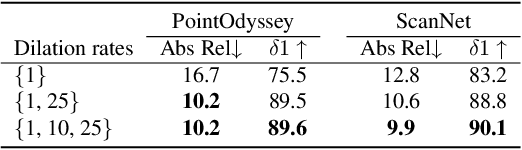
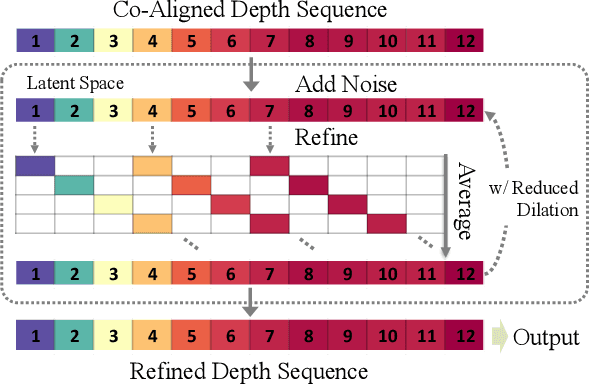
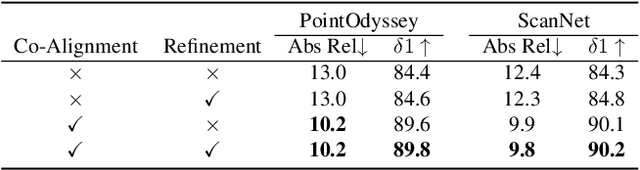
Video depth estimation lifts monocular video clips to 3D by inferring dense depth at every frame. Recent advances in single-image depth estimation, brought about by the rise of large foundation models and the use of synthetic training data, have fueled a renewed interest in video depth. However, naively applying a single-image depth estimator to every frame of a video disregards temporal continuity, which not only leads to flickering but may also break when camera motion causes sudden changes in depth range. An obvious and principled solution would be to build on top of video foundation models, but these come with their own limitations; including expensive training and inference, imperfect 3D consistency, and stitching routines for the fixed-length (short) outputs. We take a step back and demonstrate how to turn a single-image latent diffusion model (LDM) into a state-of-the-art video depth estimator. Our model, which we call RollingDepth, has two main ingredients: (i) a multi-frame depth estimator that is derived from a single-image LDM and maps very short video snippets (typically frame triplets) to depth snippets. (ii) a robust, optimization-based registration algorithm that optimally assembles depth snippets sampled at various different frame rates back into a consistent video. RollingDepth is able to efficiently handle long videos with hundreds of frames and delivers more accurate depth videos than both dedicated video depth estimators and high-performing single-frame models. Project page: rollingdepth.github.io.
BetterDepth: Plug-and-Play Diffusion Refiner for Zero-Shot Monocular Depth Estimation
Jul 25, 2024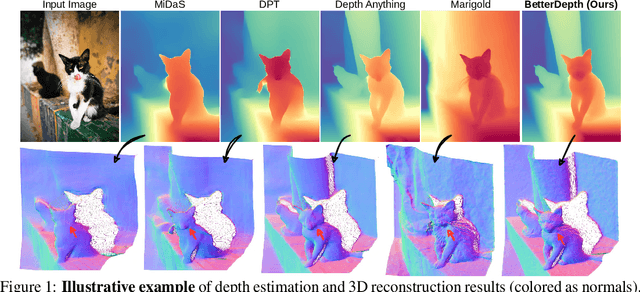

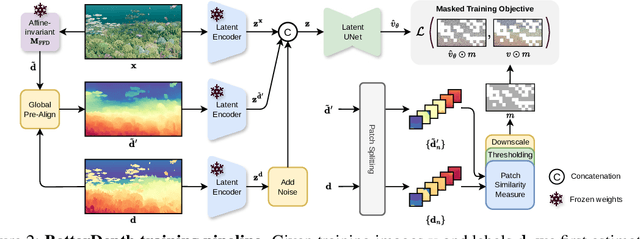
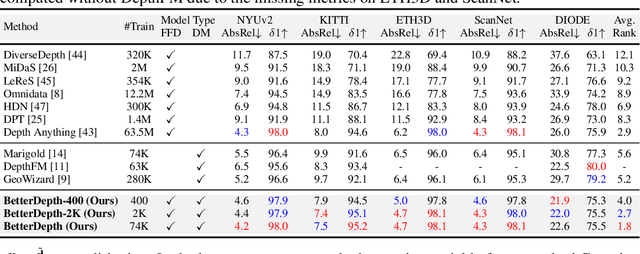
By training over large-scale datasets, zero-shot monocular depth estimation (MDE) methods show robust performance in the wild but often suffer from insufficiently precise details. Although recent diffusion-based MDE approaches exhibit appealing detail extraction ability, they still struggle in geometrically challenging scenes due to the difficulty of gaining robust geometric priors from diverse datasets. To leverage the complementary merits of both worlds, we propose BetterDepth to efficiently achieve geometrically correct affine-invariant MDE performance while capturing fine-grained details. Specifically, BetterDepth is a conditional diffusion-based refiner that takes the prediction from pre-trained MDE models as depth conditioning, in which the global depth context is well-captured, and iteratively refines details based on the input image. For the training of such a refiner, we propose global pre-alignment and local patch masking methods to ensure the faithfulness of BetterDepth to depth conditioning while learning to capture fine-grained scene details. By efficient training on small-scale synthetic datasets, BetterDepth achieves state-of-the-art zero-shot MDE performance on diverse public datasets and in-the-wild scenes. Moreover, BetterDepth can improve the performance of other MDE models in a plug-and-play manner without additional re-training.
Consistency^2: Consistent and Fast 3D Painting with Latent Consistency Models
Jun 17, 2024



Generative 3D Painting is among the top productivity boosters in high-resolution 3D asset management and recycling. Ever since text-to-image models became accessible for inference on consumer hardware, the performance of 3D Painting methods has consistently improved and is currently close to plateauing. At the core of most such models lies denoising diffusion in the latent space, an inherently time-consuming iterative process. Multiple techniques have been developed recently to accelerate generation and reduce sampling iterations by orders of magnitude. Designed for 2D generative imaging, these techniques do not come with recipes for lifting them into 3D. In this paper, we address this shortcoming by proposing a Latent Consistency Model (LCM) adaptation for the task at hand. We analyze the strengths and weaknesses of the proposed model and evaluate it quantitatively and qualitatively. Based on the Objaverse dataset samples study, our 3D painting method attains strong preference in all evaluations. Source code is available at https://github.com/kongdai123/consistency2.
I-Design: Personalized LLM Interior Designer
Apr 03, 2024Interior design allows us to be who we are and live how we want - each design is as unique as our distinct personality. However, it is not trivial for non-professionals to express and materialize this since it requires aligning functional and visual expectations with the constraints of physical space; this renders interior design a luxury. To make it more accessible, we present I-Design, a personalized interior designer that allows users to generate and visualize their design goals through natural language communication. I-Design starts with a team of large language model agents that engage in dialogues and logical reasoning with one another, transforming textual user input into feasible scene graph designs with relative object relationships. Subsequently, an effective placement algorithm determines optimal locations for each object within the scene. The final design is then constructed in 3D by retrieving and integrating assets from an existing object database. Additionally, we propose a new evaluation protocol that utilizes a vision-language model and complements the design pipeline. Extensive quantitative and qualitative experiments show that I-Design outperforms existing methods in delivering high-quality 3D design solutions and aligning with abstract concepts that match user input, showcasing its advantages across detailed 3D arrangement and conceptual fidelity.
Point2Building: Reconstructing Buildings from Airborne LiDAR Point Clouds
Mar 04, 2024



We present a learning-based approach to reconstruct buildings as 3D polygonal meshes from airborne LiDAR point clouds. What makes 3D building reconstruction from airborne LiDAR hard is the large diversity of building designs and especially roof shapes, the low and varying point density across the scene, and the often incomplete coverage of building facades due to occlusions by vegetation or to the viewing angle of the sensor. To cope with the diversity of shapes and inhomogeneous and incomplete object coverage, we introduce a generative model that directly predicts 3D polygonal meshes from input point clouds. Our autoregressive model, called Point2Building, iteratively builds up the mesh by generating sequences of vertices and faces. This approach enables our model to adapt flexibly to diverse geometries and building structures. Unlike many existing methods that rely heavily on pre-processing steps like exhaustive plane detection, our model learns directly from the point cloud data, thereby reducing error propagation and increasing the fidelity of the reconstruction. We experimentally validate our method on a collection of airborne LiDAR data of Zurich, Berlin and Tallinn. Our method shows good generalization to diverse urban styles.
Point2CAD: Reverse Engineering CAD Models from 3D Point Clouds
Dec 07, 2023



Computer-Aided Design (CAD) model reconstruction from point clouds is an important problem at the intersection of computer vision, graphics, and machine learning; it saves the designer significant time when iterating on in-the-wild objects. Recent advancements in this direction achieve relatively reliable semantic segmentation but still struggle to produce an adequate topology of the CAD model. In this work, we analyze the current state of the art for that ill-posed task and identify shortcomings of existing methods. We propose a hybrid analytic-neural reconstruction scheme that bridges the gap between segmented point clouds and structured CAD models and can be readily combined with different segmentation backbones. Moreover, to power the surface fitting stage, we propose a novel implicit neural representation of freeform surfaces, driving up the performance of our overall CAD reconstruction scheme. We extensively evaluate our method on the popular ABC benchmark of CAD models and set a new state-of-the-art for that dataset. Project page: https://www.obukhov.ai/point2cad}{https://www.obukhov.ai/point2cad.