 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Physics Olympiad via Reinforcement Learning on Physics Simulators
Apr 13, 2026We have witnessed remarkable advances in LLM reasoning capabilities with the advent of DeepSeek-R1. However, much of this progress has been fueled by the abundance of internet question-answer (QA) pairs, a major bottleneck going forward, since such data is limited in scale and concentrated mainly in domains like mathematics. In contrast, other sciences such as physics lack large-scale QA datasets to effectively train reasoning-capable models. In this work, we show that physics simulators can serve as a powerful alternative source of supervision for training LLMs for physical reasoning. We generate random scenes in physics engines, create synthetic question-answer pairs from simulated interactions, and train LLMs using reinforcement learning on this synthetic data. Our models exhibit zero-shot sim-to-real transfer to real-world physics benchmarks: for example, training solely on synthetic simulated data improves performance on IPhO (International Physics Olympiad) problems by 5-10 percentage points across model sizes. These results demonstrate that physics simulators can act as scalable data generators, enabling LLMs to acquire deep physical reasoning skills beyond the limitations of internet-scale QA data. Code available at: https://sim2reason.github.io/.
Learning to Assist: Physics-Grounded Human-Human Control via Multi-Agent Reinforcement Learning
Mar 11, 2026Humanoid robotics has strong potential to transform daily service and caregiving applications. Although recent advances in general motion tracking within physics engines (GMT) have enabled virtual characters and humanoid robots to reproduce a broad range of human motions, these behaviors are primarily limited to contact-less social interactions or isolated movements. Assistive scenarios, by contrast, require continuous awareness of a human partner and rapid adaptation to their evolving posture and dynamics. In this paper, we formulate the imitation of closely interacting, force-exchanging human-human motion sequences as a multi-agent reinforcement learning problem. We jointly train partner-aware policies for both the supporter (assistant) agent and the recipient agent in a physics simulator to track assistive motion references. To make this problem tractable, we introduce a partner policies initialization scheme that transfers priors from single-human motion-tracking controllers, greatly improving exploration. We further propose dynamic reference retargeting and contact-promoting reward, which adapt the assistant's reference motion to the recipient's real-time pose and encourage physically meaningful support. We show that AssistMimic is the first method capable of successfully tracking assistive interaction motions on established benchmarks, demonstrating the benefits of a multi-agent RL formulation for physically grounded and socially aware humanoid control.
Dex4D: Task-Agnostic Point Track Policy for Sim-to-Real Dexterous Manipulation
Feb 17, 2026Learning generalist policies capable of accomplishing a plethora of everyday tasks remains an open challenge in dexterous manipulation. In particular, collecting large-scale manipulation data via real-world teleoperation is expensive and difficult to scale. While learning in simulation provides a feasible alternative, designing multiple task-specific environments and rewards for training is similarly challenging. We propose Dex4D, a framework that instead leverages simulation for learning task-agnostic dexterous skills that can be flexibly recomposed to perform diverse real-world manipulation tasks. Specifically, Dex4D learns a domain-agnostic 3D point track conditioned policy capable of manipulating any object to any desired pose. We train this 'Anypose-to-Anypose' policy in simulation across thousands of objects with diverse pose configurations, covering a broad space of robot-object interactions that can be composed at test time. At deployment, this policy can be zero-shot transferred to real-world tasks without finetuning, simply by prompting it with desired object-centric point tracks extracted from generated videos. During execution, Dex4D uses online point tracking for closed-loop perception and control. Extensive experiments in simulation and on real robots show that our method enables zero-shot deployment for diverse dexterous manipulation tasks and yields consistent improvements over prior baselines. Furthermore, we demonstrate strong generalization to novel objects, scene layouts, backgrounds, and trajectories, highlighting the robustness and scalability of the proposed framework.
Iterative Refinement Improves Compositional Image Generation
Jan 21, 2026Text-to-image (T2I) models have achieved remarkable progress, yet they continue to struggle with complex prompts that require simultaneously handling multiple objects, relations, and attributes. Existing inference-time strategies, such as parallel sampling with verifiers or simply increasing denoising steps, can improve prompt alignment but remain inadequate for richly compositional settings where many constraints must be satisfied. Inspired by the success of chain-of-thought reasoning in large language models, we propose an iterative test-time strategy in which a T2I model progressively refines its generations across multiple steps, guided by feedback from a vision-language model as the critic in the loop. Our approach is simple, requires no external tools or priors, and can be flexibly applied to a wide range of image generators and vision-language models. Empirically, we demonstrate consistent gains on image generation across benchmarks: a 16.9% improvement in all-correct rate on ConceptMix (k=7), a 13.8% improvement on T2I-CompBench (3D-Spatial category) and a 12.5% improvement on Visual Jenga scene decomposition compared to compute-matched parallel sampling. Beyond quantitative gains, iterative refinement produces more faithful generations by decomposing complex prompts into sequential corrections, with human evaluators preferring our method 58.7% of the time over 41.3% for the parallel baseline. Together, these findings highlight iterative self-correction as a broadly applicable principle for compositional image generation. Results and visualizations are available at https://iterative-img-gen.github.io/
RoboTAG: End-to-end Robot Configuration Estimation via Topological Alignment Graph
Nov 11, 2025Estimating robot pose from a monocular RGB image is a challenge in robotics and computer vision. Existing methods typically build networks on top of 2D visual backbones and depend heavily on labeled data for training, which is often scarce in real-world scenarios, causing a sim-to-real gap. Moreover, these approaches reduce the 3D-based problem to 2D domain, neglecting the 3D priors. To address these, we propose Robot Topological Alignment Graph (RoboTAG), which incorporates a 3D branch to inject 3D priors while enabling co-evolution of the 2D and 3D representations, alleviating the reliance on labels. Specifically, the RoboTAG consists of a 3D branch and a 2D branch, where nodes represent the states of the camera and robot system, and edges capture the dependencies between these variables or denote alignments between them. Closed loops are then defined in the graph, on which a consistency supervision across branches can be applied. This design allows us to utilize in-the-wild images as training data without annotations. Experimental results demonstrate that our method is effective across robot types, highlighting its potential to alleviate the data bottleneck in robotics.
Generative 4D Scene Gaussian Splatting with Object View-Synthesis Priors
Jun 15, 2025We tackle the challenge of generating dynamic 4D scenes from monocular, multi-object videos with heavy occlusions, and introduce GenMOJO, a novel approach that integrates rendering-based deformable 3D Gaussian optimization with generative priors for view synthesis. While existing models perform well on novel view synthesis for isolated objects, they struggle to generalize to complex, cluttered scenes. To address this, GenMOJO decomposes the scene into individual objects, optimizing a differentiable set of deformable Gaussians per object. This object-wise decomposition allows leveraging object-centric diffusion models to infer unobserved regions in novel viewpoints. It performs joint Gaussian splatting to render the full scene, capturing cross-object occlusions, and enabling occlusion-aware supervision. To bridge the gap between object-centric priors and the global frame-centric coordinate system of videos, GenMOJO uses differentiable transformations that align generative and rendering constraints within a unified framework. The resulting model generates 4D object reconstructions over space and time, and produces accurate 2D and 3D point tracks from monocular input. Quantitative evaluations and perceptual human studies confirm that GenMOJO generates more realistic novel views of scenes and produces more accurate point tracks compared to existing approaches.
AllTracker: Efficient Dense Point Tracking at High Resolution
Jun 08, 2025We introduce AllTracker: a model that estimates long-range point tracks by way of estimating the flow field between a query frame and every other frame of a video. Unlike existing point tracking methods, our approach delivers high-resolution and dense (all-pixel) correspondence fields, which can be visualized as flow maps. Unlike existing optical flow methods, our approach corresponds one frame to hundreds of subsequent frames, rather than just the next frame. We develop a new architecture for this task, blending techniques from existing work in optical flow and point tracking: the model performs iterative inference on low-resolution grids of correspondence estimates, propagating information spatially via 2D convolution layers, and propagating information temporally via pixel-aligned attention layers. The model is fast and parameter-efficient (16 million parameters), and delivers state-of-the-art point tracking accuracy at high resolution (i.e., tracking 768x1024 pixels, on a 40G GPU). A benefit of our design is that we can train on a wider set of datasets, and we find that doing so is crucial for top performance. We provide an extensive ablation study on our architecture details and training recipe, making it clear which details matter most. Our code and model weights are available at https://alltracker.github.io .
PartCrafter: Structured 3D Mesh Generation via Compositional Latent Diffusion Transformers
Jun 05, 2025We introduce PartCrafter, the first structured 3D generative model that jointly synthesizes multiple semantically meaningful and geometrically distinct 3D meshes from a single RGB image. Unlike existing methods that either produce monolithic 3D shapes or follow two-stage pipelines, i.e., first segmenting an image and then reconstructing each segment, PartCrafter adopts a unified, compositional generation architecture that does not rely on pre-segmented inputs. Conditioned on a single image, it simultaneously denoises multiple 3D parts, enabling end-to-end part-aware generation of both individual objects and complex multi-object scenes. PartCrafter builds upon a pretrained 3D mesh diffusion transformer (DiT) trained on whole objects, inheriting the pretrained weights, encoder, and decoder, and introduces two key innovations: (1) A compositional latent space, where each 3D part is represented by a set of disentangled latent tokens; (2) A hierarchical attention mechanism that enables structured information flow both within individual parts and across all parts, ensuring global coherence while preserving part-level detail during generation. To support part-level supervision, we curate a new dataset by mining part-level annotations from large-scale 3D object datasets. Experiments show that PartCrafter outperforms existing approaches in generating decomposable 3D meshes, including parts that are not directly visible in input images, demonstrating the strength of part-aware generative priors for 3D understanding and synthesis. Code and training data will be released.
Maximizing Confidence Alone Improves Reasoning
May 29, 2025Reinforcement learning (RL) has enabled machine learning models to achieve significant advances in many fields. Most recently, RL has empowered frontier language models to solve challenging math, science, and coding problems. However, central to any RL algorithm is the reward function, and reward engineering is a notoriously difficult problem in any domain. In this paper, we propose RENT: Reinforcement Learning via Entropy Minimization -- a fully unsupervised RL method that requires no external reward or ground-truth answers, and instead uses the model's entropy of its underlying distribution as an intrinsic reward. We find that by reinforcing the chains of thought that yield high model confidence on its generated answers, the model improves its reasoning ability. In our experiments, we showcase these improvements on an extensive suite of commonly-used reasoning benchmarks, including GSM8K, MATH500, AMC, AIME, and GPQA, and models of varying sizes from the Qwen and Mistral families. The generality of our unsupervised learning method lends itself to applicability in a wide range of domains where external supervision is unavailable.
Grounded Reinforcement Learning for Visual Reasoning
May 29, 2025
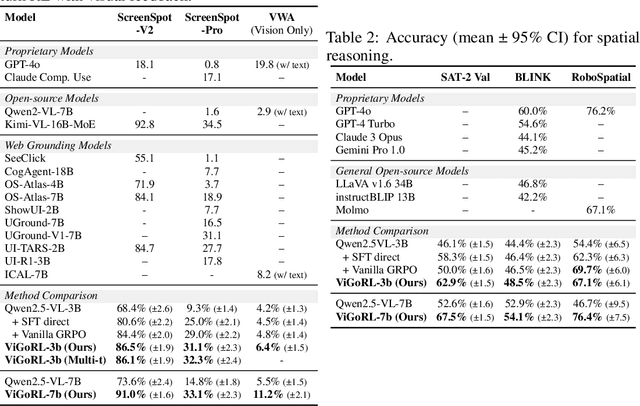
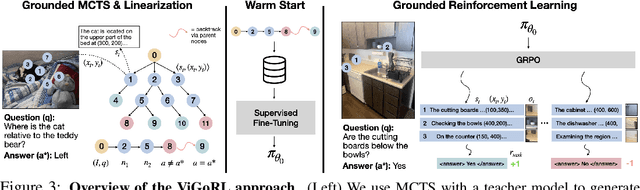

While reinforcement learning (RL) over chains of thought has significantly advanced language models in tasks such as mathematics and coding, visual reasoning introduces added complexity by requiring models to direct visual attention, interpret perceptual inputs, and ground abstract reasoning in spatial evidence. We introduce ViGoRL (Visually Grounded Reinforcement Learning), a vision-language model trained with RL to explicitly anchor each reasoning step to specific visual coordinates. Inspired by human visual decision-making, ViGoRL learns to produce spatially grounded reasoning traces, guiding visual attention to task-relevant regions at each step. When fine-grained exploration is required, our novel multi-turn RL framework enables the model to dynamically zoom into predicted coordinates as reasoning unfolds. Across a diverse set of visual reasoning benchmarks--including SAT-2 and BLINK for spatial reasoning, V*bench for visual search, and ScreenSpot and VisualWebArena for web-based grounding--ViGoRL consistently outperforms both supervised fine-tuning and conventional RL baselines that lack explicit grounding mechanisms. Incorporating multi-turn RL with zoomed-in visual feedback significantly improves ViGoRL's performance on localizing small GUI elements and visual search, achieving 86.4% on V*Bench. Additionally, we find that grounding amplifies other visual behaviors such as region exploration, grounded subgoal setting, and visual verification. Finally, human evaluations show that the model's visual references are not only spatially accurate but also helpful for understanding model reasoning steps. Our results show that visually grounded RL is a strong paradigm for imbuing models with general-purpose visual reasoning.