 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Restoration via Diffusion Models with Dynamic Resolution
May 14, 2026Diffusion models (DMs) have exhibited remarkable efficacy in various image restoration tasks. However, existing approaches typically operate within the high-dimensional pixel space, resulting in high computational overhead. While methods based on latent DMs seek to alleviate this issue by utilizing the compressed latent space of a variational autoencoder, they require repeated encoder-decoder inference. This introduces significant additional computational burdens, often resulting in runtime performance that is even inferior to that of their pixel-space counterparts. To mitigate the computational inefficiency, this work proposes projecting data into lower-dimensional subspaces using dynamic resolution DMs to accelerate the inference process. We first fine-tune pre-trained DMs for dynamic resolution priors and adapt DPS and DAPS, which are two widely used pixel-space methods for general image restoration tasks, into the proposed framework, yielding methods we refer to as SubDPS and SubDAPS, respectively. Given the favorable inference speed and reconstruction fidelity of SubDAPS, we introduce an enhanced variant termed SubDAPS++ to further boost both reconstruction efficiency and quality. Empirical evaluations across diverse image datasets and various restoration tasks demonstrate that the proposed methods outperform recent DM-based approaches in the majority of experimental scenarios. The code is available at https://github.com/StarNextDay/SubDAPS.git.
Outlier-Robust Diffusion Solvers for Inverse Problems
May 10, 2026Methods based on diffusion models (DMs) for solving inverse problems (IPs) have recently achieved remarkable performance. However, DM-based methods typically struggle against outliers, which are common in real-world measurements. In this work, to tackle IPs with outliers, we first refine the measurement via explicit noise estimation to mitigate the effect of noise. Subsequently, we formulate an iteratively reweighted least squares objective based on the Huber loss to address the outliers. We propose a method utilizing gradient descent to approximately solve the corresponding optimization problem for the robust objective. To avoid delicate tuning of the learning rate required by the gradient descent method, we further employ the conjugate gradient method with an efficient strategy for updating. Extensive experiments on multiple image datasets for linear and nonlinear tasks under various conditions demonstrate that our proposed methods exhibit robustness to outliers and outperform recent DM-based methods in most cases.
Online Nonstochastic Prediction: Logarithmic Regret via Predictive Online Least Squares
May 06, 2026We study online prediction for marginally stable, partially observed linear dynamical systems under nonstochastic disturbances. Our objective is to minimize the cumulative squared prediction loss and compete with the best-in-hindsight Luenberger predictor. Standard online learning methods typically rely on bounded domains/gradients, and thus their guarantees may fail to deal with potentially unbounded trajectories in marginally stable systems. In this paper, we introduce an unconstrained online least squares method that stabilizes the learning process via tailored predictive hints. With model knowledge, we prove that hints constructed from any stabilizing Luenberger predictor render the hint residuals uniformly bounded, achieving logarithmic regret despite unbounded trajectory growth. We also discuss model-free prediction and introduce a simple universal hint for symmetric systems, under which logarithmic regret is maintained without model knowledge. Our results provide an adaptive, instance-wise optimal online predictor compared to classical fixed-gain observers under nonstochastic disturbances.
Fast and Accurate Probing of In-Training LLMs' Downstream Performances
Apr 01, 2026The paradigm of scaling Large Language Models (LLMs) in both parameter size and test time has pushed the boundaries of AI capabilities, but at the cost of making the traditional generative evaluation paradigm prohibitively expensive, therefore making the latency of LLM's in-training downstream performance evaluation unbearable. However, simple metrics like training loss (perplexity) are not always correlated with downstream performance, as sometimes their trends diverge from the actual task outcomes. This dilemma calls for a method that is computationally efficient and sufficiently accurate in measuring model capabilities. To address this challenge, we introduce a new in-training evaluation paradigm that uses a lightweight probe for monitoring downstream performance. The probes take the internal representations of LLM checkpoints (during training) as input and directly predict the checkpoint's performance on downstream tasks measured by success probability (i.e., pass@1). We design several probe architectures, validating their effectiveness using the OLMo3-7B's checkpoints across a diverse set of downstream tasks. The probes can accurately predict a checkpoint's performance (with avg. AUROC$>$0.75), have decent generalizability across checkpoints (earlier predicts later), and reduce the computation latency from $\sim$1 hr (using conventional generative evaluation method) to $\sim$3 min. In sum, this work presents a practical and scalable in-training downstream evaluation paradigm, enabling a more agile, informed, and efficient LLM development process.
On the Spectral Flattening of Quantized Embeddings
Feb 01, 2026Training Large Language Models (LLMs) at ultra-low precision is critically impeded by instability rooted in the conflict between discrete quantization constraints and the intrinsic heavy-tailed spectral nature of linguistic data. By formalizing the connection between Zipfian statistics and random matrix theory, we prove that the power-law decay in the singular value spectra of embeddings is a fundamental requisite for semantic encoding. We derive theoretical bounds showing that uniform quantization introduces a noise floor that disproportionately truncates this spectral tail, which induces spectral flattening and a strictly provable increase in the stable rank of representations. Empirical validation across diverse architectures including GPT-2 and TinyLlama corroborates that this geometric degradation precipitates representational collapse. This work not only quantifies the spectral sensitivity of LLMs but also establishes spectral fidelity as a necessary condition for stable low-bit optimization.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
Image2Garment: Simulation-ready Garment Generation from a Single Image
Jan 15, 2026Estimating physically accurate, simulation-ready garments from a single image is challenging due to the absence of image-to-physics datasets and the ill-posed nature of this problem. Prior methods either require multi-view capture and expensive differentiable simulation or predict only garment geometry without the material properties required for realistic simulation. We propose a feed-forward framework that sidesteps these limitations by first fine-tuning a vision-language model to infer material composition and fabric attributes from real images, and then training a lightweight predictor that maps these attributes to the corresponding physical fabric parameters using a small dataset of material-physics measurements. Our approach introduces two new datasets (FTAG and T2P) and delivers simulation-ready garments from a single image without iterative optimization. Experiments show that our estimator achieves superior accuracy in material composition estimation and fabric attribute prediction, and by passing them through our physics parameter estimator, we further achieve higher-fidelity simulations compared to state-of-the-art image-to-garment methods.
Bridging Semantics and Geometry: A Decoupled LVLM-SAM Framework for Reasoning Segmentation in Remote Sensing
Dec 22, 2025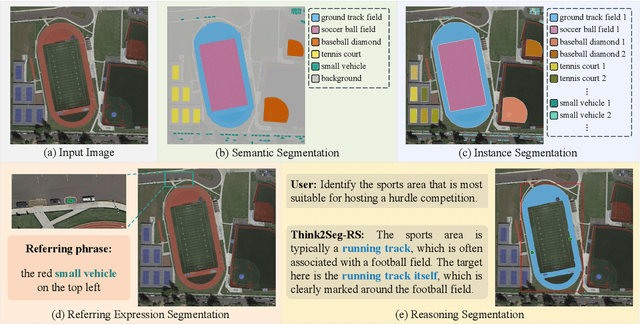
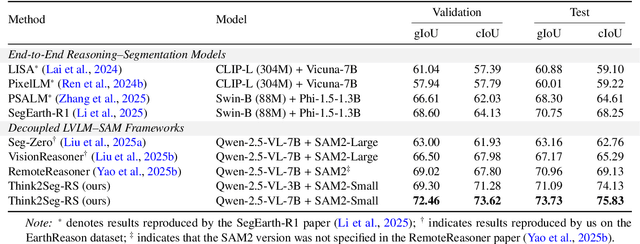
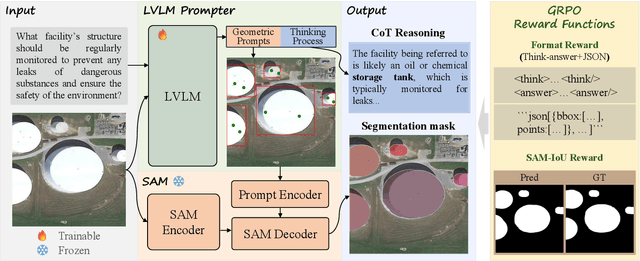
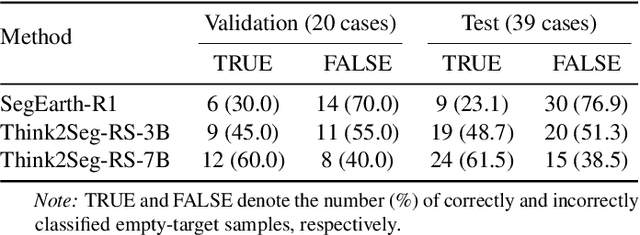
Large Vision-Language Models (LVLMs) hold great promise for advancing remote sensing (RS) analysis, yet existing reasoning segmentation frameworks couple linguistic reasoning and pixel prediction through end-to-end supervised fine-tuning, leading to weak geometric grounding and limited generalization across tasks. To address this, we developed Think2Seg-RS, a decoupled framework that trains an LVLM prompter to control a frozen Segment Anything Model (SAM) via structured geometric prompts. Through a mask-only reinforcement learning objective, the LVLM learns to translate abstract semantic reasoning into spatially grounded actions, achieving state-of-the-art performance on the EarthReason dataset. Remarkably, the learned prompting policy generalizes zero-shot to multiple referring segmentation benchmarks, exposing a distinct divide between semantic-level and instance-level grounding. We further found that compact segmenters outperform larger ones under semantic-level supervision, and that negative prompts are ineffective in heterogeneous aerial backgrounds. Together, these findings establish semantic-level reasoning segmentation as a new paradigm for geospatial understanding, opening the way toward unified, interpretable LVLM-driven Earth observation. Our code and model are available at https://github.com/Ricardo-XZ/Think2Seg-RS.
Logarithmic Regret and Polynomial Scaling in Online Multi-step-ahead Prediction
Nov 16, 2025This letter studies the problem of online multi-step-ahead prediction for unknown linear stochastic systems. Using conditional distribution theory, we derive an optimal parameterization of the prediction policy as a linear function of future inputs, past inputs, and past outputs. Based on this characterization, we propose an online least-squares algorithm to learn the policy and analyze its regret relative to the optimal model-based predictor. We show that the online algorithm achieves logarithmic regret with respect to the optimal Kalman filter in the multi-step setting. Furthermore, with new proof techniques, we establish an almost-sure regret bound that does not rely on fixed failure probabilities for sufficiently large horizons $N$. Finally, our analysis also reveals that, while the regret remains logarithmic in $N$, its constant factor grows polynomially with the prediction horizon $H$, with the polynomial order set by the largest Jordan block of eigenvalue 1 in the system matrix.
Breaking Thought Patterns: A Multi-Dimensional Reasoning Framework for LLMs
Jun 16, 2025Large language models (LLMs) are often constrained by rigid reasoning processes, limiting their ability to generate creative and diverse responses. To address this, a novel framework called LADDER is proposed, combining Chain-of-Thought (CoT) reasoning, Mixture of Experts (MoE) models, and multi-dimensional up/down-sampling strategies which breaks the limitations of traditional LLMs. First, CoT reasoning guides the model through multi-step logical reasoning, expanding the semantic space and breaking the rigidity of thought. Next, MoE distributes the reasoning tasks across multiple expert modules, each focusing on specific sub-tasks. Finally, dimensionality reduction maps the reasoning outputs back to a lower-dimensional semantic space, yielding more precise and creative responses. Extensive experiments across multiple tasks demonstrate that LADDER significantly improves task completion, creativity, and fluency, generating innovative and coherent responses that outperform traditional models. Ablation studies reveal the critical roles of CoT and MoE in enhancing reasoning abilities and creative output. This work contributes to the development of more flexible and creative LLMs, capable of addressing complex and novel tasks.