 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGAF: Gaussian Action Field as a Dvnamic World Model for Robotic Mlanipulation
Jun 17, 2025



Accurate action inference is critical for vision-based robotic manipulation. Existing approaches typically follow either a Vision-to-Action (V-A) paradigm, predicting actions directly from visual inputs, or a Vision-to-3D-to-Action (V-3D-A) paradigm, leveraging intermediate 3D representations. However, these methods often struggle with action inaccuracies due to the complexity and dynamic nature of manipulation scenes. In this paper, we propose a V-4D-A framework that enables direct action reasoning from motion-aware 4D representations via a Gaussian Action Field (GAF). GAF extends 3D Gaussian Splatting (3DGS) by incorporating learnable motion attributes, allowing simultaneous modeling of dynamic scenes and manipulation actions. To learn time-varying scene geometry and action-aware robot motion, GAF supports three key query types: reconstruction of the current scene, prediction of future frames, and estimation of initial action via robot motion. Furthermore, the high-quality current and future frames generated by GAF facilitate manipulation action refinement through a GAF-guided diffusion model. Extensive experiments demonstrate significant improvements, with GAF achieving +11.5385 dB PSNR and -0.5574 LPIPS improvements in reconstruction quality, while boosting the average success rate in robotic manipulation tasks by 10.33% over state-of-the-art methods. Project page: http://chaiying1.github.io/GAF.github.io/project_page/
Interspatial Attention for Efficient 4D Human Video Generation
May 21, 2025



Generating photorealistic videos of digital humans in a controllable manner is crucial for a plethora of applications. Existing approaches either build on methods that employ template-based 3D representations or emerging video generation models but suffer from poor quality or limited consistency and identity preservation when generating individual or multiple digital humans. In this paper, we introduce a new interspatial attention (ISA) mechanism as a scalable building block for modern diffusion transformer (DiT)--based video generation models. ISA is a new type of cross attention that uses relative positional encodings tailored for the generation of human videos. Leveraging a custom-developed video variation autoencoder, we train a latent ISA-based diffusion model on a large corpus of video data. Our model achieves state-of-the-art performance for 4D human video synthesis, demonstrating remarkable motion consistency and identity preservation while providing precise control of the camera and body poses. Our code and model are publicly released at https://dsaurus.github.io/isa4d/.
ManiVideo: Generating Hand-Object Manipulation Video with Dexterous and Generalizable Grasping
Dec 18, 2024



In this paper, we introduce ManiVideo, a novel method for generating consistent and temporally coherent bimanual hand-object manipulation videos from given motion sequences of hands and objects. The core idea of ManiVideo is the construction of a multi-layer occlusion (MLO) representation that learns 3D occlusion relationships from occlusion-free normal maps and occlusion confidence maps. By embedding the MLO structure into the UNet in two forms, the model enhances the 3D consistency of dexterous hand-object manipulation. To further achieve the generalizable grasping of objects, we integrate Objaverse, a large-scale 3D object dataset, to address the scarcity of video data, thereby facilitating the learning of extensive object consistency. Additionally, we propose an innovative training strategy that effectively integrates multiple datasets, supporting downstream tasks such as human-centric hand-object manipulation video generation. Through extensive experiments, we demonstrate that our approach not only achieves video generation with plausible hand-object interaction and generalizable objects, but also outperforms existing SOTA methods.
The Language of Motion: Unifying Verbal and Non-verbal Language of 3D Human Motion
Dec 13, 2024Human communication is inherently multimodal, involving a combination of verbal and non-verbal cues such as speech, facial expressions, and body gestures. Modeling these behaviors is essential for understanding human interaction and for creating virtual characters that can communicate naturally in applications like games, films, and virtual reality. However, existing motion generation models are typically limited to specific input modalities -- either speech, text, or motion data -- and cannot fully leverage the diversity of available data. In this paper, we propose a novel framework that unifies verbal and non-verbal language using multimodal language models for human motion understanding and generation. This model is flexible in taking text, speech, and motion or any combination of them as input. Coupled with our novel pre-training strategy, our model not only achieves state-of-the-art performance on co-speech gesture generation but also requires much less data for training. Our model also unlocks an array of novel tasks such as editable gesture generation and emotion prediction from motion. We believe unifying the verbal and non-verbal language of human motion is essential for real-world applications, and language models offer a powerful approach to achieving this goal. Project page: languageofmotion.github.io.
DreamCraft3D++: Efficient Hierarchical 3D Generation with Multi-Plane Reconstruction Model
Oct 16, 2024
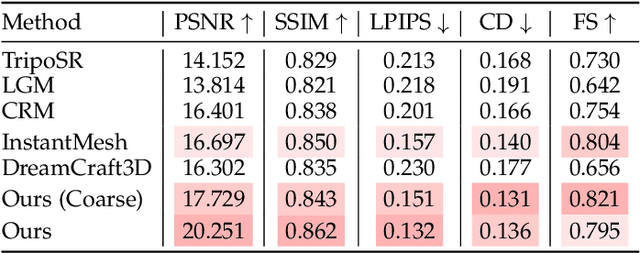


We introduce DreamCraft3D++, an extension of DreamCraft3D that enables efficient high-quality generation of complex 3D assets. DreamCraft3D++ inherits the multi-stage generation process of DreamCraft3D, but replaces the time-consuming geometry sculpting optimization with a feed-forward multi-plane based reconstruction model, speeding up the process by 1000x. For texture refinement, we propose a training-free IP-Adapter module that is conditioned on the enhanced multi-view images to enhance texture and geometry consistency, providing a 4x faster alternative to DreamCraft3D's DreamBooth fine-tuning. Experiments on diverse datasets demonstrate DreamCraft3D++'s ability to generate creative 3D assets with intricate geometry and realistic 360{\deg} textures, outperforming state-of-the-art image-to-3D methods in quality and speed. The full implementation will be open-sourced to enable new possibilities in 3D content creation.
HHMR: Holistic Hand Mesh Recovery by Enhancing the Multimodal Controllability of Graph Diffusion Models
Jun 03, 2024Recent years have witnessed a trend of the deep integration of the generation and reconstruction paradigms. In this paper, we extend the ability of controllable generative models for a more comprehensive hand mesh recovery task: direct hand mesh generation, inpainting, reconstruction, and fitting in a single framework, which we name as Holistic Hand Mesh Recovery (HHMR). Our key observation is that different kinds of hand mesh recovery tasks can be achieved by a single generative model with strong multimodal controllability, and in such a framework, realizing different tasks only requires giving different signals as conditions. To achieve this goal, we propose an all-in-one diffusion framework based on graph convolution and attention mechanisms for holistic hand mesh recovery. In order to achieve strong control generation capability while ensuring the decoupling of multimodal control signals, we map different modalities to a shared feature space and apply cross-scale random masking in both modality and feature levels. In this way, the correlation between different modalities can be fully exploited during the learning of hand priors. Furthermore, we propose Condition-aligned Gradient Guidance to enhance the alignment of the generated model with the control signals, which significantly improves the accuracy of the hand mesh reconstruction and fitting. Experiments show that our novel framework can realize multiple hand mesh recovery tasks simultaneously and outperform the existing methods in different tasks, which provides more possibilities for subsequent downstream applications including gesture recognition, pose generation, mesh editing, and so on.
Human4DiT: Free-view Human Video Generation with 4D Diffusion Transformer
May 27, 2024
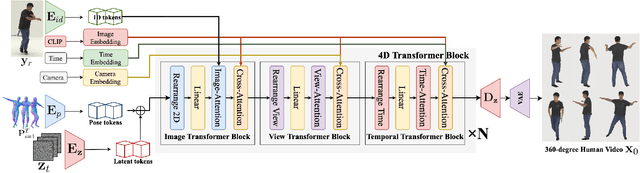
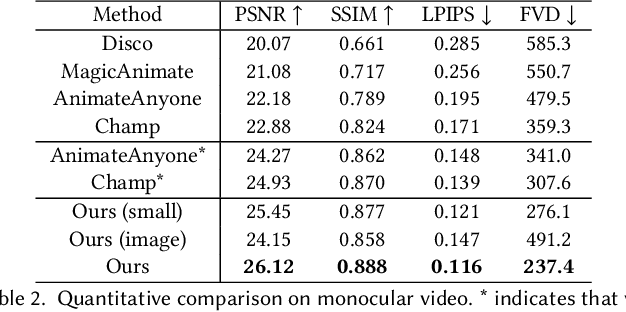
We present a novel approach for generating high-quality, spatio-temporally coherent human videos from a single image under arbitrary viewpoints. Our framework combines the strengths of U-Nets for accurate condition injection and diffusion transformers for capturing global correlations across viewpoints and time. The core is a cascaded 4D transformer architecture that factorizes attention across views, time, and spatial dimensions, enabling efficient modeling of the 4D space. Precise conditioning is achieved by injecting human identity, camera parameters, and temporal signals into the respective transformers. To train this model, we curate a multi-dimensional dataset spanning images, videos, multi-view data and 3D/4D scans, along with a multi-dimensional training strategy. Our approach overcomes the limitations of previous methods based on GAN or UNet-based diffusion models, which struggle with complex motions and viewpoint changes. Through extensive experiments, we demonstrate our method's ability to synthesize realistic, coherent and free-view human videos, paving the way for advanced multimedia applications in areas such as virtual reality and animation. Our project website is https://human4dit.github.io.
Tele-Aloha: A Low-budget and High-authenticity Telepresence System Using Sparse RGB Cameras
May 23, 2024
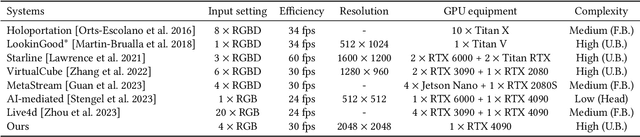

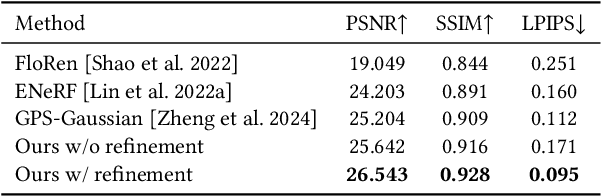
In this paper, we present a low-budget and high-authenticity bidirectional telepresence system, Tele-Aloha, targeting peer-to-peer communication scenarios. Compared to previous systems, Tele-Aloha utilizes only four sparse RGB cameras, one consumer-grade GPU, and one autostereoscopic screen to achieve high-resolution (2048x2048), real-time (30 fps), low-latency (less than 150ms) and robust distant communication. As the core of Tele-Aloha, we propose an efficient novel view synthesis algorithm for upper-body. Firstly, we design a cascaded disparity estimator for obtaining a robust geometry cue. Additionally a neural rasterizer via Gaussian Splatting is introduced to project latent features onto target view and to decode them into a reduced resolution. Further, given the high-quality captured data, we leverage weighted blending mechanism to refine the decoded image into the final resolution of 2K. Exploiting world-leading autostereoscopic display and low-latency iris tracking, users are able to experience a strong three-dimensional sense even without any wearable head-mounted display device. Altogether, our telepresence system demonstrates the sense of co-presence in real-life experiments, inspiring the next generation of communication.
Ins-HOI: Instance Aware Human-Object Interactions Recovery
Dec 15, 2023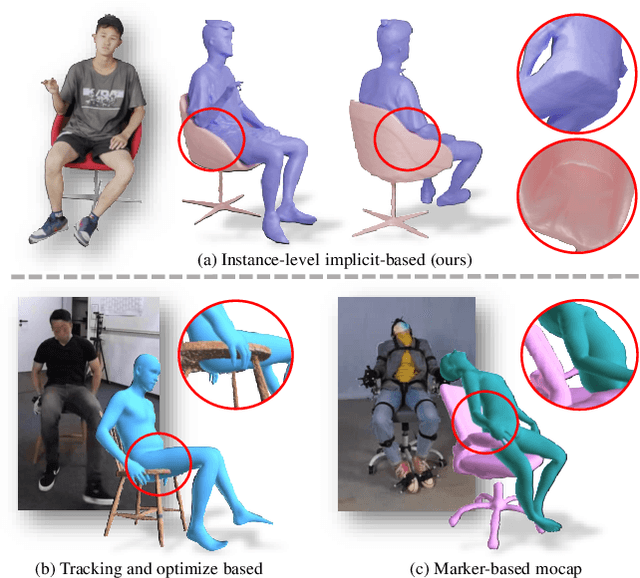



Recovering detailed interactions between humans/hands and objects is an appealing yet challenging task. Existing methods typically use template-based representations to track human/hand and objects in interactions. Despite the progress, they fail to handle the invisible contact surfaces. In this paper, we propose Ins-HOI, an end-to-end solution to recover human/hand-object reconstruction via instance-level implicit reconstruction. To this end, we introduce an instance-level occupancy field to support simultaneous human/hand and object representation, and a complementary training strategy to handle the lack of instance-level ground truths. Such a representation enables learning a contact prior implicitly from sparse observations. During the complementary training, we augment the real-captured data with synthesized data by randomly composing individual scans of humans/hands and objects and intentionally allowing for penetration. In this way, our network learns to recover individual shapes as completely as possible from the synthesized data, while being aware of the contact constraints and overall reasonability based on real-captured scans. As demonstrated in experiments, our method Ins-HOI can produce reasonable and realistic non-visible contact surfaces even in cases of extremely close interaction. To facilitate the research of this task, we collect a large-scale, high-fidelity 3D scan dataset, including 5.2k high-quality scans with real-world human-chair and hand-object interactions. We will release our dataset and source codes. Data examples and the video results of our method can be found on the project page.
HumanCoser: Layered 3D Human Generation via Semantic-Aware Diffusion Model
Dec 10, 2023The generation of 3D clothed humans has attracted increasing attention in recent years. However, existing work cannot generate layered high-quality 3D humans with consistent body structures. As a result, these methods are unable to arbitrarily and separately change and edit the body and clothing of the human. In this paper, we propose a text-driven layered 3D human generation framework based on a novel physically-decoupled semantic-aware diffusion model. To keep the generated clothing consistent with the target text, we propose a semantic-confidence strategy for clothing that can eliminate the non-clothing content generated by the model. To match the clothing with different body shapes, we propose a SMPL-driven implicit field deformation network that enables the free transfer and reuse of clothing. Besides, we introduce uniform shape priors based on the SMPL model for body and clothing, respectively, which generates more diverse 3D content without being constrained by specific templates. The experimental results demonstrate that the proposed method not only generates 3D humans with consistent body structures but also allows free editing in a layered manner. The source code will be made public.