 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMix3R: Mixing Feed-forward Reconstruction and Generative 3D Priors for Joint Multi-view Aligned 3D Reconstruction and Pose Estimation
May 05, 2026Recent trends in sparse-view 3D reconstruction have taken two different paths: feed-forward reconstruction that predicts pixel-aligned point maps without a complete geometry, and generative 3D reconstruction that generates complete geometry but often with poor input-alignment. We present Mix3R, a novel generative 3D reconstruction method which mixes feed-forward reconstruction and 3D generation into a single framework in an aligned manner. Mix3R generates a 3D shape in two stages: a sparse voxel generation stage and a textured geometry generation stage. Unlike pure generative methods, our first-stage generation jointly produces a coarse 3D structure (sparse voxels), per-view point maps and camera parameters aligned to that 3D structure. This is made possible by introducing a Mixture-of-Transformers architecture that inserts global self-attentions to a feed-forward reconstruction model and a 3D generative model, both pretrained on large-scale data. This design effectively retains the pretrained priors but enables better 2D-3D alignment. Based on the initial aligned generations of sparse 3D voxels and point maps, we compute an overlap-based attention bias that is directly added to another pretrained textured geometry generation model, enabling it to correctly place input textures onto generated shapes in a training-free manner. Our design brings mutual benefits to both feed-forward reconstruction and 3D generation: The feed-forward branch learns to ground its predictions to a generative 3D prior, and conversely, the 3D generation branch is conditioned on geometrically informative features from the feed-forward branch. As a result, our method produces 3D shapes with better input alignment compared with pure 3D generative methods, together with camera pose estimations more accurate than previous feed-forward reconstruction methods. Our project page is at https://jsnln.github.io/mix3r/
SynAgent: Generalizable Cooperative Humanoid Manipulation via Solo-to-Cooperative Agent Synergy
Apr 20, 2026Controllable cooperative humanoid manipulation is a fundamental yet challenging problem for embodied intelligence, due to severe data scarcity, complexities in multi-agent coordination, and limited generalization across objects. In this paper, we present SynAgent, a unified framework that enables scalable and physically plausible cooperative manipulation by leveraging Solo-to-Cooperative Agent Synergy to transfer skills from single-agent human-object interaction to multi-agent human-object-human scenarios. To maintain semantic integrity during motion transfer, we introduce an interaction-preserving retargeting method based on an Interact Mesh constructed via Delaunay tetrahedralization, which faithfully maintains spatial relationships among humans and objects. Building upon this refined data, we propose a single-agent pretraining and adaptation paradigm that bootstraps synergistic collaborative behaviors from abundant single-human data through decentralized training and multi-agent PPO. Finally, we develop a trajectory-conditioned generative policy using a conditional VAE, trained via multi-teacher distillation from motion imitation priors to achieve stable and controllable object-level trajectory execution. Extensive experiments demonstrate that SynAgent significantly outperforms existing baselines in both cooperative imitation and trajectory-conditioned control, while generalizing across diverse object geometries. Codes and data will be available after publication. Project Page: http://yw0208.github.io/synagent
4DEquine: Disentangling Motion and Appearance for 4D Equine Reconstruction from Monocular Video
Mar 10, 20264D reconstruction of equine family (e.g. horses) from monocular video is important for animal welfare. Previous mainstream 4D animal reconstruction methods require joint optimization of motion and appearance over a whole video, which is time-consuming and sensitive to incomplete observation. In this work, we propose a novel framework called 4DEquine by disentangling the 4D reconstruction problem into two sub-problems: dynamic motion reconstruction and static appearance reconstruction. For motion, we introduce a simple yet effective spatio-temporal transformer with a post-optimization stage to regress smooth and pixel-aligned pose and shape sequences from video. For appearance, we design a novel feed-forward network that reconstructs a high-fidelity, animatable 3D Gaussian avatar from as few as a single image. To assist training, we create a large-scale synthetic motion dataset, VarenPoser, which features high-quality surface motions and diverse camera trajectories, as well as a synthetic appearance dataset, VarenTex, comprising realistic multi-view images generated through multi-view diffusion. While training only on synthetic datasets, 4DEquine achieves state-of-the-art performance on real-world APT36K and AiM datasets, demonstrating the superiority of 4DEquine and our new datasets for both geometry and appearance reconstruction. Comprehensive ablation studies validate the effectiveness of both the motion and appearance reconstruction network. Project page: https://luoxue-star.github.io/4DEquine_Project_Page/.
GeoDiff4D: Geometry-Aware Diffusion for 4D Head Avatar Reconstruction
Feb 27, 2026Reconstructing photorealistic and animatable 4D head avatars from a single portrait image remains a fundamental challenge in computer vision. While diffusion models have enabled remarkable progress in image and video generation for avatar reconstruction, existing methods primarily rely on 2D priors and struggle to achieve consistent 3D geometry. We propose a novel framework that leverages geometry-aware diffusion to learn strong geometry priors for high-fidelity head avatar reconstruction. Our approach jointly synthesizes portrait images and corresponding surface normals, while a pose-free expression encoder captures implicit expression representations. Both synthesized images and expression latents are incorporated into 3D Gaussian-based avatars, enabling photorealistic rendering with accurate geometry. Extensive experiments demonstrate that our method substantially outperforms state-of-the-art approaches in visual quality, expression fidelity, and cross-identity generalization, while supporting real-time rendering.
U-Mind: A Unified Framework for Real-Time Multimodal Interaction with Audiovisual Generation
Feb 27, 2026Full-stack multimodal interaction in real-time is a central goal in building intelligent embodied agents capable of natural, dynamic communication. However, existing systems are either limited to unimodal generation or suffer from degraded reasoning and poor cross-modal alignment, preventing coherent and perceptually grounded interactions. In this work, we introduce U-Mind, the first unified system for high-intelligence multimodal dialogue that supports real-time generation and jointly models language, speech, motion, and video synthesis within a single interactive loop. At its core, U-Mind implements a Unified Alignment and Reasoning Framework that addresses two key challenges: enhancing cross-modal synchronization via a segment-wise alignment strategy, and preserving reasoning abilities through Rehearsal-Driven Learning. During inference, U-Mind adopts a text-first decoding pipeline that performs internal chain-of-thought planning followed by temporally synchronized generation across modalities. To close the loop, we implement a real-time video rendering framework conditioned on pose and speech, enabling expressive and synchronized visual feedback. Extensive experiments demonstrate that U-Mind achieves state-of-the-art performance on a range of multimodal interaction tasks, including question answering, instruction following, and motion generation, paving the way toward intelligent, immersive conversational agents.
Monocular Mesh Recovery and Body Measurement of Female Saanen Goats
Feb 23, 2026The lactation performance of Saanen dairy goats, renowned for their high milk yield, is intrinsically linked to their body size, making accurate 3D body measurement essential for assessing milk production potential, yet existing reconstruction methods lack goat-specific authentic 3D data. To address this limitation, we establish the FemaleSaanenGoat dataset containing synchronized eight-view RGBD videos of 55 female Saanen goats (6-18 months). Using multi-view DynamicFusion, we fuse noisy, non-rigid point cloud sequences into high-fidelity 3D scans, overcoming challenges from irregular surfaces and rapid movement. Based on these scans, we develop SaanenGoat, a parametric 3D shape model specifically designed for female Saanen goats. This model features a refined template with 41 skeletal joints and enhanced udder representation, registered with our scan data. A comprehensive shape space constructed from 48 goats enables precise representation of diverse individual variations. With the help of SaanenGoat model, we get high-precision 3D reconstruction from single-view RGBD input, and achieve automated measurement of six critical body dimensions: body length, height, chest width, chest girth, hip width, and hip height. Experimental results demonstrate the superior accuracy of our method in both 3D reconstruction and body measurement, presenting a novel paradigm for large-scale 3D vision applications in precision livestock farming.
SharpTimeGS: Sharp and Stable Dynamic Gaussian Splatting via Lifespan Modulation
Feb 03, 2026Novel view synthesis of dynamic scenes is fundamental to achieving photorealistic 4D reconstruction and immersive visual experiences. Recent progress in Gaussian-based representations has significantly improved real-time rendering quality, yet existing methods still struggle to maintain a balance between long-term static and short-term dynamic regions in both representation and optimization. To address this, we present SharpTimeGS, a lifespan-aware 4D Gaussian framework that achieves temporally adaptive modeling of both static and dynamic regions under a unified representation. Specifically, we introduce a learnable lifespan parameter that reformulates temporal visibility from a Gaussian-shaped decay into a flat-top profile, allowing primitives to remain consistently active over their intended duration and avoiding redundant densification. In addition, the learned lifespan modulates each primitives' motion, reducing drift in long-lived static points while retaining unrestricted motion for short-lived dynamic ones. This effectively decouples motion magnitude from temporal duration, improving long-term stability without compromising dynamic fidelity. Moreover, we design a lifespan-velocity-aware densification strategy that mitigates optimization imbalance between static and dynamic regions by allocating more capacity to regions with pronounced motion while keeping static areas compact and stable. Extensive experiments on multiple benchmarks demonstrate that our method achieves state-of-the-art performance while supporting real-time rendering up to 4K resolution at 100 FPS on one RTX 4090.
FlexAvatar: Flexible Large Reconstruction Model for Animatable Gaussian Head Avatars with Detailed Deformation
Dec 19, 2025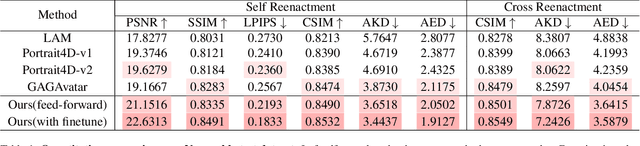
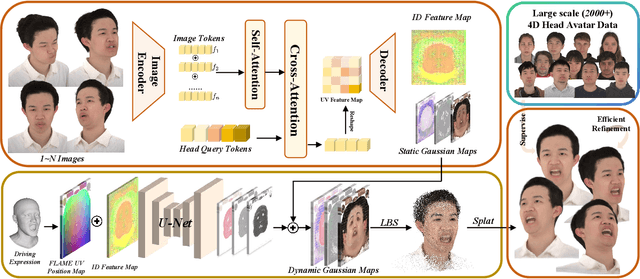
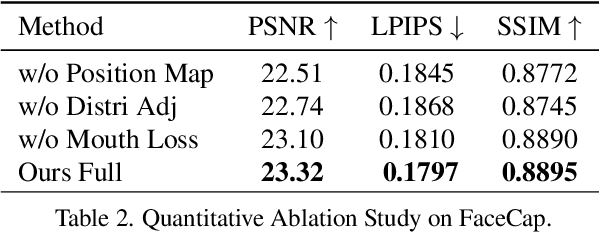

We present FlexAvatar, a flexible large reconstruction model for high-fidelity 3D head avatars with detailed dynamic deformation from single or sparse images, without requiring camera poses or expression labels. It leverages a transformer-based reconstruction model with structured head query tokens as canonical anchor to aggregate flexible input-number-agnostic, camera-pose-free and expression-free inputs into a robust canonical 3D representation. For detailed dynamic deformation, we introduce a lightweight UNet decoder conditioned on UV-space position maps, which can produce detailed expression-dependent deformations in real time. To better capture rare but critical expressions like wrinkles and bared teeth, we also adopt a data distribution adjustment strategy during training to balance the distribution of these expressions in the training set. Moreover, a lightweight 10-second refinement can further enhances identity-specific details in extreme identities without affecting deformation quality. Extensive experiments demonstrate that our FlexAvatar achieves superior 3D consistency, detailed dynamic realism compared with previous methods, providing a practical solution for animatable 3D avatar creation.
Tessellation GS: Neural Mesh Gaussians for Robust Monocular Reconstruction of Dynamic Objects
Dec 08, 20253D Gaussian Splatting (GS) enables highly photorealistic scene reconstruction from posed image sequences but struggles with viewpoint extrapolation due to its anisotropic nature, leading to overfitting and poor generalization, particularly in sparse-view and dynamic scene reconstruction. We propose Tessellation GS, a structured 2D GS approach anchored on mesh faces, to reconstruct dynamic scenes from a single continuously moving or static camera. Our method constrains 2D Gaussians to localized regions and infers their attributes via hierarchical neural features on mesh faces. Gaussian subdivision is guided by an adaptive face subdivision strategy driven by a detail-aware loss function. Additionally, we leverage priors from a reconstruction foundation model to initialize Gaussian deformations, enabling robust reconstruction of general dynamic objects from a single static camera, previously extremely challenging for optimization-based methods. Our method outperforms previous SOTA method, reducing LPIPS by 29.1% and Chamfer distance by 49.2% on appearance and mesh reconstruction tasks.
GeoSAM2: Unleashing the Power of SAM2 for 3D Part Segmentation
Aug 19, 2025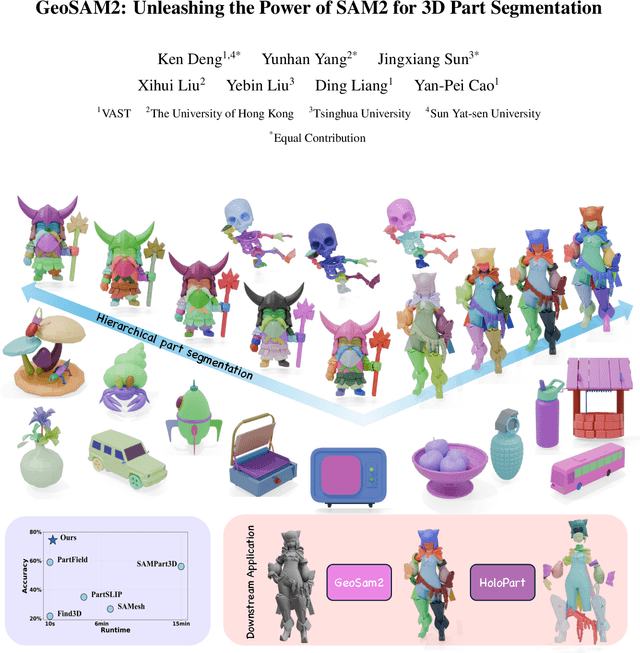
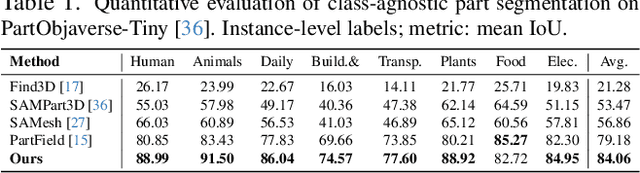
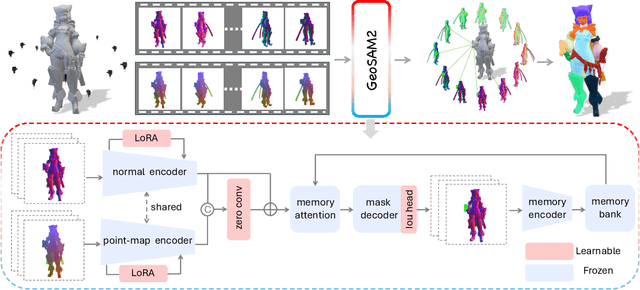

Modern 3D generation methods can rapidly create shapes from sparse or single views, but their outputs often lack geometric detail due to computational constraints. We present DetailGen3D, a generative approach specifically designed to enhance these generated 3D shapes. Our key insight is to model the coarse-to-fine transformation directly through data-dependent flows in latent space, avoiding the computational overhead of large-scale 3D generative models. We introduce a token matching strategy that ensures accurate spatial correspondence during refinement, enabling local detail synthesis while preserving global structure. By carefully designing our training data to match the characteristics of synthesized coarse shapes, our method can effectively enhance shapes produced by various 3D generation and reconstruction approaches, from single-view to sparse multi-view inputs. Extensive experiments demonstrate that DetailGen3D achieves high-fidelity geometric detail synthesis while maintaining efficiency in training.