 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMix3R: Mixing Feed-forward Reconstruction and Generative 3D Priors for Joint Multi-view Aligned 3D Reconstruction and Pose Estimation
May 05, 2026Recent trends in sparse-view 3D reconstruction have taken two different paths: feed-forward reconstruction that predicts pixel-aligned point maps without a complete geometry, and generative 3D reconstruction that generates complete geometry but often with poor input-alignment. We present Mix3R, a novel generative 3D reconstruction method which mixes feed-forward reconstruction and 3D generation into a single framework in an aligned manner. Mix3R generates a 3D shape in two stages: a sparse voxel generation stage and a textured geometry generation stage. Unlike pure generative methods, our first-stage generation jointly produces a coarse 3D structure (sparse voxels), per-view point maps and camera parameters aligned to that 3D structure. This is made possible by introducing a Mixture-of-Transformers architecture that inserts global self-attentions to a feed-forward reconstruction model and a 3D generative model, both pretrained on large-scale data. This design effectively retains the pretrained priors but enables better 2D-3D alignment. Based on the initial aligned generations of sparse 3D voxels and point maps, we compute an overlap-based attention bias that is directly added to another pretrained textured geometry generation model, enabling it to correctly place input textures onto generated shapes in a training-free manner. Our design brings mutual benefits to both feed-forward reconstruction and 3D generation: The feed-forward branch learns to ground its predictions to a generative 3D prior, and conversely, the 3D generation branch is conditioned on geometrically informative features from the feed-forward branch. As a result, our method produces 3D shapes with better input alignment compared with pure 3D generative methods, together with camera pose estimations more accurate than previous feed-forward reconstruction methods. Our project page is at https://jsnln.github.io/mix3r/
4DEquine: Disentangling Motion and Appearance for 4D Equine Reconstruction from Monocular Video
Mar 10, 20264D reconstruction of equine family (e.g. horses) from monocular video is important for animal welfare. Previous mainstream 4D animal reconstruction methods require joint optimization of motion and appearance over a whole video, which is time-consuming and sensitive to incomplete observation. In this work, we propose a novel framework called 4DEquine by disentangling the 4D reconstruction problem into two sub-problems: dynamic motion reconstruction and static appearance reconstruction. For motion, we introduce a simple yet effective spatio-temporal transformer with a post-optimization stage to regress smooth and pixel-aligned pose and shape sequences from video. For appearance, we design a novel feed-forward network that reconstructs a high-fidelity, animatable 3D Gaussian avatar from as few as a single image. To assist training, we create a large-scale synthetic motion dataset, VarenPoser, which features high-quality surface motions and diverse camera trajectories, as well as a synthetic appearance dataset, VarenTex, comprising realistic multi-view images generated through multi-view diffusion. While training only on synthetic datasets, 4DEquine achieves state-of-the-art performance on real-world APT36K and AiM datasets, demonstrating the superiority of 4DEquine and our new datasets for both geometry and appearance reconstruction. Comprehensive ablation studies validate the effectiveness of both the motion and appearance reconstruction network. Project page: https://luoxue-star.github.io/4DEquine_Project_Page/.
Monocular Mesh Recovery and Body Measurement of Female Saanen Goats
Feb 23, 2026The lactation performance of Saanen dairy goats, renowned for their high milk yield, is intrinsically linked to their body size, making accurate 3D body measurement essential for assessing milk production potential, yet existing reconstruction methods lack goat-specific authentic 3D data. To address this limitation, we establish the FemaleSaanenGoat dataset containing synchronized eight-view RGBD videos of 55 female Saanen goats (6-18 months). Using multi-view DynamicFusion, we fuse noisy, non-rigid point cloud sequences into high-fidelity 3D scans, overcoming challenges from irregular surfaces and rapid movement. Based on these scans, we develop SaanenGoat, a parametric 3D shape model specifically designed for female Saanen goats. This model features a refined template with 41 skeletal joints and enhanced udder representation, registered with our scan data. A comprehensive shape space constructed from 48 goats enables precise representation of diverse individual variations. With the help of SaanenGoat model, we get high-precision 3D reconstruction from single-view RGBD input, and achieve automated measurement of six critical body dimensions: body length, height, chest width, chest girth, hip width, and hip height. Experimental results demonstrate the superior accuracy of our method in both 3D reconstruction and body measurement, presenting a novel paradigm for large-scale 3D vision applications in precision livestock farming.
AniMer+: Unified Pose and Shape Estimation Across Mammalia and Aves via Family-Aware Transformer
Aug 01, 2025In the era of foundation models, achieving a unified understanding of different dynamic objects through a single network has the potential to empower stronger spatial intelligence. Moreover, accurate estimation of animal pose and shape across diverse species is essential for quantitative analysis in biological research. However, this topic remains underexplored due to the limited network capacity of previous methods and the scarcity of comprehensive multi-species datasets. To address these limitations, we introduce AniMer+, an extended version of our scalable AniMer framework. In this paper, we focus on a unified approach for reconstructing mammals (mammalia) and birds (aves). A key innovation of AniMer+ is its high-capacity, family-aware Vision Transformer (ViT) incorporating a Mixture-of-Experts (MoE) design. Its architecture partitions network layers into taxa-specific components (for mammalia and aves) and taxa-shared components, enabling efficient learning of both distinct and common anatomical features within a single model. To overcome the critical shortage of 3D training data, especially for birds, we introduce a diffusion-based conditional image generation pipeline. This pipeline produces two large-scale synthetic datasets: CtrlAni3D for quadrupeds and CtrlAVES3D for birds. To note, CtrlAVES3D is the first large-scale, 3D-annotated dataset for birds, which is crucial for resolving single-view depth ambiguities. Trained on an aggregated collection of 41.3k mammalian and 12.4k avian images (combining real and synthetic data), our method demonstrates superior performance over existing approaches across a wide range of benchmarks, including the challenging out-of-domain Animal Kingdom dataset. Ablation studies confirm the effectiveness of both our novel network architecture and the generated synthetic datasets in enhancing real-world application performance.
SemanticSplat: Feed-Forward 3D Scene Understanding with Language-Aware Gaussian Fields
Jun 11, 2025Holistic 3D scene understanding, which jointly models geometry, appearance, and semantics, is crucial for applications like augmented reality and robotic interaction. Existing feed-forward 3D scene understanding methods (e.g., LSM) are limited to extracting language-based semantics from scenes, failing to achieve holistic scene comprehension. Additionally, they suffer from low-quality geometry reconstruction and noisy artifacts. In contrast, per-scene optimization methods rely on dense input views, which reduces practicality and increases complexity during deployment. In this paper, we propose SemanticSplat, a feed-forward semantic-aware 3D reconstruction method, which unifies 3D Gaussians with latent semantic attributes for joint geometry-appearance-semantics modeling. To predict the semantic anisotropic Gaussians, SemanticSplat fuses diverse feature fields (e.g., LSeg, SAM) with a cost volume representation that stores cross-view feature similarities, enhancing coherent and accurate scene comprehension. Leveraging a two-stage distillation framework, SemanticSplat reconstructs a holistic multi-modal semantic feature field from sparse-view images. Experiments demonstrate the effectiveness of our method for 3D scene understanding tasks like promptable and open-vocabulary segmentation. Video results are available at https://semanticsplat.github.io.
AniMer: Animal Pose and Shape Estimation Using Family Aware Transformer
Dec 01, 2024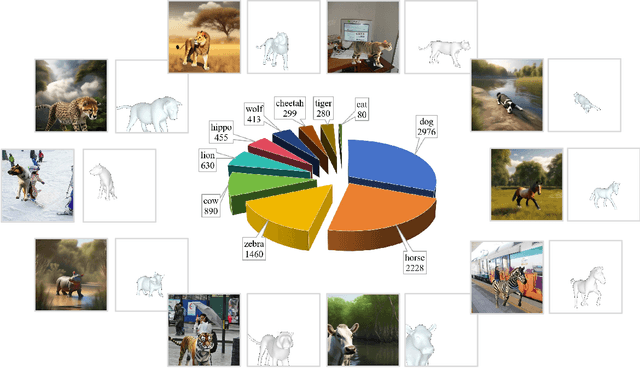
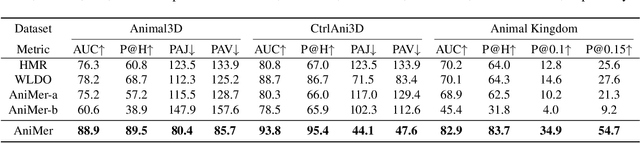
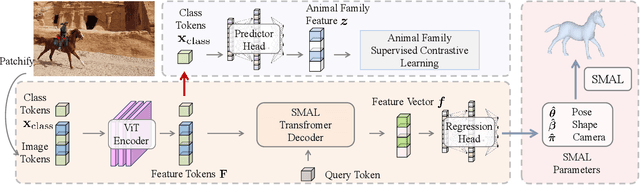

Quantitative analysis of animal behavior and biomechanics requires accurate animal pose and shape estimation across species, and is important for animal welfare and biological research. However, the small network capacity of previous methods and limited multi-species dataset leave this problem underexplored. To this end, this paper presents AniMer to estimate animal pose and shape using family aware Transformer, enhancing the reconstruction accuracy of diverse quadrupedal families. A key insight of AniMer is its integration of a high-capacity Transformer-based backbone and an animal family supervised contrastive learning scheme, unifying the discriminative understanding of various quadrupedal shapes within a single framework. For effective training, we aggregate most available open-sourced quadrupedal datasets, either with 3D or 2D labels. To improve the diversity of 3D labeled data, we introduce CtrlAni3D, a novel large-scale synthetic dataset created through a new diffusion-based conditional image generation pipeline. CtrlAni3D consists of about 10k images with pixel-aligned SMAL labels. In total, we obtain 41.3k annotated images for training and validation. Consequently, the combination of a family aware Transformer network and an expansive dataset enables AniMer to outperform existing methods not only on 3D datasets like Animal3D and CtrlAni3D, but also on out-of-distribution Animal Kingdom dataset. Ablation studies further demonstrate the effectiveness of our network design and CtrlAni3D in enhancing the performance of AniMer for in-the-wild applications. The project page of AniMer is https://luoxue-star.github.io/AniMer_project_page/.
ManiDext: Hand-Object Manipulation Synthesis via Continuous Correspondence Embeddings and Residual-Guided Diffusion
Sep 14, 2024Dynamic and dexterous manipulation of objects presents a complex challenge, requiring the synchronization of hand motions with the trajectories of objects to achieve seamless and physically plausible interactions. In this work, we introduce ManiDext, a unified hierarchical diffusion-based framework for generating hand manipulation and grasp poses based on 3D object trajectories. Our key insight is that accurately modeling the contact correspondences between objects and hands during interactions is crucial. Therefore, we propose a continuous correspondence embedding representation that specifies detailed hand correspondences at the vertex level between the object and the hand. This embedding is optimized directly on the hand mesh in a self-supervised manner, with the distance between embeddings reflecting the geodesic distance. Our framework first generates contact maps and correspondence embeddings on the object's surface. Based on these fine-grained correspondences, we introduce a novel approach that integrates the iterative refinement process into the diffusion process during the second stage of hand pose generation. At each step of the denoising process, we incorporate the current hand pose residual as a refinement target into the network, guiding the network to correct inaccurate hand poses. Introducing residuals into each denoising step inherently aligns with traditional optimization process, effectively merging generation and refinement into a single unified framework. Extensive experiments demonstrate that our approach can generate physically plausible and highly realistic motions for various tasks, including single and bimanual hand grasping as well as manipulating both rigid and articulated objects. Code will be available for research purposes.
Delving Deep into Pixel Alignment Feature for Accurate Multi-view Human Mesh Recovery
Jan 15, 2023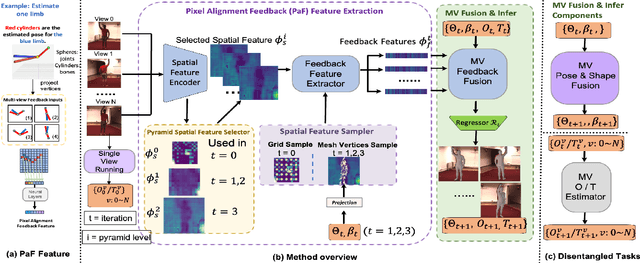
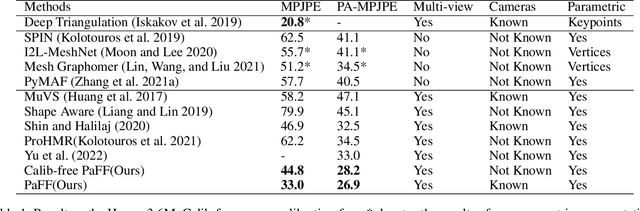
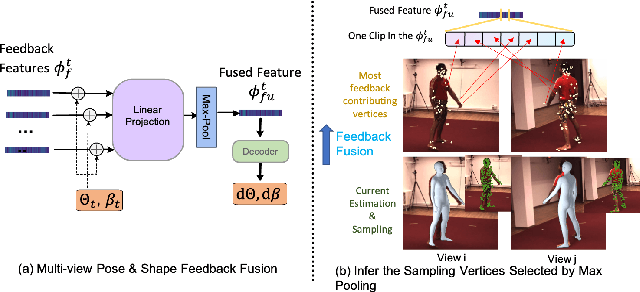
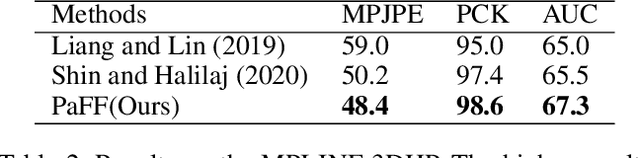
Regression-based methods have shown high efficiency and effectiveness for multi-view human mesh recovery. The key components of a typical regressor lie in the feature extraction of input views and the fusion of multi-view features. In this paper, we present Pixel-aligned Feedback Fusion (PaFF) for accurate yet efficient human mesh recovery from multi-view images. PaFF is an iterative regression framework that performs feature extraction and fusion alternately. At each iteration, PaFF extracts pixel-aligned feedback features from each input view according to the reprojection of the current estimation and fuses them together with respect to each vertex of the downsampled mesh. In this way, our regressor can not only perceive the misalignment status of each view from the feedback features but also correct the mesh parameters more effectively based on the feature fusion on mesh vertices. Additionally, our regressor disentangles the global orientation and translation of the body mesh from the estimation of mesh parameters such that the camera parameters of input views can be better utilized in the regression process. The efficacy of our method is validated in the Human3.6M dataset via comprehensive ablation experiments, where PaFF achieves 33.02 MPJPE and brings significant improvements over the previous best solutions by more than 29%. The project page with code and video results can be found at https://kairobo.github.io/PaFF/.
PyMAF-X: Towards Well-aligned Full-body Model Regression from Monocular Images
Jul 18, 2022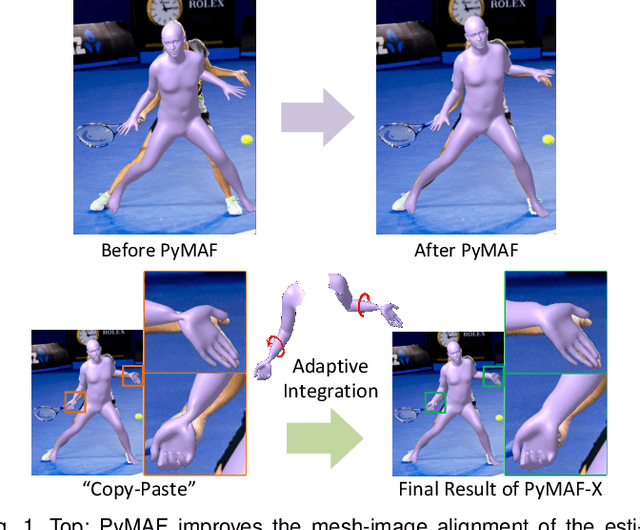
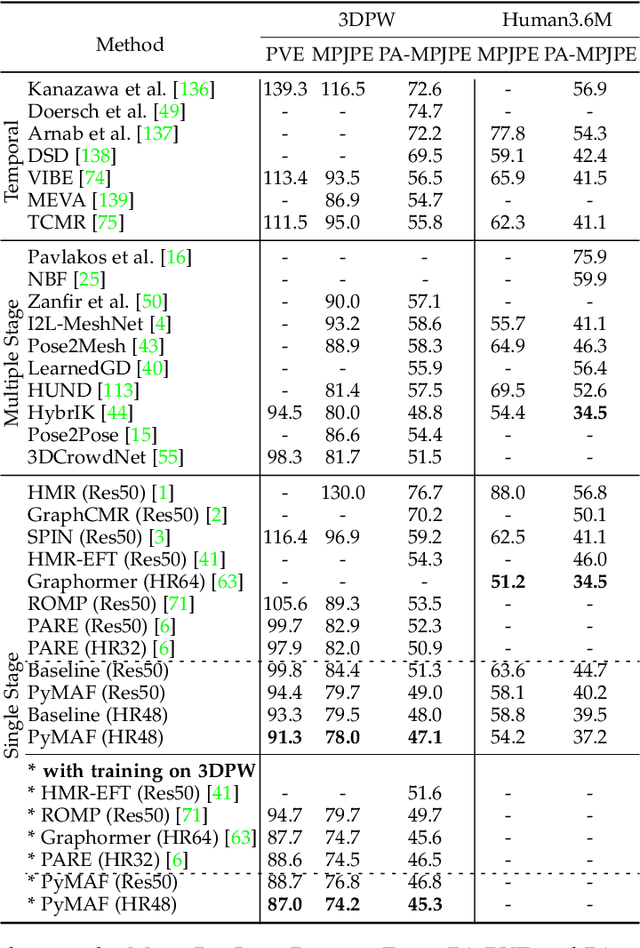
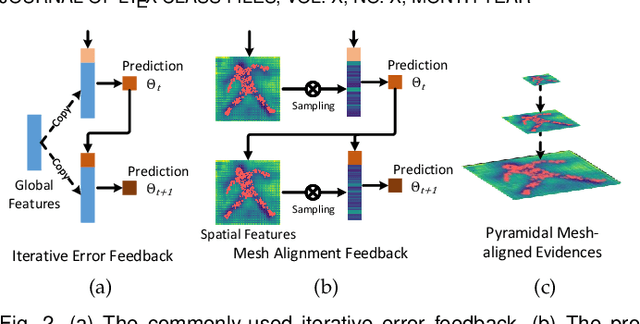
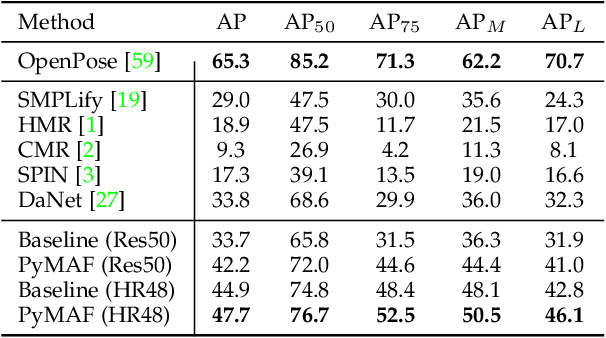
We present PyMAF-X, a regression-based approach to recovering a full-body parametric model from a single image. This task is very challenging since minor parametric deviation may lead to noticeable misalignment between the estimated mesh and the input image. Moreover, when integrating part-specific estimations to the full-body model, existing solutions tend to either degrade the alignment or produce unnatural wrist poses. To address these issues, we propose a Pyramidal Mesh Alignment Feedback (PyMAF) loop in our regression network for well-aligned human mesh recovery and extend it as PyMAF-X for the recovery of expressive full-body models. The core idea of PyMAF is to leverage a feature pyramid and rectify the predicted parameters explicitly based on the mesh-image alignment status. Specifically, given the currently predicted parameters, mesh-aligned evidence will be extracted from finer-resolution features accordingly and fed back for parameter rectification. To enhance the alignment perception, an auxiliary dense supervision is employed to provide mesh-image correspondence guidance while spatial alignment attention is introduced to enable the awareness of the global contexts for our network. When extending PyMAF for full-body mesh recovery, an adaptive integration strategy is proposed in PyMAF-X to produce natural wrist poses while maintaining the well-aligned performance of the part-specific estimations. The efficacy of our approach is validated on several benchmark datasets for body-only and full-body mesh recovery, where PyMAF and PyMAF-X effectively improve the mesh-image alignment and achieve new state-of-the-art results. The project page with code and video results can be found at https://www.liuyebin.com/pymaf-x.
Interacting Attention Graph for Single Image Two-Hand Reconstruction
Mar 18, 2022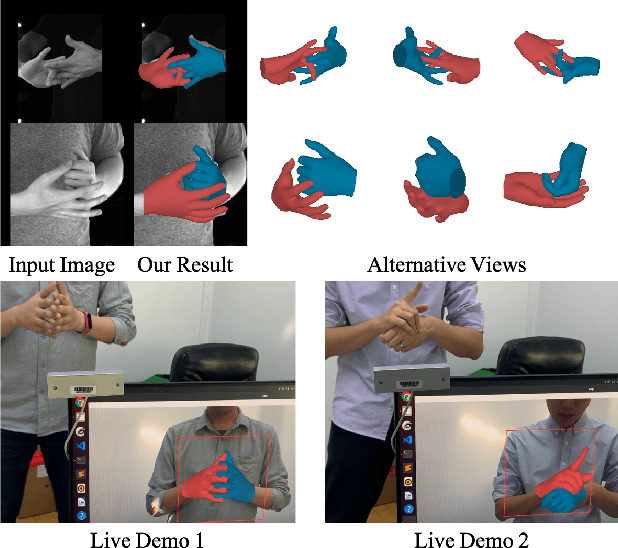
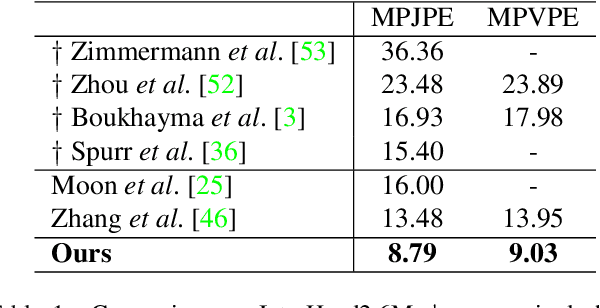
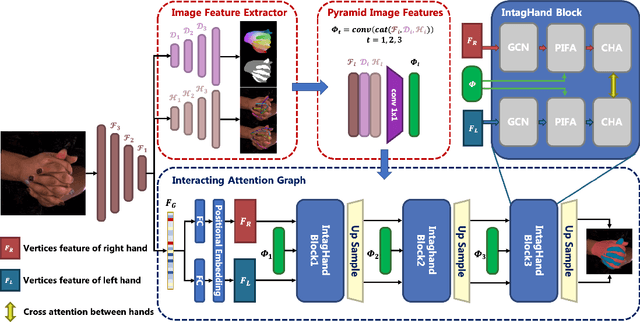
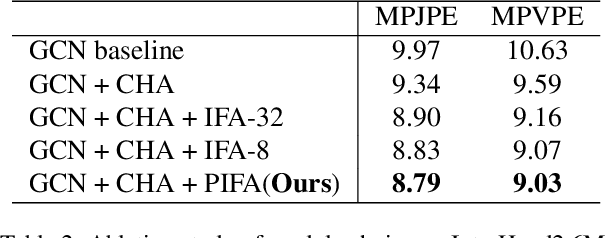
Graph convolutional network (GCN) has achieved great success in single hand reconstruction task, while interacting two-hand reconstruction by GCN remains unexplored. In this paper, we present Interacting Attention Graph Hand (IntagHand), the first graph convolution based network that reconstructs two interacting hands from a single RGB image. To solve occlusion and interaction challenges of two-hand reconstruction, we introduce two novel attention based modules in each upsampling step of the original GCN. The first module is the pyramid image feature attention (PIFA) module, which utilizes multiresolution features to implicitly obtain vertex-to-image alignment. The second module is the cross hand attention (CHA) module that encodes the coherence of interacting hands by building dense cross-attention between two hand vertices. As a result, our model outperforms all existing two-hand reconstruction methods by a large margin on InterHand2.6M benchmark. Moreover, ablation studies verify the effectiveness of both PIFA and CHA modules for improving the reconstruction accuracy. Results on in-the-wild images and live video streams further demonstrate the generalization ability of our network. Our code is available at https://github.com/Dw1010/IntagHand.