 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManiDext: Hand-Object Manipulation Synthesis via Continuous Correspondence Embeddings and Residual-Guided Diffusion
Sep 14, 2024Dynamic and dexterous manipulation of objects presents a complex challenge, requiring the synchronization of hand motions with the trajectories of objects to achieve seamless and physically plausible interactions. In this work, we introduce ManiDext, a unified hierarchical diffusion-based framework for generating hand manipulation and grasp poses based on 3D object trajectories. Our key insight is that accurately modeling the contact correspondences between objects and hands during interactions is crucial. Therefore, we propose a continuous correspondence embedding representation that specifies detailed hand correspondences at the vertex level between the object and the hand. This embedding is optimized directly on the hand mesh in a self-supervised manner, with the distance between embeddings reflecting the geodesic distance. Our framework first generates contact maps and correspondence embeddings on the object's surface. Based on these fine-grained correspondences, we introduce a novel approach that integrates the iterative refinement process into the diffusion process during the second stage of hand pose generation. At each step of the denoising process, we incorporate the current hand pose residual as a refinement target into the network, guiding the network to correct inaccurate hand poses. Introducing residuals into each denoising step inherently aligns with traditional optimization process, effectively merging generation and refinement into a single unified framework. Extensive experiments demonstrate that our approach can generate physically plausible and highly realistic motions for various tasks, including single and bimanual hand grasping as well as manipulating both rigid and articulated objects. Code will be available for research purposes.
Ins-HOI: Instance Aware Human-Object Interactions Recovery
Dec 15, 2023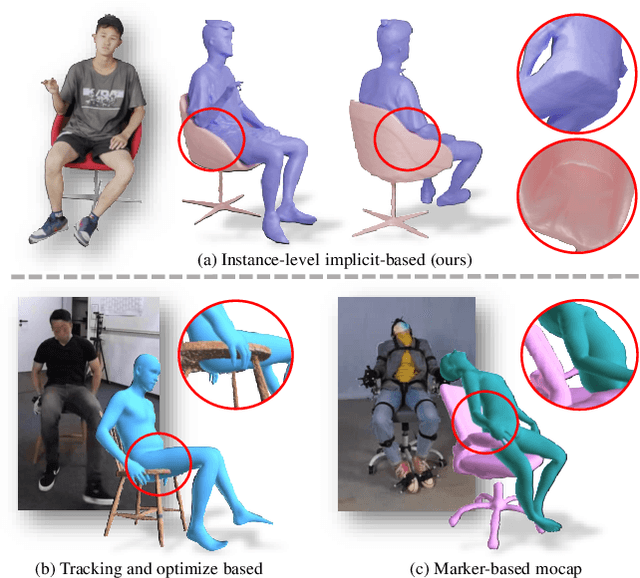



Recovering detailed interactions between humans/hands and objects is an appealing yet challenging task. Existing methods typically use template-based representations to track human/hand and objects in interactions. Despite the progress, they fail to handle the invisible contact surfaces. In this paper, we propose Ins-HOI, an end-to-end solution to recover human/hand-object reconstruction via instance-level implicit reconstruction. To this end, we introduce an instance-level occupancy field to support simultaneous human/hand and object representation, and a complementary training strategy to handle the lack of instance-level ground truths. Such a representation enables learning a contact prior implicitly from sparse observations. During the complementary training, we augment the real-captured data with synthesized data by randomly composing individual scans of humans/hands and objects and intentionally allowing for penetration. In this way, our network learns to recover individual shapes as completely as possible from the synthesized data, while being aware of the contact constraints and overall reasonability based on real-captured scans. As demonstrated in experiments, our method Ins-HOI can produce reasonable and realistic non-visible contact surfaces even in cases of extremely close interaction. To facilitate the research of this task, we collect a large-scale, high-fidelity 3D scan dataset, including 5.2k high-quality scans with real-world human-chair and hand-object interactions. We will release our dataset and source codes. Data examples and the video results of our method can be found on the project page.
1st Place Solutions for the UVO Challenge 2022
Oct 18, 2022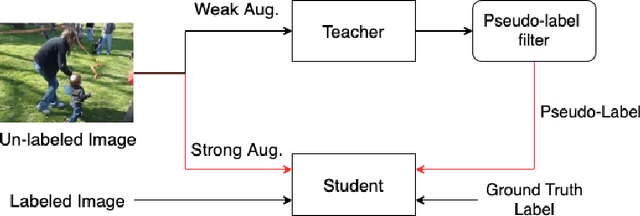

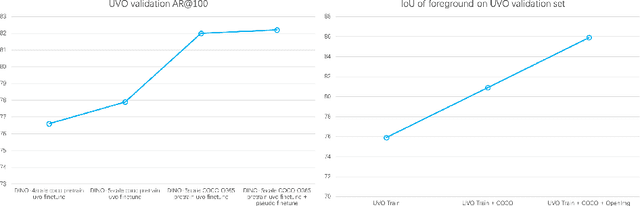

This paper describes the approach we have taken in the challenge. We still adopted the two-stage scheme same as the last champion, that is, detection first and segmentation followed. We trained more powerful detector and segmentor separately. Besides, we also perform pseudo-label training on the test set, based on student-teacher framework and end-to-end transformer based object detection. The method ranks first on the 2nd Unidentified Video Objects (UVO) challenge, achieving AR@100 of 46.8, 64.7 and 32.2 in the limited data frame track, unlimited data frame track and video track respectively.