 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharpTimeGS: Sharp and Stable Dynamic Gaussian Splatting via Lifespan Modulation
Feb 03, 2026Novel view synthesis of dynamic scenes is fundamental to achieving photorealistic 4D reconstruction and immersive visual experiences. Recent progress in Gaussian-based representations has significantly improved real-time rendering quality, yet existing methods still struggle to maintain a balance between long-term static and short-term dynamic regions in both representation and optimization. To address this, we present SharpTimeGS, a lifespan-aware 4D Gaussian framework that achieves temporally adaptive modeling of both static and dynamic regions under a unified representation. Specifically, we introduce a learnable lifespan parameter that reformulates temporal visibility from a Gaussian-shaped decay into a flat-top profile, allowing primitives to remain consistently active over their intended duration and avoiding redundant densification. In addition, the learned lifespan modulates each primitives' motion, reducing drift in long-lived static points while retaining unrestricted motion for short-lived dynamic ones. This effectively decouples motion magnitude from temporal duration, improving long-term stability without compromising dynamic fidelity. Moreover, we design a lifespan-velocity-aware densification strategy that mitigates optimization imbalance between static and dynamic regions by allocating more capacity to regions with pronounced motion while keeping static areas compact and stable. Extensive experiments on multiple benchmarks demonstrate that our method achieves state-of-the-art performance while supporting real-time rendering up to 4K resolution at 100 FPS on one RTX 4090.
GAF: Gaussian Action Field as a Dvnamic World Model for Robotic Mlanipulation
Jun 17, 2025



Accurate action inference is critical for vision-based robotic manipulation. Existing approaches typically follow either a Vision-to-Action (V-A) paradigm, predicting actions directly from visual inputs, or a Vision-to-3D-to-Action (V-3D-A) paradigm, leveraging intermediate 3D representations. However, these methods often struggle with action inaccuracies due to the complexity and dynamic nature of manipulation scenes. In this paper, we propose a V-4D-A framework that enables direct action reasoning from motion-aware 4D representations via a Gaussian Action Field (GAF). GAF extends 3D Gaussian Splatting (3DGS) by incorporating learnable motion attributes, allowing simultaneous modeling of dynamic scenes and manipulation actions. To learn time-varying scene geometry and action-aware robot motion, GAF supports three key query types: reconstruction of the current scene, prediction of future frames, and estimation of initial action via robot motion. Furthermore, the high-quality current and future frames generated by GAF facilitate manipulation action refinement through a GAF-guided diffusion model. Extensive experiments demonstrate significant improvements, with GAF achieving +11.5385 dB PSNR and -0.5574 LPIPS improvements in reconstruction quality, while boosting the average success rate in robotic manipulation tasks by 10.33% over state-of-the-art methods. Project page: http://chaiying1.github.io/GAF.github.io/project_page/
SemanticSplat: Feed-Forward 3D Scene Understanding with Language-Aware Gaussian Fields
Jun 11, 2025Holistic 3D scene understanding, which jointly models geometry, appearance, and semantics, is crucial for applications like augmented reality and robotic interaction. Existing feed-forward 3D scene understanding methods (e.g., LSM) are limited to extracting language-based semantics from scenes, failing to achieve holistic scene comprehension. Additionally, they suffer from low-quality geometry reconstruction and noisy artifacts. In contrast, per-scene optimization methods rely on dense input views, which reduces practicality and increases complexity during deployment. In this paper, we propose SemanticSplat, a feed-forward semantic-aware 3D reconstruction method, which unifies 3D Gaussians with latent semantic attributes for joint geometry-appearance-semantics modeling. To predict the semantic anisotropic Gaussians, SemanticSplat fuses diverse feature fields (e.g., LSeg, SAM) with a cost volume representation that stores cross-view feature similarities, enhancing coherent and accurate scene comprehension. Leveraging a two-stage distillation framework, SemanticSplat reconstructs a holistic multi-modal semantic feature field from sparse-view images. Experiments demonstrate the effectiveness of our method for 3D scene understanding tasks like promptable and open-vocabulary segmentation. Video results are available at https://semanticsplat.github.io.
MetricHMR: Metric Human Mesh Recovery from Monocular Images
Jun 11, 2025We introduce MetricHMR (Metric Human Mesh Recovery), an approach for metric human mesh recovery with accurate global translation from monocular images. In contrast to existing HMR methods that suffer from severe scale and depth ambiguity, MetricHMR is able to produce geometrically reasonable body shape and global translation in the reconstruction results. To this end, we first systematically analyze previous HMR methods on camera models to emphasize the critical role of the standard perspective projection model in enabling metric-scale HMR. We then validate the acceptable ambiguity range of metric HMR under the standard perspective projection model. Finally, we contribute a novel approach that introduces a ray map based on the standard perspective projection to jointly encode bounding-box information, camera parameters, and geometric cues for End2End metric HMR without any additional metric-regularization modules. Extensive experiments demonstrate that our method achieves state-of-the-art performance, even compared with sequential HMR methods, in metric pose, shape, and global translation estimation across both indoor and in-the-wild scenarios.
PhysiInter: Integrating Physical Mapping for High-Fidelity Human Interaction Generation
Jun 09, 2025Driven by advancements in motion capture and generative artificial intelligence, leveraging large-scale MoCap datasets to train generative models for synthesizing diverse, realistic human motions has become a promising research direction. However, existing motion-capture techniques and generative models often neglect physical constraints, leading to artifacts such as interpenetration, sliding, and floating. These issues are exacerbated in multi-person motion generation, where complex interactions are involved. To address these limitations, we introduce physical mapping, integrated throughout the human interaction generation pipeline. Specifically, motion imitation within a physics-based simulation environment is used to project target motions into a physically valid space. The resulting motions are adjusted to adhere to real-world physics constraints while retaining their original semantic meaning. This mapping not only improves MoCap data quality but also directly informs post-processing of generated motions. Given the unique interactivity of multi-person scenarios, we propose a tailored motion representation framework. Motion Consistency (MC) and Marker-based Interaction (MI) loss functions are introduced to improve model performance. Experiments show our method achieves impressive results in generated human motion quality, with a 3%-89% improvement in physical fidelity. Project page http://yw0208.github.io/physiinter
ReCoM: Realistic Co-Speech Motion Generation with Recurrent Embedded Transformer
Mar 27, 2025We present ReCoM, an efficient framework for generating high-fidelity and generalizable human body motions synchronized with speech. The core innovation lies in the Recurrent Embedded Transformer (RET), which integrates Dynamic Embedding Regularization (DER) into a Vision Transformer (ViT) core architecture to explicitly model co-speech motion dynamics. This architecture enables joint spatial-temporal dependency modeling, thereby enhancing gesture naturalness and fidelity through coherent motion synthesis. To enhance model robustness, we incorporate the proposed DER strategy, which equips the model with dual capabilities of noise resistance and cross-domain generalization, thereby improving the naturalness and fluency of zero-shot motion generation for unseen speech inputs. To mitigate inherent limitations of autoregressive inference, including error accumulation and limited self-correction, we propose an iterative reconstruction inference (IRI) strategy. IRI refines motion sequences via cyclic pose reconstruction, driven by two key components: (1) classifier-free guidance improves distribution alignment between generated and real gestures without auxiliary supervision, and (2) a temporal smoothing process eliminates abrupt inter-frame transitions while ensuring kinematic continuity. Extensive experiments on benchmark datasets validate ReCoM's effectiveness, achieving state-of-the-art performance across metrics. Notably, it reduces the Fr\'echet Gesture Distance (FGD) from 18.70 to 2.48, demonstrating an 86.7% improvement in motion realism. Our project page is https://yong-xie-xy.github.io/ReCoM/.
ManiVideo: Generating Hand-Object Manipulation Video with Dexterous and Generalizable Grasping
Dec 18, 2024



In this paper, we introduce ManiVideo, a novel method for generating consistent and temporally coherent bimanual hand-object manipulation videos from given motion sequences of hands and objects. The core idea of ManiVideo is the construction of a multi-layer occlusion (MLO) representation that learns 3D occlusion relationships from occlusion-free normal maps and occlusion confidence maps. By embedding the MLO structure into the UNet in two forms, the model enhances the 3D consistency of dexterous hand-object manipulation. To further achieve the generalizable grasping of objects, we integrate Objaverse, a large-scale 3D object dataset, to address the scarcity of video data, thereby facilitating the learning of extensive object consistency. Additionally, we propose an innovative training strategy that effectively integrates multiple datasets, supporting downstream tasks such as human-centric hand-object manipulation video generation. Through extensive experiments, we demonstrate that our approach not only achieves video generation with plausible hand-object interaction and generalizable objects, but also outperforms existing SOTA methods.
Stereo-Talker: Audio-driven 3D Human Synthesis with Prior-Guided Mixture-of-Experts
Oct 31, 2024



This paper introduces Stereo-Talker, a novel one-shot audio-driven human video synthesis system that generates 3D talking videos with precise lip synchronization, expressive body gestures, temporally consistent photo-realistic quality, and continuous viewpoint control. The process follows a two-stage approach. In the first stage, the system maps audio input to high-fidelity motion sequences, encompassing upper-body gestures and facial expressions. To enrich motion diversity and authenticity, large language model (LLM) priors are integrated with text-aligned semantic audio features, leveraging LLMs' cross-modal generalization power to enhance motion quality. In the second stage, we improve diffusion-based video generation models by incorporating a prior-guided Mixture-of-Experts (MoE) mechanism: a view-guided MoE focuses on view-specific attributes, while a mask-guided MoE enhances region-based rendering stability. Additionally, a mask prediction module is devised to derive human masks from motion data, enhancing the stability and accuracy of masks and enabling mask guiding during inference. We also introduce a comprehensive human video dataset with 2,203 identities, covering diverse body gestures and detailed annotations, facilitating broad generalization. The code, data, and pre-trained models will be released for research purposes.
Lodge++: High-quality and Long Dance Generation with Vivid Choreography Patterns
Oct 27, 2024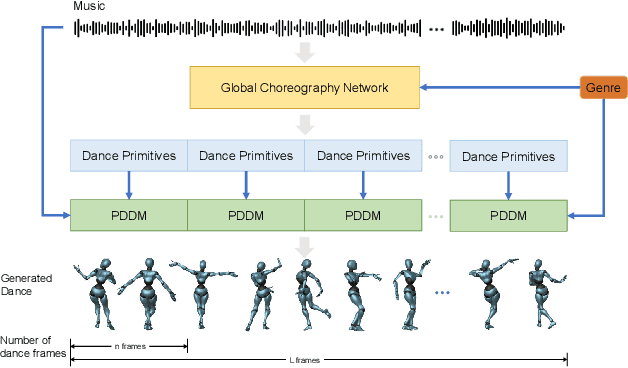
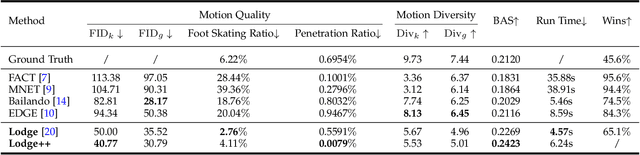
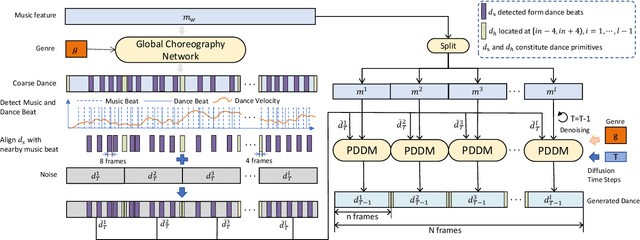
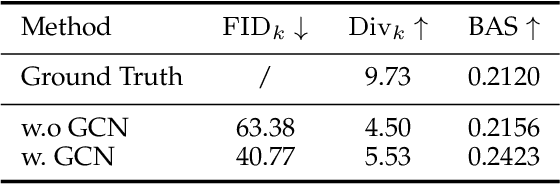
We propose Lodge++, a choreography framework to generate high-quality, ultra-long, and vivid dances given the music and desired genre. To handle the challenges in computational efficiency, the learning of complex and vivid global choreography patterns, and the physical quality of local dance movements, Lodge++ adopts a two-stage strategy to produce dances from coarse to fine. In the first stage, a global choreography network is designed to generate coarse-grained dance primitives that capture complex global choreography patterns. In the second stage, guided by these dance primitives, a primitive-based dance diffusion model is proposed to further generate high-quality, long-sequence dances in parallel, faithfully adhering to the complex choreography patterns. Additionally, to improve the physical plausibility, Lodge++ employs a penetration guidance module to resolve character self-penetration, a foot refinement module to optimize foot-ground contact, and a multi-genre discriminator to maintain genre consistency throughout the dance. Lodge++ is validated by extensive experiments, which show that our method can rapidly generate ultra-long dances suitable for various dance genres, ensuring well-organized global choreography patterns and high-quality local motion.
ManiDext: Hand-Object Manipulation Synthesis via Continuous Correspondence Embeddings and Residual-Guided Diffusion
Sep 14, 2024Dynamic and dexterous manipulation of objects presents a complex challenge, requiring the synchronization of hand motions with the trajectories of objects to achieve seamless and physically plausible interactions. In this work, we introduce ManiDext, a unified hierarchical diffusion-based framework for generating hand manipulation and grasp poses based on 3D object trajectories. Our key insight is that accurately modeling the contact correspondences between objects and hands during interactions is crucial. Therefore, we propose a continuous correspondence embedding representation that specifies detailed hand correspondences at the vertex level between the object and the hand. This embedding is optimized directly on the hand mesh in a self-supervised manner, with the distance between embeddings reflecting the geodesic distance. Our framework first generates contact maps and correspondence embeddings on the object's surface. Based on these fine-grained correspondences, we introduce a novel approach that integrates the iterative refinement process into the diffusion process during the second stage of hand pose generation. At each step of the denoising process, we incorporate the current hand pose residual as a refinement target into the network, guiding the network to correct inaccurate hand poses. Introducing residuals into each denoising step inherently aligns with traditional optimization process, effectively merging generation and refinement into a single unified framework. Extensive experiments demonstrate that our approach can generate physically plausible and highly realistic motions for various tasks, including single and bimanual hand grasping as well as manipulating both rigid and articulated objects. Code will be available for research purposes.