 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfiniteDance: Scalable 3D Dance Generation Towards in-the-wild Generalization
Mar 10, 2026Although existing 3D dance generation methods perform well in controlled scenarios, they often struggle to generalize in the wild. When conditioned on unseen music, existing methods often produce unstructured or physically implausible dance, largely due to limited music-to-dance data and restricted model capacity. This work aims to push the frontier of generalizable 3D dance generation by scaling up both data and model design. (1) On the data side, we develop a fully automated pipeline that reconstructs high-fidelity 3D dance motions from monocular videos. To eliminate the physical artifacts prevalent in existing reconstruction methods, we introduce a Foot Restoration Diffusion Model (FRDM) guided by foot-contact and geometric constraints that enforce physical plausibility while preserving kinematic smoothness and expressiveness, resulting in a diverse, high-quality multimodal 3D dance dataset totaling 100.69 hours. (2) On model design, we propose Choreographic LLaMA (ChoreoLLaMA), a scalable LLaMA-based architecture. To enhance robustness under unfamiliar music conditions, we integrate a retrieval-augmented generation (RAG) module that injects reference dance as a prompt. Additionally, we design a slow/fast-cadence Mixture-of-Experts (MoE) module that enables ChoreoLLaMA to smoothly adapt motion rhythms across varying music tempos. Extensive experiments across diverse dance genres show that our approach surpasses existing methods in both qualitative and quantitative evaluations, marking a step toward scalable, real-world 3D dance generation. Code, models, and data will be released.
WATCH: World-aware Allied Trajectory and pose reconstruction for Camera and Human
Sep 04, 2025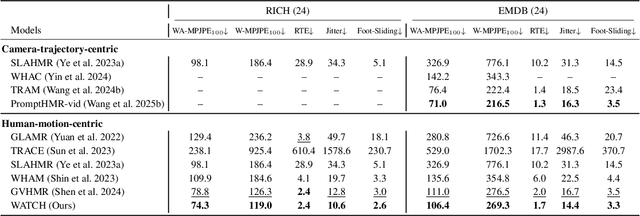
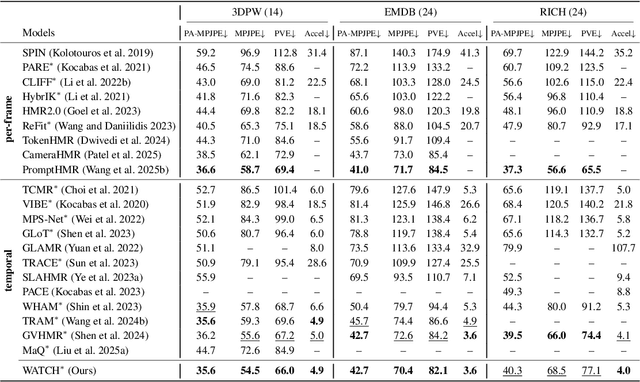

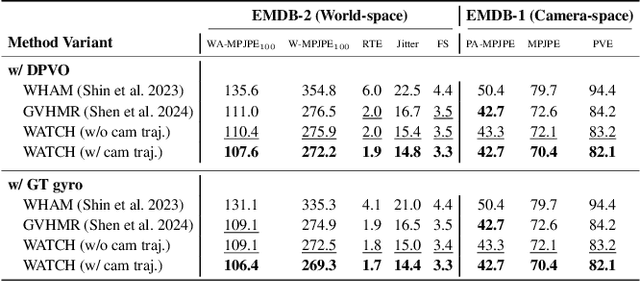
Global human motion reconstruction from in-the-wild monocular videos is increasingly demanded across VR, graphics, and robotics applications, yet requires accurate mapping of human poses from camera to world coordinates-a task challenged by depth ambiguity, motion ambiguity, and the entanglement between camera and human movements. While human-motion-centric approaches excel in preserving motion details and physical plausibility, they suffer from two critical limitations: insufficient exploitation of camera orientation information and ineffective integration of camera translation cues. We present WATCH (World-aware Allied Trajectory and pose reconstruction for Camera and Human), a unified framework addressing both challenges. Our approach introduces an analytical heading angle decomposition technique that offers superior efficiency and extensibility compared to existing geometric methods. Additionally, we design a camera trajectory integration mechanism inspired by world models, providing an effective pathway for leveraging camera translation information beyond naive hard-decoding approaches. Through experiments on in-the-wild benchmarks, WATCH achieves state-of-the-art performance in end-to-end trajectory reconstruction. Our work demonstrates the effectiveness of jointly modeling camera-human motion relationships and offers new insights for addressing the long-standing challenge of camera translation integration in global human motion reconstruction. The code will be available publicly.
InterAnimate: Taming Region-aware Diffusion Model for Realistic Human Interaction Animation
Apr 15, 2025Recent video generation research has focused heavily on isolated actions, leaving interactive motions-such as hand-face interactions-largely unexamined. These interactions are essential for emerging biometric authentication systems, which rely on interactive motion-based anti-spoofing approaches. From a security perspective, there is a growing need for large-scale, high-quality interactive videos to train and strengthen authentication models. In this work, we introduce a novel paradigm for animating realistic hand-face interactions. Our approach simultaneously learns spatio-temporal contact dynamics and biomechanically plausible deformation effects, enabling natural interactions where hand movements induce anatomically accurate facial deformations while maintaining collision-free contact. To facilitate this research, we present InterHF, a large-scale hand-face interaction dataset featuring 18 interaction patterns and 90,000 annotated videos. Additionally, we propose InterAnimate, a region-aware diffusion model designed specifically for interaction animation. InterAnimate leverages learnable spatial and temporal latents to effectively capture dynamic interaction priors and integrates a region-aware interaction mechanism that injects these priors into the denoising process. To the best of our knowledge, this work represents the first large-scale effort to systematically study human hand-face interactions. Qualitative and quantitative results show InterAnimate produces highly realistic animations, setting a new benchmark. Code and data will be made public to advance research.
Separate to Collaborate: Dual-Stream Diffusion Model for Coordinated Piano Hand Motion Synthesis
Apr 14, 2025Automating the synthesis of coordinated bimanual piano performances poses significant challenges, particularly in capturing the intricate choreography between the hands while preserving their distinct kinematic signatures. In this paper, we propose a dual-stream neural framework designed to generate synchronized hand gestures for piano playing from audio input, addressing the critical challenge of modeling both hand independence and coordination. Our framework introduces two key innovations: (i) a decoupled diffusion-based generation framework that independently models each hand's motion via dual-noise initialization, sampling distinct latent noise for each while leveraging a shared positional condition, and (ii) a Hand-Coordinated Asymmetric Attention (HCAA) mechanism suppresses symmetric (common-mode) noise to highlight asymmetric hand-specific features, while adaptively enhancing inter-hand coordination during denoising. The system operates hierarchically: it first predicts 3D hand positions from audio features and then generates joint angles through position-aware diffusion models, where parallel denoising streams interact via HCAA. Comprehensive evaluations demonstrate that our framework outperforms existing state-of-the-art methods across multiple metrics.
A Plug-and-Play Physical Motion Restoration Approach for In-the-Wild High-Difficulty Motions
Dec 23, 2024
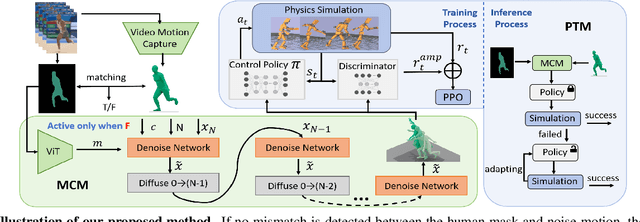
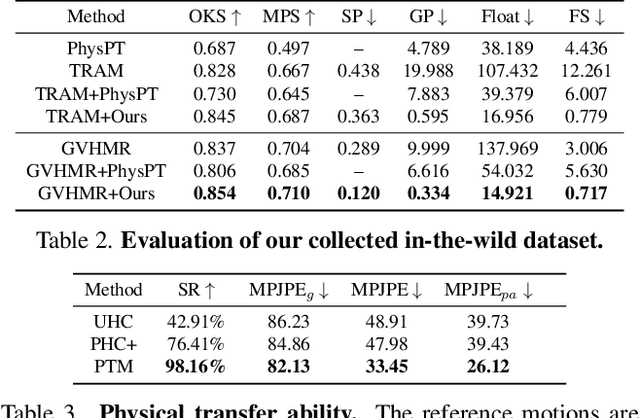

Extracting physically plausible 3D human motion from videos is a critical task. Although existing simulation-based motion imitation methods can enhance the physical quality of daily motions estimated from monocular video capture, extending this capability to high-difficulty motions remains an open challenge. This can be attributed to some flawed motion clips in video-based motion capture results and the inherent complexity in modeling high-difficulty motions. Therefore, sensing the advantage of segmentation in localizing human body, we introduce a mask-based motion correction module (MCM) that leverages motion context and video mask to repair flawed motions, producing imitation-friendly motions; and propose a physics-based motion transfer module (PTM), which employs a pretrain and adapt approach for motion imitation, improving physical plausibility with the ability to handle in-the-wild and challenging motions. Our approach is designed as a plug-and-play module to physically refine the video motion capture results, including high-difficulty in-the-wild motions. Finally, to validate our approach, we collected a challenging in-the-wild test set to establish a benchmark, and our method has demonstrated effectiveness on both the new benchmark and existing public datasets.https://physicalmotionrestoration.github.io
InterDance:Reactive 3D Dance Generation with Realistic Duet Interactions
Dec 22, 2024



Humans perform a variety of interactive motions, among which duet dance is one of the most challenging interactions. However, in terms of human motion generative models, existing works are still unable to generate high-quality interactive motions, especially in the field of duet dance. On the one hand, it is due to the lack of large-scale high-quality datasets. On the other hand, it arises from the incomplete representation of interactive motion and the lack of fine-grained optimization of interactions. To address these challenges, we propose, InterDance, a large-scale duet dance dataset that significantly enhances motion quality, data scale, and the variety of dance genres. Built upon this dataset, we propose a new motion representation that can accurately and comprehensively describe interactive motion. We further introduce a diffusion-based framework with an interaction refinement guidance strategy to optimize the realism of interactions progressively. Extensive experiments demonstrate the effectiveness of our dataset and algorithm.
AToM: Aligning Text-to-Motion Model at Event-Level with GPT-4Vision Reward
Nov 27, 2024



Recently, text-to-motion models have opened new possibilities for creating realistic human motion with greater efficiency and flexibility. However, aligning motion generation with event-level textual descriptions presents unique challenges due to the complex relationship between textual prompts and desired motion outcomes. To address this, we introduce AToM, a framework that enhances the alignment between generated motion and text prompts by leveraging reward from GPT-4Vision. AToM comprises three main stages: Firstly, we construct a dataset MotionPrefer that pairs three types of event-level textual prompts with generated motions, which cover the integrity, temporal relationship and frequency of motion. Secondly, we design a paradigm that utilizes GPT-4Vision for detailed motion annotation, including visual data formatting, task-specific instructions and scoring rules for each sub-task. Finally, we fine-tune an existing text-to-motion model using reinforcement learning guided by this paradigm. Experimental results demonstrate that AToM significantly improves the event-level alignment quality of text-to-motion generation.
Lodge++: High-quality and Long Dance Generation with Vivid Choreography Patterns
Oct 27, 2024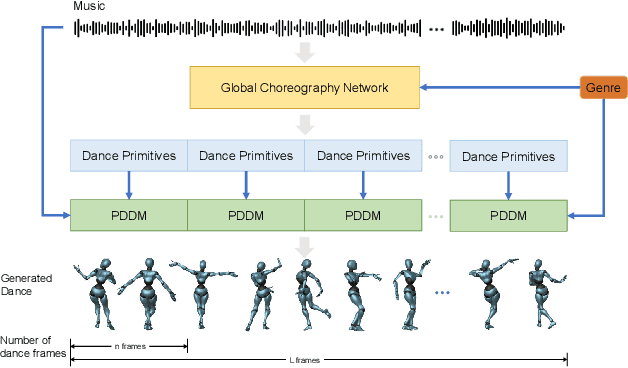
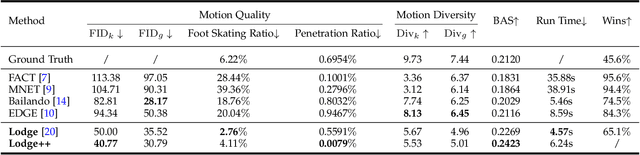
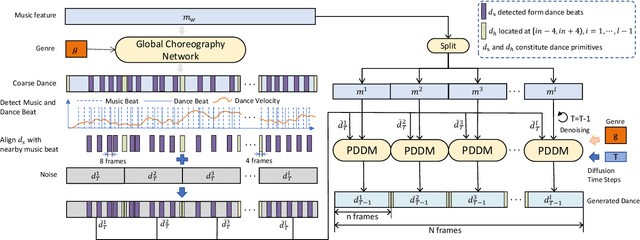
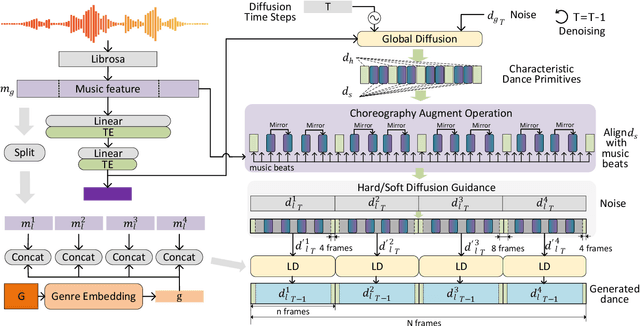
We propose Lodge++, a choreography framework to generate high-quality, ultra-long, and vivid dances given the music and desired genre. To handle the challenges in computational efficiency, the learning of complex and vivid global choreography patterns, and the physical quality of local dance movements, Lodge++ adopts a two-stage strategy to produce dances from coarse to fine. In the first stage, a global choreography network is designed to generate coarse-grained dance primitives that capture complex global choreography patterns. In the second stage, guided by these dance primitives, a primitive-based dance diffusion model is proposed to further generate high-quality, long-sequence dances in parallel, faithfully adhering to the complex choreography patterns. Additionally, to improve the physical plausibility, Lodge++ employs a penetration guidance module to resolve character self-penetration, a foot refinement module to optimize foot-ground contact, and a multi-genre discriminator to maintain genre consistency throughout the dance. Lodge++ is validated by extensive experiments, which show that our method can rapidly generate ultra-long dances suitable for various dance genres, ensuring well-organized global choreography patterns and high-quality local motion.
Lodge: A Coarse to Fine Diffusion Network for Long Dance Generation Guided by the Characteristic Dance Primitives
Mar 26, 2024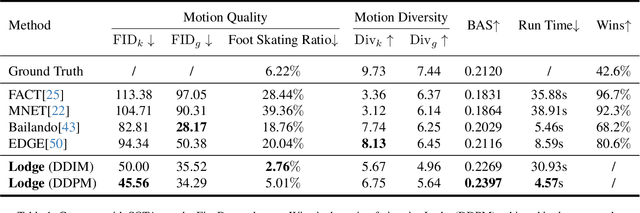


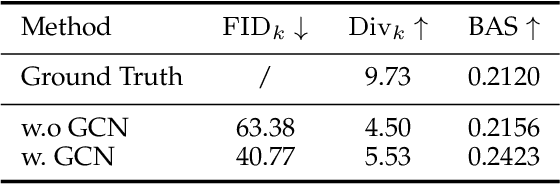
We propose Lodge, a network capable of generating extremely long dance sequences conditioned on given music. We design Lodge as a two-stage coarse to fine diffusion architecture, and propose the characteristic dance primitives that possess significant expressiveness as intermediate representations between two diffusion models. The first stage is global diffusion, which focuses on comprehending the coarse-level music-dance correlation and production characteristic dance primitives. In contrast, the second-stage is the local diffusion, which parallelly generates detailed motion sequences under the guidance of the dance primitives and choreographic rules. In addition, we propose a Foot Refine Block to optimize the contact between the feet and the ground, enhancing the physical realism of the motion. Our approach can parallelly generate dance sequences of extremely long length, striking a balance between global choreographic patterns and local motion quality and expressiveness. Extensive experiments validate the efficacy of our method.
MambaTalk: Efficient Holistic Gesture Synthesis with Selective State Space Models
Mar 14, 2024


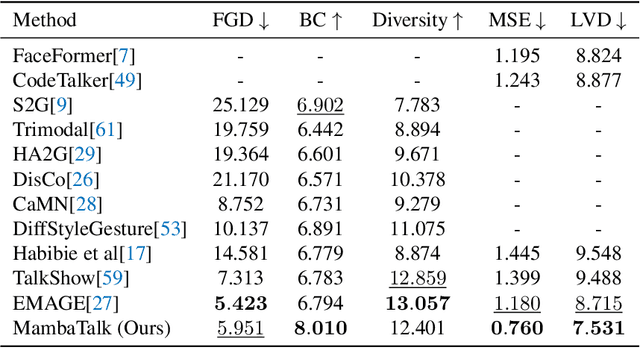
Gesture synthesis is a vital realm of human-computer interaction, with wide-ranging applications across various fields like film, robotics, and virtual reality. Recent advancements have utilized the diffusion model and attention mechanisms to improve gesture synthesis. However, due to the high computational complexity of these techniques, generating long and diverse sequences with low latency remains a challenge. We explore the potential of state space models (SSMs) to address the challenge, implementing a two-stage modeling strategy with discrete motion priors to enhance the quality of gestures. Leveraging the foundational Mamba block, we introduce MambaTalk, enhancing gesture diversity and rhythm through multimodal integration. Extensive experiments demonstrate that our method matches or exceeds the performance of state-of-the-art models.