 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVPortrait: Text-Guided Motion and Emotion Control for Multi-view Vivid Portrait Animation
Mar 25, 2025Recent portrait animation methods have made significant strides in generating realistic lip synchronization. However, they often lack explicit control over head movements and facial expressions, and cannot produce videos from multiple viewpoints, resulting in less controllable and expressive animations. Moreover, text-guided portrait animation remains underexplored, despite its user-friendly nature. We present a novel two-stage text-guided framework, MVPortrait (Multi-view Vivid Portrait), to generate expressive multi-view portrait animations that faithfully capture the described motion and emotion. MVPortrait is the first to introduce FLAME as an intermediate representation, effectively embedding facial movements, expressions, and view transformations within its parameter space. In the first stage, we separately train the FLAME motion and emotion diffusion models based on text input. In the second stage, we train a multi-view video generation model conditioned on a reference portrait image and multi-view FLAME rendering sequences from the first stage. Experimental results exhibit that MVPortrait outperforms existing methods in terms of motion and emotion control, as well as view consistency. Furthermore, by leveraging FLAME as a bridge, MVPortrait becomes the first controllable portrait animation framework that is compatible with text, speech, and video as driving signals.
Harmonious Group Choreography with Trajectory-Controllable Diffusion
Mar 10, 2024
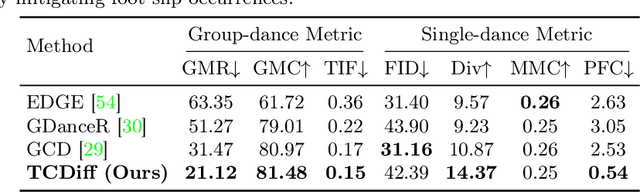
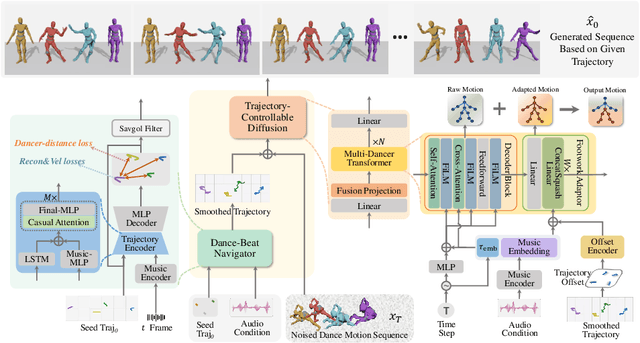
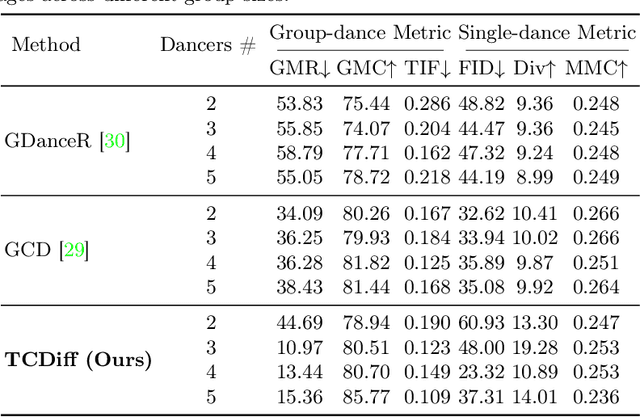
Creating group choreography from music has gained attention in cultural entertainment and virtual reality, aiming to coordinate visually cohesive and diverse group movements. Despite increasing interest, recent works face challenges in achieving aesthetically appealing choreography, primarily for two key issues: multi-dancer collision and single-dancer foot slide. To address these issues, we propose a Trajectory-Controllable Diffusion (TCDiff), a novel approach that harnesses non-overlapping trajectories to facilitate coherent dance movements. Specifically, to tackle dancer collisions, we introduce a Dance-Beat Navigator capable of generating trajectories for multiple dancers based on the music, complemented by a Distance-Consistency loss to maintain appropriate spacing among trajectories within a reasonable threshold. To mitigate foot sliding, we present a Footwork Adaptor that utilizes trajectory displacement from adjacent frames to enable flexible footwork, coupled with a Relative Forward-Kinematic loss to adjust the positioning of individual dancers' root nodes and joints. Extensive experiments demonstrate that our method achieves state-of-the-art results.
Realistic Human Motion Generation with Cross-Diffusion Models
Dec 18, 2023We introduce the Cross Human Motion Diffusion Model (CrossDiff), a novel approach for generating high-quality human motion based on textual descriptions. Our method integrates 3D and 2D information using a shared transformer network within the training of the diffusion model, unifying motion noise into a single feature space. This enables cross-decoding of features into both 3D and 2D motion representations, regardless of their original dimension. The primary advantage of CrossDiff is its cross-diffusion mechanism, which allows the model to reverse either 2D or 3D noise into clean motion during training. This capability leverages the complementary information in both motion representations, capturing intricate human movement details often missed by models relying solely on 3D information. Consequently, CrossDiff effectively combines the strengths of both representations to generate more realistic motion sequences. In our experiments, our model demonstrates competitive state-of-the-art performance on text-to-motion benchmarks. Moreover, our method consistently provides enhanced motion generation quality, capturing complex full-body movement intricacies. Additionally, with a pretrained model,our approach accommodates using in the wild 2D motion data without 3D motion ground truth during training to generate 3D motion, highlighting its potential for broader applications and efficient use of available data resources. Project page: https://wonderno.github.io/CrossDiff-webpage/.
Magic: Multi Art Genre Intelligent Choreography Dataset and Network for 3D Dance Generation
Dec 08, 2022Achieving multiple genres and long-term choreography sequences from given music is a challenging task, due to the lack of a multi-genre dataset. To tackle this problem,we propose a Multi Art Genre Intelligent Choreography Dataset (MagicDance). The data of MagicDance is captured from professional dancers assisted by motion capture technicians. It has a total of 8 hours 3D motioncapture human dances with paired music, and 16 different dance genres. To the best of our knowledge, MagicDance is the 3D dance dataset with the most genres. In addition, we find that the existing two types of methods (generation-based method and synthesis-based method) can only satisfy one of the diversity and duration, but they can complement to some extent. Based on this observation, we also propose a generation-synthesis choreography network (MagicNet), which cascades a Diffusion-based 3D Diverse Dance fragments Generation Network (3DGNet) and a Genre&Coherent aware Retrieval Module (GCRM). The former can generate various dance fragments from only one music clip. The latter is utilized to select the best dance fragment generated by 3DGNet and switch them into a complete dance according to the genre and coherent matching score. Quantitative and qualitative experiments demonstrate the quality of MagicDance, and the state-of-the-art performance of MagicNet.