 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEAD: Self-Evolving Agent for Multi-Turn Service Dialogue
Feb 03, 2026Large Language Models have demonstrated remarkable capabilities in open-domain dialogues. However, current methods exhibit suboptimal performance in service dialogues, as they rely on noisy, low-quality human conversation data. This limitation arises from data scarcity and the difficulty of simulating authentic, goal-oriented user behaviors. To address these issues, we propose SEAD (Self-Evolving Agent for Service Dialogue), a framework that enables agents to learn effective strategies without large-scale human annotations. SEAD decouples user modeling into two components: a Profile Controller that generates diverse user states to manage training curriculum, and a User Role-play Model that focuses on realistic role-playing. This design ensures the environment provides adaptive training scenarios rather than acting as an unfair adversary. Experiments demonstrate that SEAD significantly outperforms Open-source Foundation Models and Closed-source Commercial Models, improving task completion rate by 17.6% and dialogue efficiency by 11.1%. Code is available at: https://github.com/Da1yuqin/SEAD.
Human Motion Video Generation: A Survey
Sep 04, 2025Human motion video generation has garnered significant research interest due to its broad applications, enabling innovations such as photorealistic singing heads or dynamic avatars that seamlessly dance to music. However, existing surveys in this field focus on individual methods, lacking a comprehensive overview of the entire generative process. This paper addresses this gap by providing an in-depth survey of human motion video generation, encompassing over ten sub-tasks, and detailing the five key phases of the generation process: input, motion planning, motion video generation, refinement, and output. Notably, this is the first survey that discusses the potential of large language models in enhancing human motion video generation. Our survey reviews the latest developments and technological trends in human motion video generation across three primary modalities: vision, text, and audio. By covering over two hundred papers, we offer a thorough overview of the field and highlight milestone works that have driven significant technological breakthroughs. Our goal for this survey is to unveil the prospects of human motion video generation and serve as a valuable resource for advancing the comprehensive applications of digital humans. A complete list of the models examined in this survey is available in Our Repository https://github.com/Winn1y/Awesome-Human-Motion-Video-Generation.
* Accepted by TPAMI. Github Repo: https://github.com/Winn1y/Awesome-Human-Motion-Video-Generation IEEE Access: https://ieeexplore.ieee.org/document/11106267
Careful Queries, Credible Results: Teaching RAG Models Advanced Web Search Tools with Reinforcement Learning
Aug 11, 2025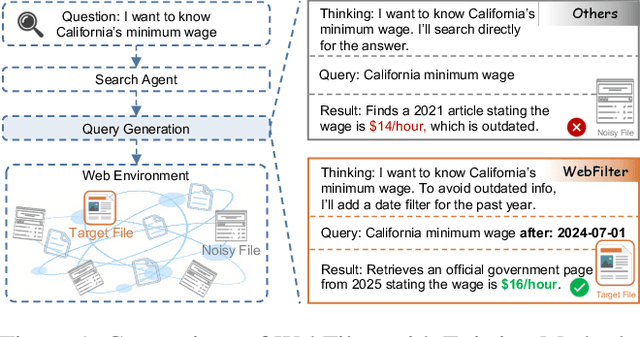
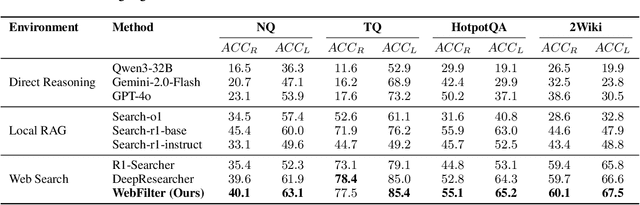
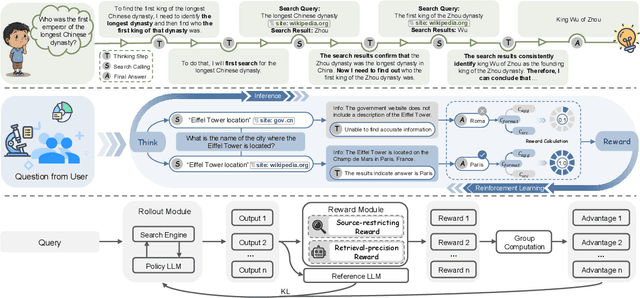
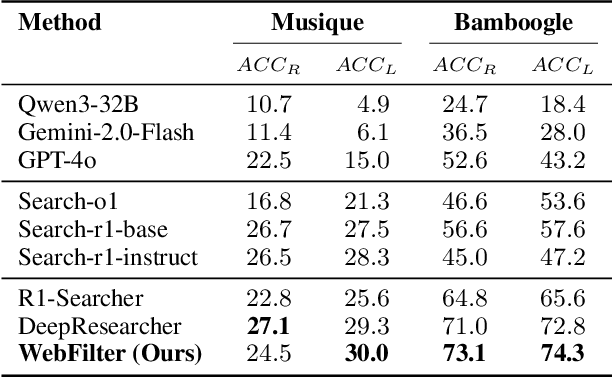
Retrieval-Augmented Generation (RAG) enhances large language models (LLMs) by integrating up-to-date external knowledge, yet real-world web environments present unique challenges. These limitations manifest as two key challenges: pervasive misinformation in the web environment, which introduces unreliable or misleading content that can degrade retrieval accuracy, and the underutilization of web tools, which, if effectively employed, could enhance query precision and help mitigate this noise, ultimately improving the retrieval results in RAG systems. To address these issues, we propose WebFilter, a novel RAG framework that generates source-restricted queries and filters out unreliable content. This approach combines a retrieval filtering mechanism with a behavior- and outcome-driven reward strategy, optimizing both query formulation and retrieval outcomes. Extensive experiments demonstrate that WebFilter improves answer quality and retrieval precision, outperforming existing RAG methods on both in-domain and out-of-domain benchmarks.
RealFactBench: A Benchmark for Evaluating Large Language Models in Real-World Fact-Checking
Jun 14, 2025Large Language Models (LLMs) hold significant potential for advancing fact-checking by leveraging their capabilities in reasoning, evidence retrieval, and explanation generation. However, existing benchmarks fail to comprehensively evaluate LLMs and Multimodal Large Language Models (MLLMs) in realistic misinformation scenarios. To bridge this gap, we introduce RealFactBench, a comprehensive benchmark designed to assess the fact-checking capabilities of LLMs and MLLMs across diverse real-world tasks, including Knowledge Validation, Rumor Detection, and Event Verification. RealFactBench consists of 6K high-quality claims drawn from authoritative sources, encompassing multimodal content and diverse domains. Our evaluation framework further introduces the Unknown Rate (UnR) metric, enabling a more nuanced assessment of models' ability to handle uncertainty and balance between over-conservatism and over-confidence. Extensive experiments on 7 representative LLMs and 4 MLLMs reveal their limitations in real-world fact-checking and offer valuable insights for further research. RealFactBench is publicly available at https://github.com/kalendsyang/RealFactBench.git.
MindAligner: Explicit Brain Functional Alignment for Cross-Subject Visual Decoding from Limited fMRI Data
Feb 07, 2025



Brain decoding aims to reconstruct visual perception of human subject from fMRI signals, which is crucial for understanding brain's perception mechanisms. Existing methods are confined to the single-subject paradigm due to substantial brain variability, which leads to weak generalization across individuals and incurs high training costs, exacerbated by limited availability of fMRI data. To address these challenges, we propose MindAligner, an explicit functional alignment framework for cross-subject brain decoding from limited fMRI data. The proposed MindAligner enjoys several merits. First, we learn a Brain Transfer Matrix (BTM) that projects the brain signals of an arbitrary new subject to one of the known subjects, enabling seamless use of pre-trained decoding models. Second, to facilitate reliable BTM learning, a Brain Functional Alignment module is proposed to perform soft cross-subject brain alignment under different visual stimuli with a multi-level brain alignment loss, uncovering fine-grained functional correspondences with high interpretability. Experiments indicate that MindAligner not only outperforms existing methods in visual decoding under data-limited conditions, but also provides valuable neuroscience insights in cross-subject functional analysis. The code will be made publicly available.
Harmonious Group Choreography with Trajectory-Controllable Diffusion
Mar 10, 2024
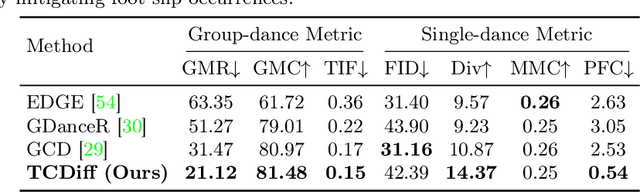
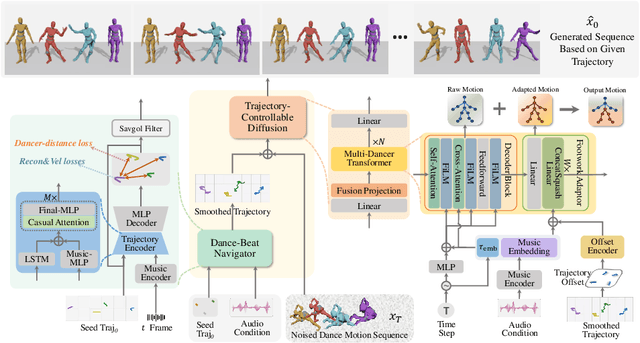
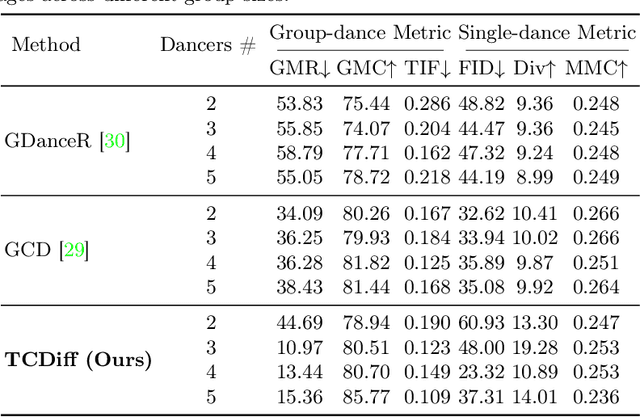
Creating group choreography from music has gained attention in cultural entertainment and virtual reality, aiming to coordinate visually cohesive and diverse group movements. Despite increasing interest, recent works face challenges in achieving aesthetically appealing choreography, primarily for two key issues: multi-dancer collision and single-dancer foot slide. To address these issues, we propose a Trajectory-Controllable Diffusion (TCDiff), a novel approach that harnesses non-overlapping trajectories to facilitate coherent dance movements. Specifically, to tackle dancer collisions, we introduce a Dance-Beat Navigator capable of generating trajectories for multiple dancers based on the music, complemented by a Distance-Consistency loss to maintain appropriate spacing among trajectories within a reasonable threshold. To mitigate foot sliding, we present a Footwork Adaptor that utilizes trajectory displacement from adjacent frames to enable flexible footwork, coupled with a Relative Forward-Kinematic loss to adjust the positioning of individual dancers' root nodes and joints. Extensive experiments demonstrate that our method achieves state-of-the-art results.
Text2Avatar: Text to 3D Human Avatar Generation with Codebook-Driven Body Controllable Attribute
Jan 01, 2024



Generating 3D human models directly from text helps reduce the cost and time of character modeling. However, achieving multi-attribute controllable and realistic 3D human avatar generation is still challenging due to feature coupling and the scarcity of realistic 3D human avatar datasets. To address these issues, we propose Text2Avatar, which can generate realistic-style 3D avatars based on the coupled text prompts. Text2Avatar leverages a discrete codebook as an intermediate feature to establish a connection between text and avatars, enabling the disentanglement of features. Furthermore, to alleviate the scarcity of realistic style 3D human avatar data, we utilize a pre-trained unconditional 3D human avatar generation model to obtain a large amount of 3D avatar pseudo data, which allows Text2Avatar to achieve realistic style generation. Experimental results demonstrate that our method can generate realistic 3D avatars from coupled textual data, which is challenging for other existing methods in this field.
Exploring Multi-Modal Control in Music-Driven Dance Generation
Jan 01, 2024Existing music-driven 3D dance generation methods mainly concentrate on high-quality dance generation, but lack sufficient control during the generation process. To address these issues, we propose a unified framework capable of generating high-quality dance movements and supporting multi-modal control, including genre control, semantic control, and spatial control. First, we decouple the dance generation network from the dance control network, thereby avoiding the degradation in dance quality when adding additional control information. Second, we design specific control strategies for different control information and integrate them into a unified framework. Experimental results show that the proposed dance generation framework outperforms state-of-the-art methods in terms of motion quality and controllability.