 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProject Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
InternAgent-1.5: A Unified Agentic Framework for Long-Horizon Autonomous Scientific Discovery
Feb 09, 2026We introduce InternAgent-1.5, a unified system designed for end-to-end scientific discovery across computational and empirical domains. The system is built on a structured architecture composed of three coordinated subsystems for generation, verification, and evolution. These subsystems are supported by foundational capabilities for deep research, solution optimization, and long horizon memory. The architecture allows InternAgent-1.5 to operate continuously across extended discovery cycles while maintaining coherent and improving behavior. It also enables the system to coordinate computational modeling and laboratory experimentation within a single unified system. We evaluate InternAgent-1.5 on scientific reasoning benchmarks such as GAIA, HLE, GPQA, and FrontierScience, and the system achieves leading performance that demonstrates strong foundational capabilities. Beyond these benchmarks, we further assess two categories of discovery tasks. In algorithm discovery tasks, InternAgent-1.5 autonomously designs competitive methods for core machine learning problems. In empirical discovery tasks, it executes complete computational or wet lab experiments and produces scientific findings in earth, life, biological, and physical domains. Overall, these results show that InternAgent-1.5 provides a general and scalable framework for autonomous scientific discovery.
Probing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
SynBrain: Enhancing Visual-to-fMRI Synthesis via Probabilistic Representation Learning
Aug 14, 2025Deciphering how visual stimuli are transformed into cortical responses is a fundamental challenge in computational neuroscience. This visual-to-neural mapping is inherently a one-to-many relationship, as identical visual inputs reliably evoke variable hemodynamic responses across trials, contexts, and subjects. However, existing deterministic methods struggle to simultaneously model this biological variability while capturing the underlying functional consistency that encodes stimulus information. To address these limitations, we propose SynBrain, a generative framework that simulates the transformation from visual semantics to neural responses in a probabilistic and biologically interpretable manner. SynBrain introduces two key components: (i) BrainVAE models neural representations as continuous probability distributions via probabilistic learning while maintaining functional consistency through visual semantic constraints; (ii) A Semantic-to-Neural Mapper acts as a semantic transmission pathway, projecting visual semantics into the neural response manifold to facilitate high-fidelity fMRI synthesis. Experimental results demonstrate that SynBrain surpasses state-of-the-art methods in subject-specific visual-to-fMRI encoding performance. Furthermore, SynBrain adapts efficiently to new subjects with few-shot data and synthesizes high-quality fMRI signals that are effective in improving data-limited fMRI-to-image decoding performance. Beyond that, SynBrain reveals functional consistency across trials and subjects, with synthesized signals capturing interpretable patterns shaped by biological neural variability. The code will be made publicly available.
MindAligner: Explicit Brain Functional Alignment for Cross-Subject Visual Decoding from Limited fMRI Data
Feb 07, 2025



Brain decoding aims to reconstruct visual perception of human subject from fMRI signals, which is crucial for understanding brain's perception mechanisms. Existing methods are confined to the single-subject paradigm due to substantial brain variability, which leads to weak generalization across individuals and incurs high training costs, exacerbated by limited availability of fMRI data. To address these challenges, we propose MindAligner, an explicit functional alignment framework for cross-subject brain decoding from limited fMRI data. The proposed MindAligner enjoys several merits. First, we learn a Brain Transfer Matrix (BTM) that projects the brain signals of an arbitrary new subject to one of the known subjects, enabling seamless use of pre-trained decoding models. Second, to facilitate reliable BTM learning, a Brain Functional Alignment module is proposed to perform soft cross-subject brain alignment under different visual stimuli with a multi-level brain alignment loss, uncovering fine-grained functional correspondences with high interpretability. Experiments indicate that MindAligner not only outperforms existing methods in visual decoding under data-limited conditions, but also provides valuable neuroscience insights in cross-subject functional analysis. The code will be made publicly available.
Neuro-3D: Towards 3D Visual Decoding from EEG Signals
Nov 21, 2024Human's perception of the visual world is shaped by the stereo processing of 3D information. Understanding how the brain perceives and processes 3D visual stimuli in the real world has been a longstanding endeavor in neuroscience. Towards this goal, we introduce a new neuroscience task: decoding 3D visual perception from EEG signals, a neuroimaging technique that enables real-time monitoring of neural dynamics enriched with complex visual cues. To provide the essential benchmark, we first present EEG-3D, a pioneering dataset featuring multimodal analysis data and extensive EEG recordings from 12 subjects viewing 72 categories of 3D objects rendered in both videos and images. Furthermore, we propose Neuro-3D, a 3D visual decoding framework based on EEG signals. This framework adaptively integrates EEG features derived from static and dynamic stimuli to learn complementary and robust neural representations, which are subsequently utilized to recover both the shape and color of 3D objects through the proposed diffusion-based colored point cloud decoder. To the best of our knowledge, we are the first to explore EEG-based 3D visual decoding. Experiments indicate that Neuro-3D not only reconstructs colored 3D objects with high fidelity, but also learns effective neural representations that enable insightful brain region analysis. The dataset and associated code will be made publicly available.
The Devil Is in the Details: Window-based Attention for Image Compression
Mar 16, 2022
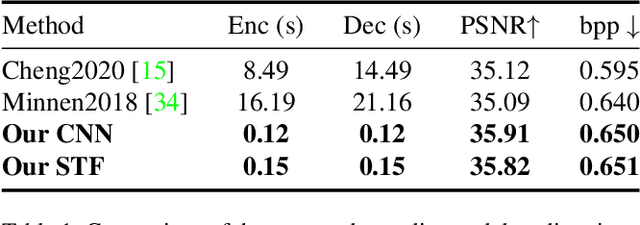
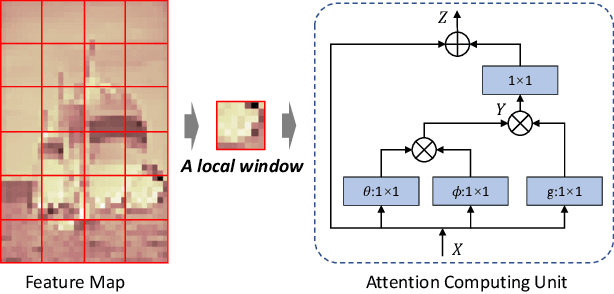
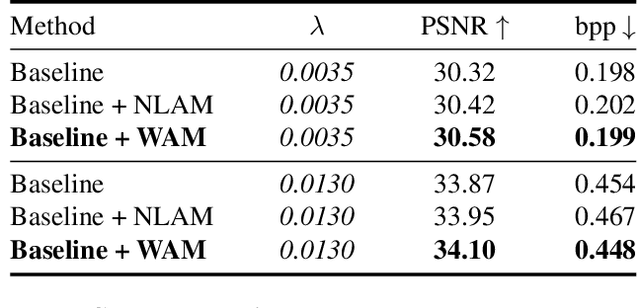
Learned image compression methods have exhibited superior rate-distortion performance than classical image compression standards. Most existing learned image compression models are based on Convolutional Neural Networks (CNNs). Despite great contributions, a main drawback of CNN based model is that its structure is not designed for capturing local redundancy, especially the non-repetitive textures, which severely affects the reconstruction quality. Therefore, how to make full use of both global structure and local texture becomes the core problem for learning-based image compression. Inspired by recent progresses of Vision Transformer (ViT) and Swin Transformer, we found that combining the local-aware attention mechanism with the global-related feature learning could meet the expectation in image compression. In this paper, we first extensively study the effects of multiple kinds of attention mechanisms for local features learning, then introduce a more straightforward yet effective window-based local attention block. The proposed window-based attention is very flexible which could work as a plug-and-play component to enhance CNN and Transformer models. Moreover, we propose a novel Symmetrical TransFormer (STF) framework with absolute transformer blocks in the down-sampling encoder and up-sampling decoder. Extensive experimental evaluations have shown that the proposed method is effective and outperforms the state-of-the-art methods. The code is publicly available at https://github.com/Googolxx/STF.
Box-driven Class-wise Region Masking and Filling Rate Guided Loss for Weakly Supervised Semantic Segmentation
Apr 26, 2019
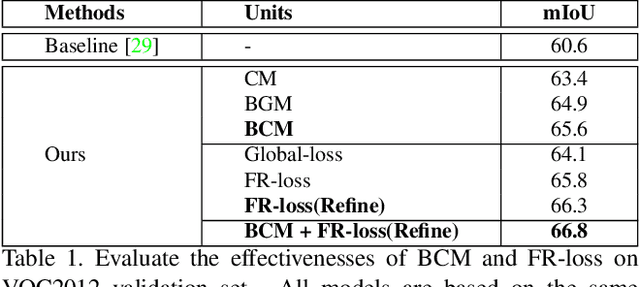
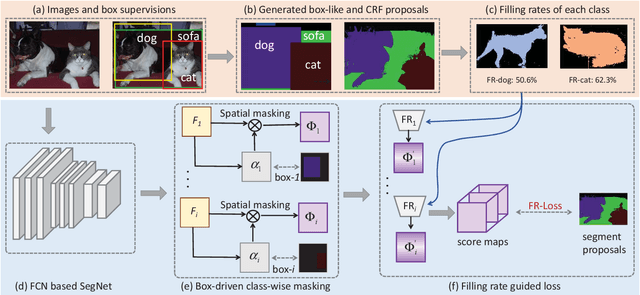
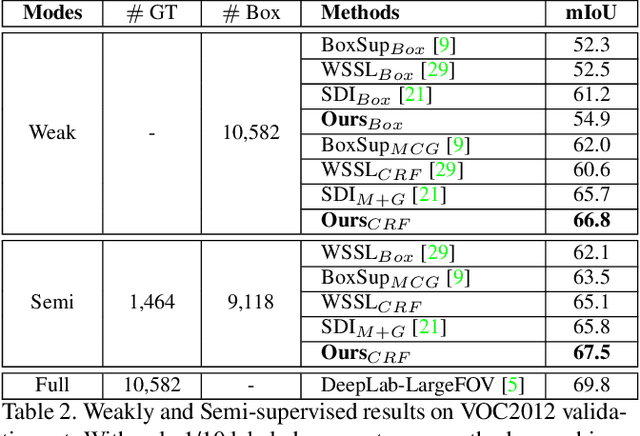
Semantic segmentation has achieved huge progress via adopting deep Fully Convolutional Networks (FCN). However, the performance of FCN based models severely rely on the amounts of pixel-level annotations which are expensive and time-consuming. To address this problem, it is a good choice to learn to segment with weak supervision from bounding boxes. How to make full use of the class-level and region-level supervisions from bounding boxes is the critical challenge for the weakly supervised learning task. In this paper, we first introduce a box-driven class-wise masking model (BCM) to remove irrelevant regions of each class. Moreover, based on the pixel-level segment proposal generated from the bounding box supervision, we could calculate the mean filling rates of each class to serve as an important prior cue, then we propose a filling rate guided adaptive loss (FR-Loss) to help the model ignore the wrongly labeled pixels in proposals. Unlike previous methods directly training models with the fixed individual segment proposals, our method can adjust the model learning with global statistical information. Thus it can help reduce the negative impacts from wrongly labeled proposals. We evaluate the proposed method on the challenging PASCAL VOC 2012 benchmark and compare with other methods. Extensive experimental results show that the proposed method is effective and achieves the state-of-the-art results.
Air Quality Measurement Based on Double-Channel Convolutional Neural Network Ensemble Learning
Feb 28, 2019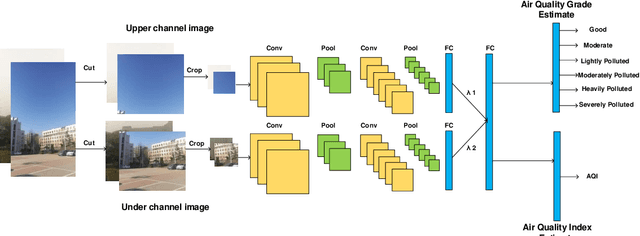
Environmental air quality affects people's life, obtaining real-time and accurate environmental air quality has a profound guiding significance for the development of social activities. At present, environmental air quality measurement mainly adopts the method that setting air quality detector at specific monitoring points in cities and timing sampling analysis, which is easy to be restricted by time and space factors. Some air quality measurement algorithms related to deep learning mostly adopt a single convolutional neural network to train the whole image, which will ignore the difference of different parts of the image. In this paper, we propose a method for air quality measurement based on double-channel convolutional neural network ensemble learning to solve the problem of feature extraction for different parts of environmental images. Our method mainly includes two aspects: ensemble learning of double-channel convolutional neural network and self-learning weighted feature fusion. We constructed a double-channel convolutional neural network, used each channel to train different parts of the environment images for feature extraction. We propose a feature weight self-learning method, which weights and concatenates the extracted feature vectors, and uses the fused feature vectors to measure air quality. Our method can be applied to the two tasks of air quality grade measurement and air quality index (AQI) measurement. Moreover, we build an environmental image dataset of random time and location condition. The experiments show that our method can achieve nearly 82% accuracy and a small mean absolute error (MAE) on our test dataset. At the same time, through comparative experiment, we proved that our proposed method gained considerable improvement in performance compared with single channel convolutional neural network air quality measurements.