 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Models, Shallow Alignment: Uncovering the Granularity Mismatch in Neural Decoding
Jan 29, 2026Neural visual decoding is a central problem in brain computer interface research, aiming to reconstruct human visual perception and to elucidate the structure of neural representations. However, existing approaches overlook a fundamental granularity mismatch between human and machine vision, where deep vision models emphasize semantic invariance by suppressing local texture information, whereas neural signals preserve an intricate mixture of low-level visual attributes and high-level semantic content. To address this mismatch, we propose Shallow Alignment, a novel contrastive learning strategy that aligns neural signals with intermediate representations of visual encoders rather than their final outputs, thereby striking a better balance between low-level texture details and high-level semantic features. Extensive experiments across multiple benchmarks demonstrate that Shallow Alignment significantly outperforms standard final-layer alignment, with performance gains ranging from 22% to 58% across diverse vision backbones. Notably, our approach effectively unlocks the scaling law in neural visual decoding, enabling decoding performance to scale predictably with the capacity of pre-trained vision backbones. We further conduct systematic empirical analyses to shed light on the mechanisms underlying the observed performance gains.
Neuro-3D: Towards 3D Visual Decoding from EEG Signals
Nov 21, 2024Human's perception of the visual world is shaped by the stereo processing of 3D information. Understanding how the brain perceives and processes 3D visual stimuli in the real world has been a longstanding endeavor in neuroscience. Towards this goal, we introduce a new neuroscience task: decoding 3D visual perception from EEG signals, a neuroimaging technique that enables real-time monitoring of neural dynamics enriched with complex visual cues. To provide the essential benchmark, we first present EEG-3D, a pioneering dataset featuring multimodal analysis data and extensive EEG recordings from 12 subjects viewing 72 categories of 3D objects rendered in both videos and images. Furthermore, we propose Neuro-3D, a 3D visual decoding framework based on EEG signals. This framework adaptively integrates EEG features derived from static and dynamic stimuli to learn complementary and robust neural representations, which are subsequently utilized to recover both the shape and color of 3D objects through the proposed diffusion-based colored point cloud decoder. To the best of our knowledge, we are the first to explore EEG-based 3D visual decoding. Experiments indicate that Neuro-3D not only reconstructs colored 3D objects with high fidelity, but also learns effective neural representations that enable insightful brain region analysis. The dataset and associated code will be made publicly available.
High-performance cVEP-BCI under minimal calibration
Nov 20, 2023The ultimate goal of brain-computer interfaces (BCIs) based on visual modulation paradigms is to achieve high-speed performance without the burden of extensive calibration. Code-modulated visual evoked potential-based BCIs (cVEP-BCIs) modulated by broadband white noise (WN) offer various advantages, including increased communication speed, expanded encoding target capabilities, and enhanced coding flexibility. However, the complexity of the spatial-temporal patterns under broadband stimuli necessitates extensive calibration for effective target identification in cVEP-BCIs. Consequently, the information transfer rate (ITR) of cVEP-BCI under limited calibration usually stays around 100 bits per minute (bpm), significantly lagging behind state-of-the-art steady-state visual evoked potential-based BCIs (SSVEP-BCIs), which achieve rates above 200 bpm. To enhance the performance of cVEP-BCIs with minimal calibration, we devised an efficient calibration stage involving a brief single-target flickering, lasting less than a minute, to extract generalizable spatial-temporal patterns. Leveraging the calibration data, we developed two complementary methods to construct cVEP temporal patterns: the linear modeling method based on the stimulus sequence and the transfer learning techniques using cross-subject data. As a result, we achieved the highest ITR of 250 bpm under a minute of calibration, which has been shown to be comparable to the state-of-the-art SSVEP paradigms. In summary, our work significantly improved the cVEP performance under few-shot learning, which is expected to expand the practicality and usability of cVEP-BCIs.
Estimating and approaching maximum information rate of noninvasive visual brain-computer interface
Aug 25, 2023
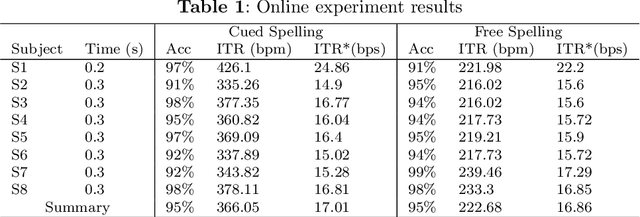
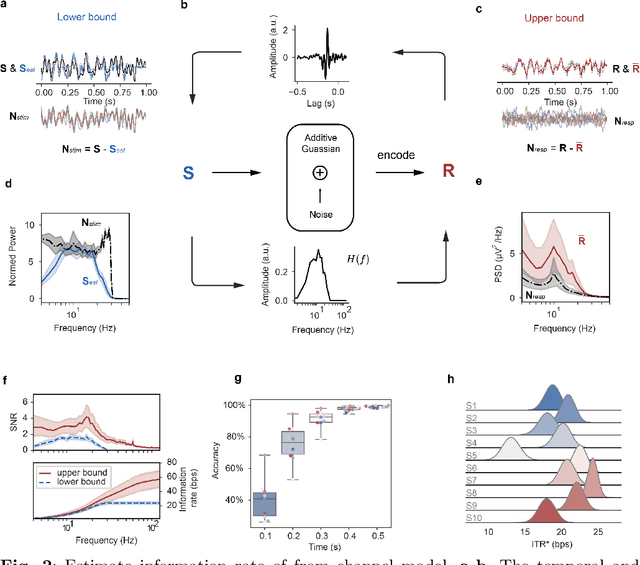

The mission of visual brain-computer interfaces (BCIs) is to enhance information transfer rate (ITR) to reach high speed towards real-life communication. Despite notable progress, noninvasive visual BCIs have encountered a plateau in ITRs, leaving it uncertain whether higher ITRs are achievable. In this study, we investigate the information rate limits of the primary visual channel to explore whether we can and how we should build visual BCI with higher information rate. Using information theory, we estimate a maximum achievable ITR of approximately 63 bits per second (bps) with a uniformly-distributed White Noise (WN) stimulus. Based on this discovery, we propose a broadband WN BCI approach that expands the utilization of stimulus bandwidth, in contrast to the current state-of-the-art visual BCI methods based on steady-state visual evoked potentials (SSVEPs). Through experimental validation, our broadband BCI outperforms the SSVEP BCI by an impressive margin of 7 bps, setting a new record of 50 bps. This achievement demonstrates the possibility of decoding 40 classes of noninvasive neural responses within a short duration of only 0.1 seconds. The information-theoretical framework introduced in this study provides valuable insights applicable to all sensory-evoked BCIs, making a significant step towards the development of next-generation human-machine interaction systems.
Decoding Natural Images from EEG for Object Recognition
Aug 25, 2023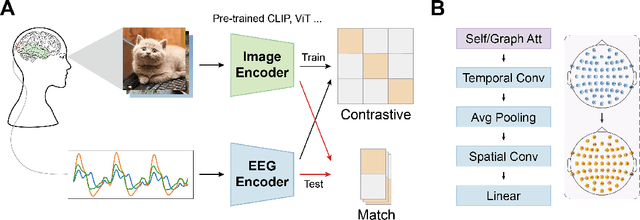

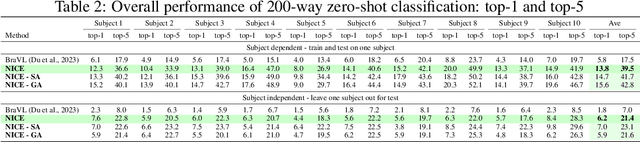
Electroencephalogram (EEG) is a brain signal known for its high time resolution and moderate signal-to-noise ratio. Whether natural images can be decoded from EEG has been a hot issue recently. In this paper, we propose a self-supervised framework to learn image representations from EEG signals. Specifically, image and EEG encoders are first used to extract features from paired image stimuli and EEG responses. Then we employ contrastive learning to align these two modalities by constraining their similarity. Additionally, we introduce two plug-in-play modules that capture spatial correlations before the EEG encoder. Our approach achieves state-of-the-art results on the most extensive EEG-image dataset, with a top-1 accuracy of 15.6% and a top-5 accuracy of 42.8% in 200-way zero-shot tasks. More importantly, extensive experiments analyzing the temporal, spatial, spectral, and semantic aspects of EEG signals demonstrate good biological plausibility. These results offer valuable insights for neural decoding and real-world applications of brain-computer interfaces. The code will be released on https://github.com/eeyhsong/NICE-EEG.
Text is NOT Enough: Integrating Visual Impressions into Open-domain Dialogue Generation
Sep 18, 2021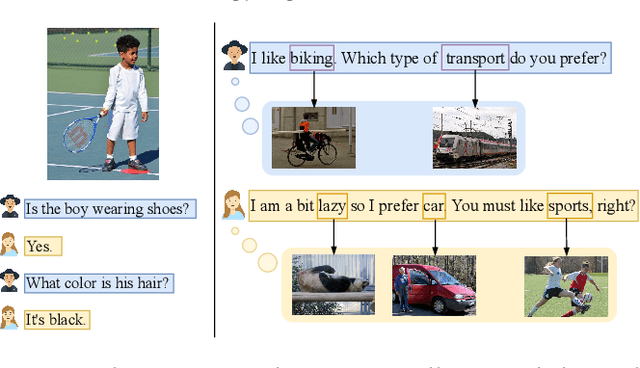
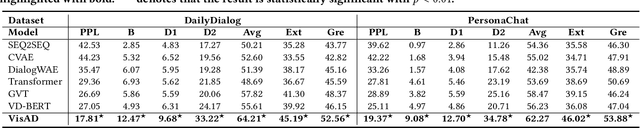
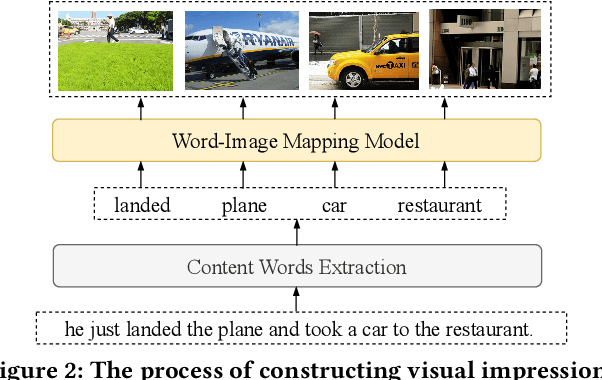
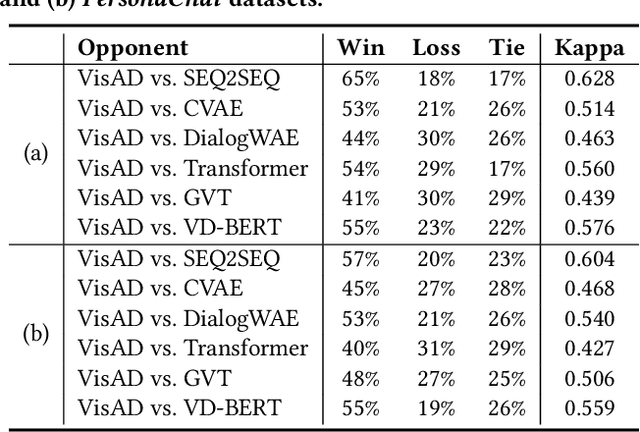
Open-domain dialogue generation in natural language processing (NLP) is by default a pure-language task, which aims to satisfy human need for daily communication on open-ended topics by producing related and informative responses. In this paper, we point out that hidden images, named as visual impressions (VIs), can be explored from the text-only data to enhance dialogue understanding and help generate better responses. Besides, the semantic dependency between an dialogue post and its response is complicated, e.g., few word alignments and some topic transitions. Therefore, the visual impressions of them are not shared, and it is more reasonable to integrate the response visual impressions (RVIs) into the decoder, rather than the post visual impressions (PVIs). However, both the response and its RVIs are not given directly in the test process. To handle the above issues, we propose a framework to explicitly construct VIs based on pure-language dialogue datasets and utilize them for better dialogue understanding and generation. Specifically, we obtain a group of images (PVIs) for each post based on a pre-trained word-image mapping model. These PVIs are used in a co-attention encoder to get a post representation with both visual and textual information. Since the RVIs are not provided directly during testing, we design a cascade decoder that consists of two sub-decoders. The first sub-decoder predicts the content words in response, and applies the word-image mapping model to get those RVIs. Then, the second sub-decoder generates the response based on the post and RVIs. Experimental results on two open-domain dialogue datasets show that our proposed approach achieves superior performance over competitive baselines.
Improving Sequential Recommendation Consistency with Self-Supervised Imitation
Jun 29, 2021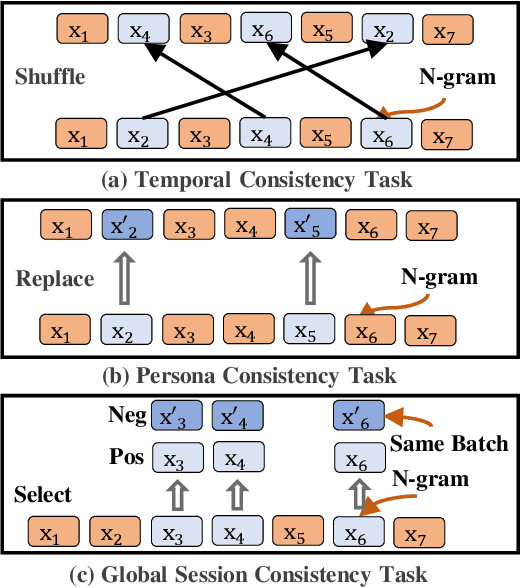
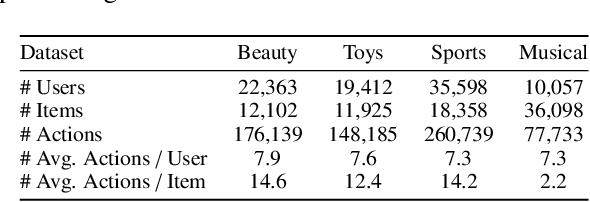
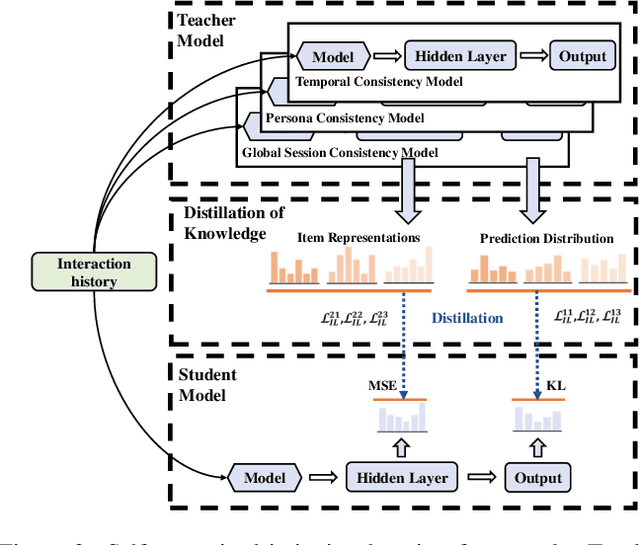
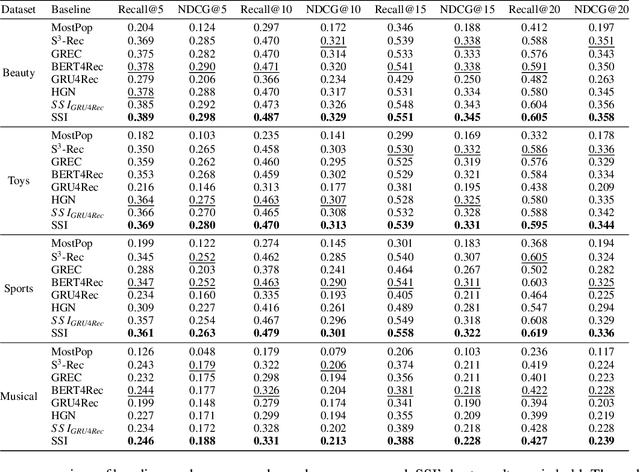
Most sequential recommendation models capture the features of consecutive items in a user-item interaction history. Though effective, their representation expressiveness is still hindered by the sparse learning signals. As a result, the sequential recommender is prone to make inconsistent predictions. In this paper, we propose a model, SSI, to improve sequential recommendation consistency with Self-Supervised Imitation. Precisely, we extract the consistency knowledge by utilizing three self-supervised pre-training tasks, where temporal consistency and persona consistency capture user-interaction dynamics in terms of the chronological order and persona sensitivities, respectively. Furthermore, to provide the model with a global perspective, global session consistency is introduced by maximizing the mutual information among global and local interaction sequences. Finally, to comprehensively take advantage of all three independent aspects of consistency-enhanced knowledge, we establish an integrated imitation learning framework. The consistency knowledge is effectively internalized and transferred to the student model by imitating the conventional prediction logit as well as the consistency-enhanced item representations. In addition, the flexible self-supervised imitation framework can also benefit other student recommenders. Experiments on four real-world datasets show that SSI effectively outperforms the state-of-the-art sequential recommendation methods.
Transformer-based Spatial-Temporal Feature Learning for EEG Decoding
Jun 11, 2021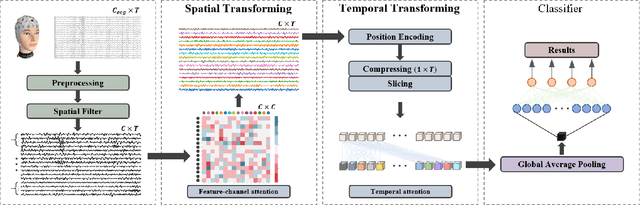
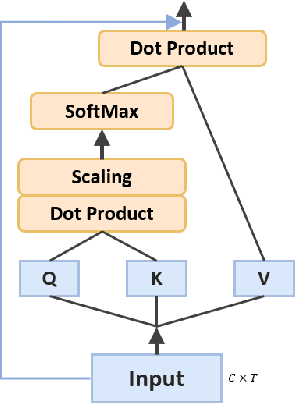
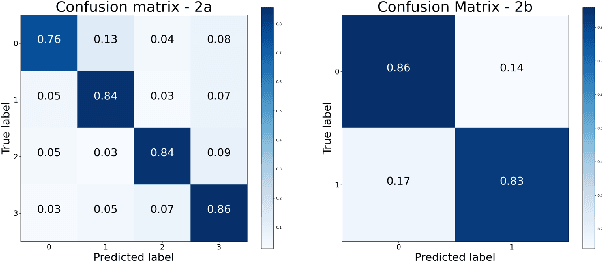
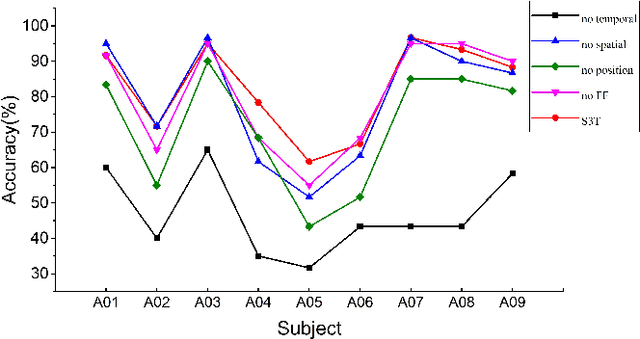
At present, people usually use some methods based on convolutional neural networks (CNNs) for Electroencephalograph (EEG) decoding. However, CNNs have limitations in perceiving global dependencies, which is not adequate for common EEG paradigms with a strong overall relationship. Regarding this issue, we propose a novel EEG decoding method that mainly relies on the attention mechanism. The EEG data is firstly preprocessed and spatially filtered. And then, we apply attention transforming on the feature-channel dimension so that the model can enhance more relevant spatial features. The most crucial step is to slice the data in the time dimension for attention transforming, and finally obtain a highly distinguishable representation. At this time, global averaging pooling and a simple fully-connected layer are used to classify different categories of EEG data. Experiments on two public datasets indicate that the strategy of attention transforming effectively utilizes spatial and temporal features. And we have reached the level of the state-of-the-art in multi-classification of EEG, with fewer parameters. As far as we know, it is the first time that a detailed and complete method based on the transformer idea has been proposed in this field. It has good potential to promote the practicality of brain-computer interface (BCI). The source code can be found at: \textit{https://github.com/anranknight/EEG-Transformer}.
Common Spatial Generative Adversarial Networks based EEG Data Augmentation for Cross-Subject Brain-Computer Interface
Feb 08, 2021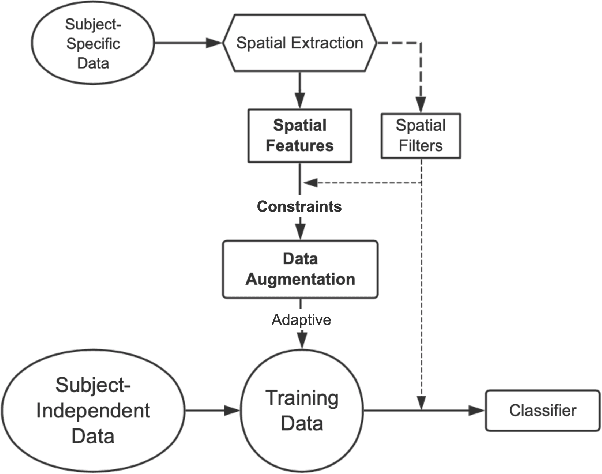
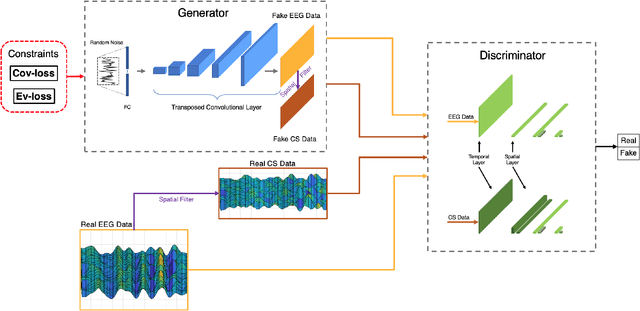
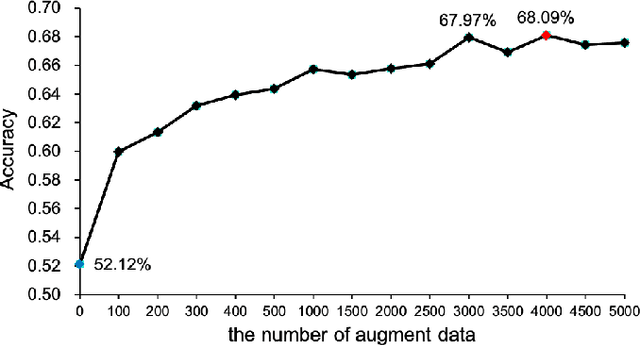
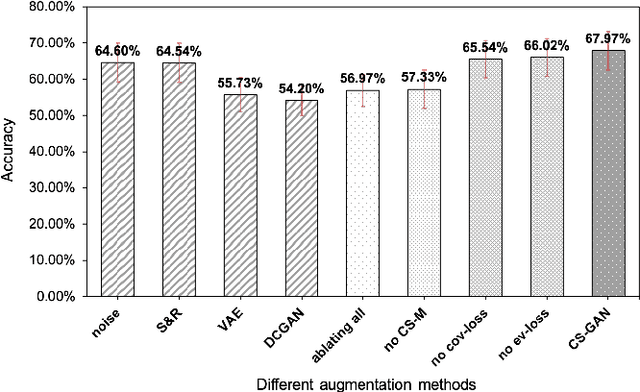
The cross-subject application of EEG-based brain-computer interface (BCI) has always been limited by large individual difference and complex characteristics that are difficult to perceive. Therefore, it takes a long time to collect the training data of each user for calibration. Even transfer learning method pre-training with amounts of subject-independent data cannot decode different EEG signal categories without enough subject-specific data. Hence, we proposed a cross-subject EEG classification framework with a generative adversarial networks (GANs) based method named common spatial GAN (CS-GAN), which used adversarial training between a generator and a discriminator to obtain high-quality data for augmentation. A particular module in the discriminator was employed to maintain the spatial features of the EEG signals and increase the difference between different categories, with two losses for further enhancement. Through adaptive training with sufficient augmentation data, our cross-subject classification accuracy yielded a significant improvement of 15.85% than leave-one subject-out (LOO) test and 8.57% than just adapting 100 original samples on the dataset 2a of BCI competition IV. Moreover, We designed a convolutional neural networks (CNNs) based classification method as a benchmark with a similar spatial enhancement idea, which achieved remarkable results to classify motor imagery EEG data. In summary, our framework provides a promising way to deal with the cross-subject problem and promote the practical application of BCI.
Group-wise Contrastive Learning for Neural Dialogue Generation
Oct 13, 2020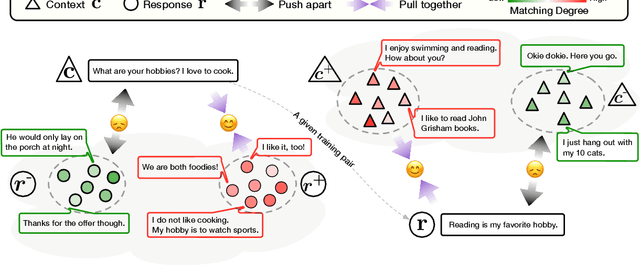
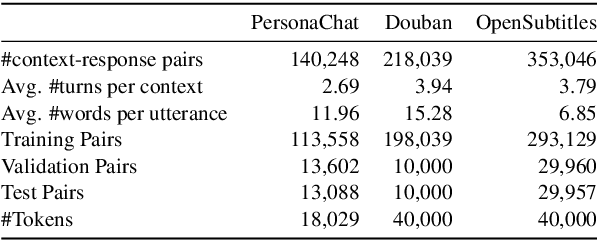
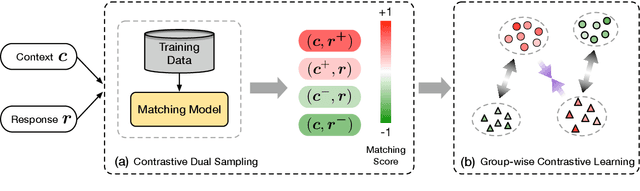
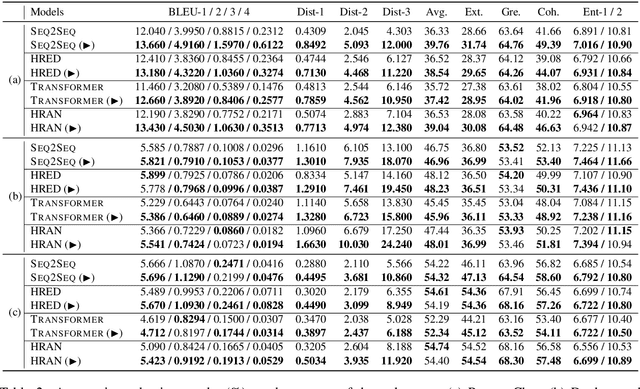
Neural dialogue response generation has gained much popularity in recent years. Maximum Likelihood Estimation (MLE) objective is widely adopted in existing dialogue model learning. However, models trained with MLE objective function are plagued by the low-diversity issue when it comes to the open-domain conversational setting. Inspired by the observation that humans not only learn from the positive signals but also benefit from correcting behaviors of undesirable actions, in this work, we introduce contrastive learning into dialogue generation, where the model explicitly perceives the difference between the well-chosen positive and negative utterances. Specifically, we employ a pretrained baseline model as a reference. During contrastive learning, the target dialogue model is trained to give higher conditional probabilities for the positive samples, and lower conditional probabilities for those negative samples, compared to the reference model. To manage the multi-mapping relations prevailed in human conversation, we augment contrastive dialogue learning with group-wise dual sampling. Extensive experimental results show that the proposed group-wise contrastive learning framework is suited for training a wide range of neural dialogue generation models with very favorable performance over the baseline training approaches.