 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Structured Semantic Prior for Multi Label Recognition with Incomplete Labels
Mar 24, 2023



Multi-label recognition (MLR) with incomplete labels is very challenging. Recent works strive to explore the image-to-label correspondence in the vision-language model, \ie, CLIP, to compensate for insufficient annotations. In spite of promising performance, they generally overlook the valuable prior about the label-to-label correspondence. In this paper, we advocate remedying the deficiency of label supervision for the MLR with incomplete labels by deriving a structured semantic prior about the label-to-label correspondence via a semantic prior prompter. We then present a novel Semantic Correspondence Prompt Network (SCPNet), which can thoroughly explore the structured semantic prior. A Prior-Enhanced Self-Supervised Learning method is further introduced to enhance the use of the prior. Comprehensive experiments and analyses on several widely used benchmark datasets show that our method significantly outperforms existing methods on all datasets, well demonstrating the effectiveness and the superiority of our method. Our code will be available at https://github.com/jameslahm/SCPNet.
* Accepted by IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2023
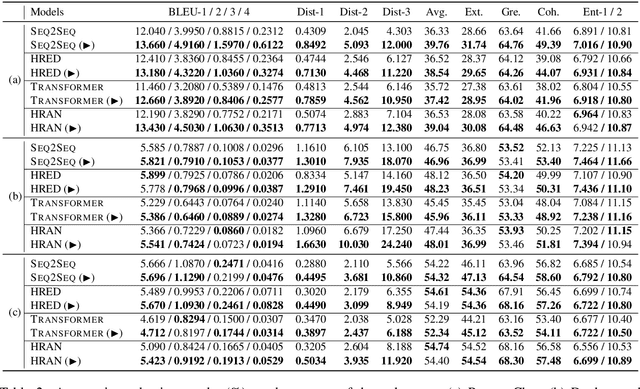
Learning Multi-Stage Multi-Grained Semantic Embeddings for E-Commerce Search
Mar 20, 2023



Retrieving relevant items that match users' queries from billion-scale corpus forms the core of industrial e-commerce search systems, in which embedding-based retrieval (EBR) methods are prevailing. These methods adopt a two-tower framework to learn embedding vectors for query and item separately and thus leverage efficient approximate nearest neighbor (ANN) search to retrieve relevant items. However, existing EBR methods usually ignore inconsistent user behaviors in industrial multi-stage search systems, resulting in insufficient retrieval efficiency with a low commercial return. To tackle this challenge, we propose to improve EBR methods by learning Multi-level Multi-Grained Semantic Embeddings(MMSE). We propose the multi-stage information mining to exploit the ordered, clicked, unclicked and random sampled items in practical user behavior data, and then capture query-item similarity via a post-fusion strategy. We then propose multi-grained learning objectives that integrate the retrieval loss with global comparison ability and the ranking loss with local comparison ability to generate semantic embeddings. Both experiments on a real-world billion-scale dataset and online A/B tests verify the effectiveness of MMSE in achieving significant performance improvements on metrics such as offline recall and online conversion rate (CVR).
Adaptive Experimentation with Delayed Binary Feedback
Feb 02, 2022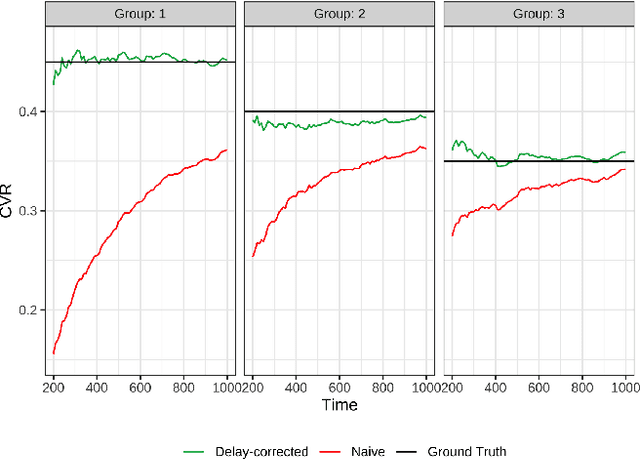
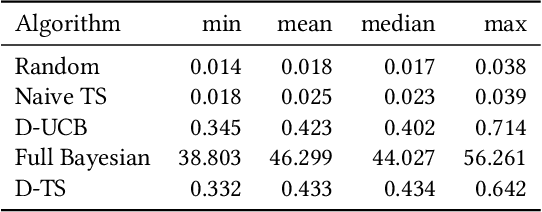
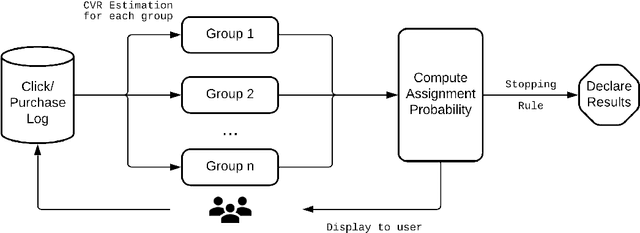
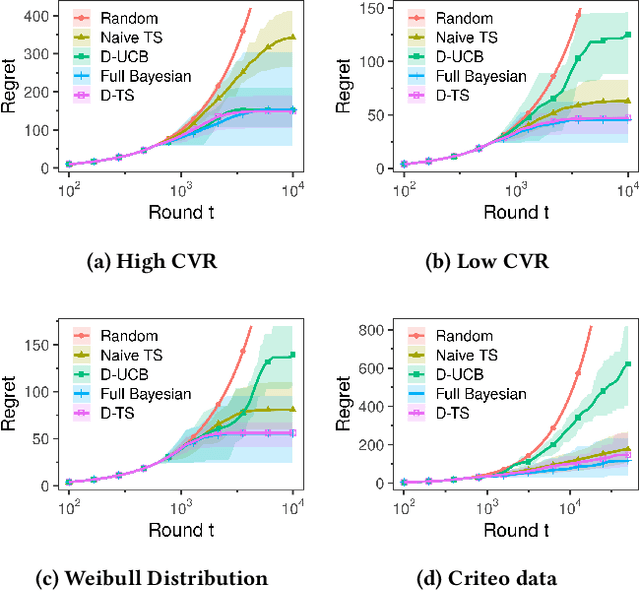
Conducting experiments with objectives that take significant delays to materialize (e.g. conversions, add-to-cart events, etc.) is challenging. Although the classical "split sample testing" is still valid for the delayed feedback, the experiment will take longer to complete, which also means spending more resources on worse-performing strategies due to their fixed allocation schedules. Alternatively, adaptive approaches such as "multi-armed bandits" are able to effectively reduce the cost of experimentation. But these methods generally cannot handle delayed objectives directly out of the box. This paper presents an adaptive experimentation solution tailored for delayed binary feedback objectives by estimating the real underlying objectives before they materialize and dynamically allocating variants based on the estimates. Experiments show that the proposed method is more efficient for delayed feedback compared to various other approaches and is robust in different settings. In addition, we describe an experimentation product powered by this algorithm. This product is currently deployed in the online experimentation platform of JD.com, a large e-commerce company and a publisher of digital ads.
Blending Advertising with Organic Content in E-Commerce: A Virtual Bids Optimization Approach
May 28, 2021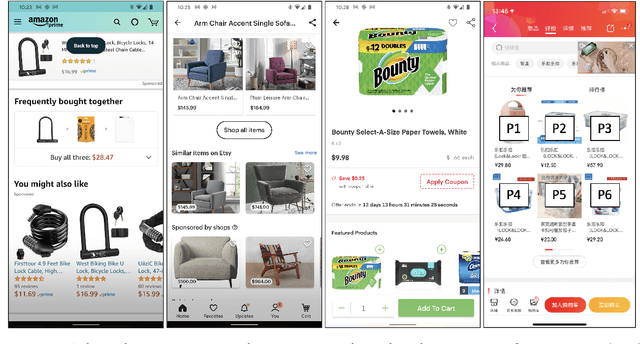
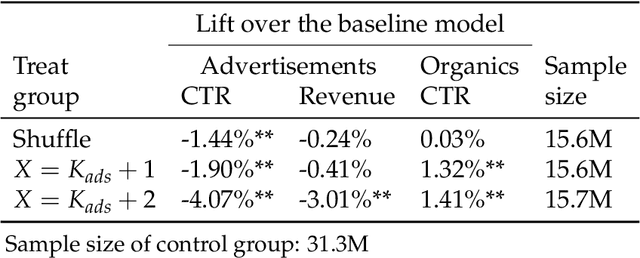
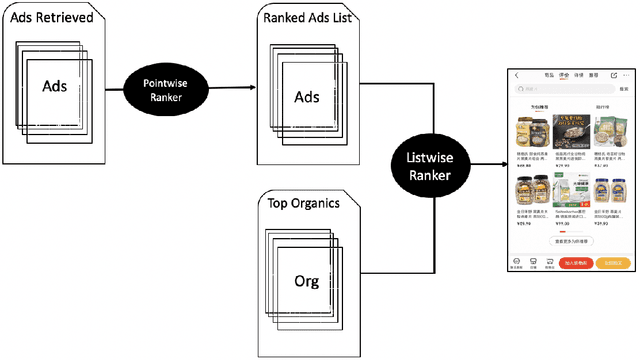
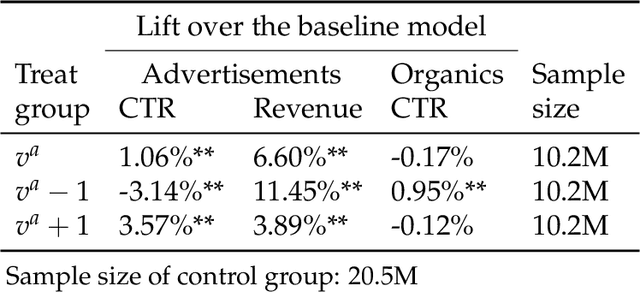
In e-commerce platforms, sponsored and non-sponsored content are jointly displayed to users and both may interactively influence their engagement behavior. The former content helps advertisers achieve their marketing goals and provides a stream of ad revenue to the platform. The latter content contributes to users' engagement with the platform, which is key to its long-term health. A burning issue for e-commerce platform design is how to blend advertising with content in a way that respects these interactions and balances these multiple business objectives. This paper describes a system developed for this purpose in the context of blending personalized sponsored content with non-sponsored content on the product detail pages of JD.COM, an e-commerce company. This system has three key features: (1) Optimization of multiple competing business objectives through a new virtual bids approach and the expressiveness of the latent, implicit valuation of the platform for the multiple objectives via these virtual bids. (2) Modeling of users' click behavior as a function of their characteristics, the individual characteristics of each sponsored content and the influence exerted by other sponsored and non-sponsored content displayed alongside through a deep learning approach; (3) Consideration of externalities in the allocation of ads, thereby making it directly compatible with a Vickrey-Clarke-Groves (VCG) auction scheme for the computation of payments in the presence of these externalities. The system is currently deployed and serving all traffic through JD.COM's mobile application. Experiments demonstrating the performance and advantages of the system are presented.
Probing Product Description Generation via Posterior Distillation
Mar 02, 2021

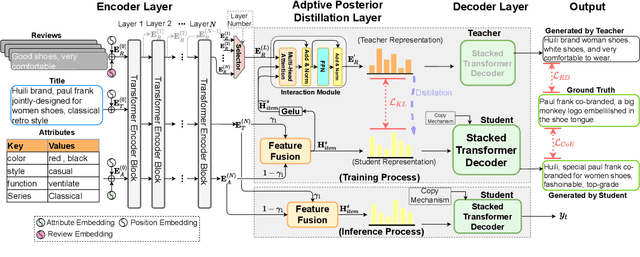

In product description generation (PDG), the user-cared aspect is critical for the recommendation system, which can not only improve user's experiences but also obtain more clicks. High-quality customer reviews can be considered as an ideal source to mine user-cared aspects. However, in reality, a large number of new products (known as long-tailed commodities) cannot gather sufficient amount of customer reviews, which brings a big challenge in the product description generation task. Existing works tend to generate the product description solely based on item information, i.e., product attributes or title words, which leads to tedious contents and cannot attract customers effectively. To tackle this problem, we propose an adaptive posterior network based on Transformer architecture that can utilize user-cared information from customer reviews. Specifically, we first extend the self-attentive Transformer encoder to encode product titles and attributes. Then, we apply an adaptive posterior distillation module to utilize useful review information, which integrates user-cared aspects to the generation process. Finally, we apply a Transformer-based decoding phase with copy mechanism to automatically generate the product description. Besides, we also collect a large-scare Chinese product description dataset to support our work and further research in this field. Experimental results show that our model is superior to traditional generative models in both automatic indicators and human evaluation.
DADNN: Multi-Scene CTR Prediction via Domain-Aware Deep Neural Network
Nov 24, 2020
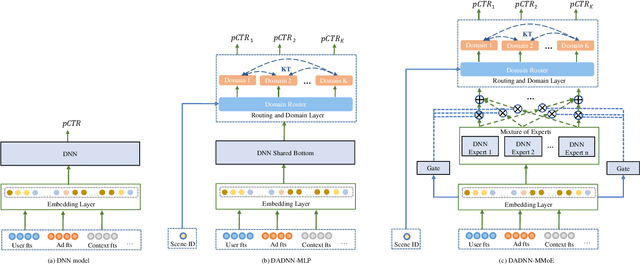
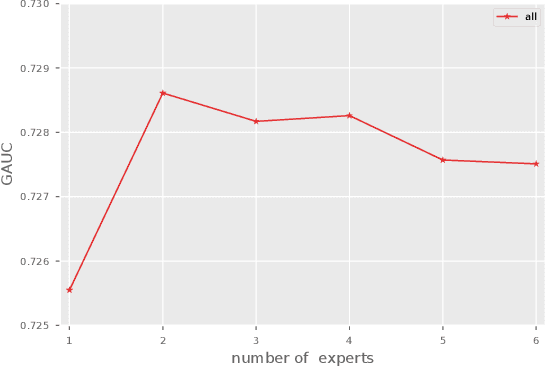
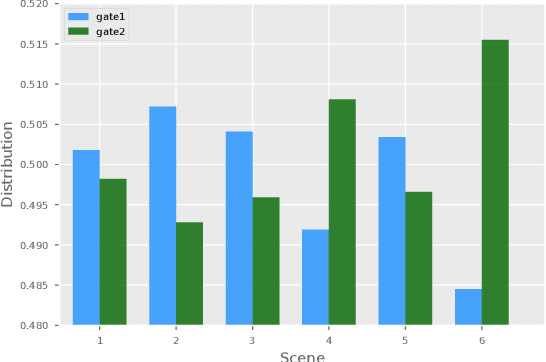
Click through rate(CTR) prediction is a core task in advertising systems. The booming e-commerce business in our company, results in a growing number of scenes. Most of them are so-called long-tail scenes, which means that the traffic of a single scene is limited, but the overall traffic is considerable. Typical studies mainly focus on serving a single scene with a well designed model. However, this method brings excessive resource consumption both on offline training and online serving. Besides, simply training a single model with data from multiple scenes ignores the characteristics of their own. To address these challenges, we propose a novel but practical model named Domain-Aware Deep Neural Network(DADNN) by serving multiple scenes with only one model. Specifically, shared bottom block among all scenes is applied to learn a common representation, while domain-specific heads maintain the characteristics of every scene. Besides, knowledge transfer is introduced to enhance the opportunity of knowledge sharing among different scenes. In this paper, we study two instances of DADNN where its shared bottom block is multilayer perceptron(MLP) and Multi-gate Mixture-of-Experts(MMoE) respectively, for which we denote as DADNN-MLP and DADNN-MMoE.Comprehensive offline experiments on a real production dataset from our company show that DADNN outperforms several state-of-the-art methods for multi-scene CTR prediction. Extensive online A/B tests reveal that DADNN-MLP contributes up to 6.7% CTR and 3.0% CPM(Cost Per Mille) promotion compared with a well-engineered DCN model. Furthermore, DADNN-MMoE outperforms DADNN-MLP with a relative improvement of 2.2% and 2.7% on CTR and CPM respectively. More importantly, DADNN utilizes a single model for multiple scenes which saves a lot of offline training and online serving resources.
BERT2DNN: BERT Distillation with Massive Unlabeled Data for Online E-Commerce Search
Oct 20, 2020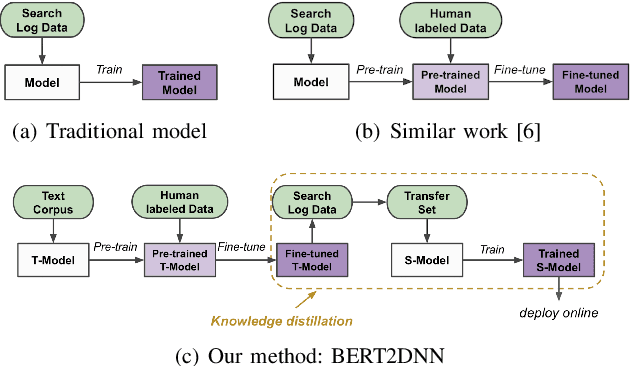

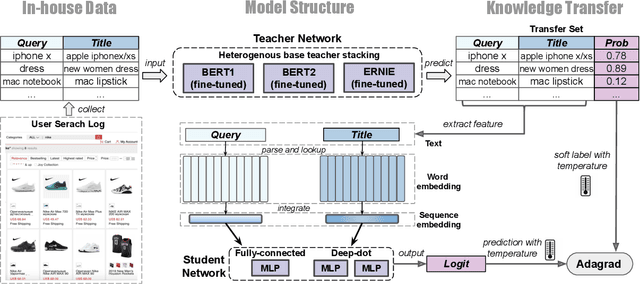
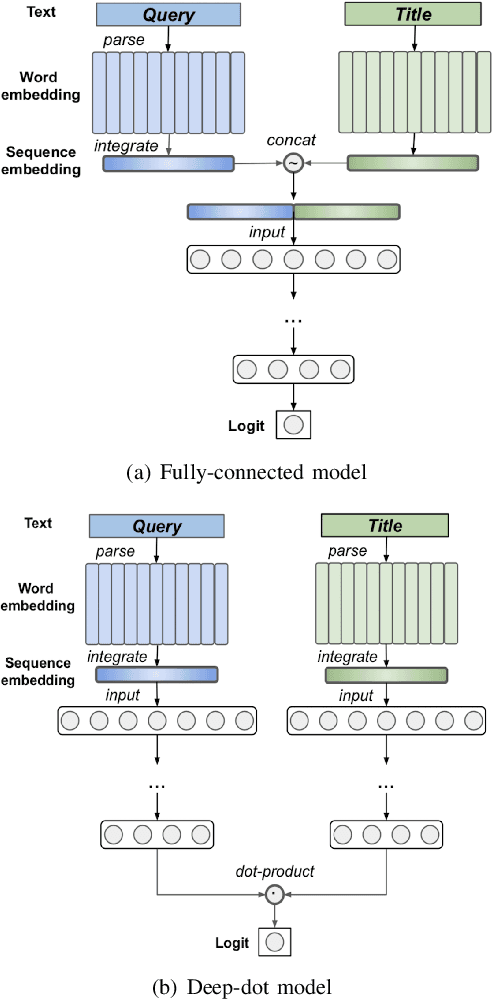
Relevance has significant impact on user experience and business profit for e-commerce search platform. In this work, we propose a data-driven framework for search relevance prediction, by distilling knowledge from BERT and related multi-layer Transformer teacher models into simple feed-forward networks with large amount of unlabeled data. The distillation process produces a student model that recovers more than 97\% test accuracy of teacher models on new queries, at a serving cost that's several magnitude lower (latency 150x lower than BERT-Base and 15x lower than the most efficient BERT variant, TinyBERT). The applications of temperature rescaling and teacher model stacking further boost model accuracy, without increasing the student model complexity. We present experimental results on both in-house e-commerce search relevance data as well as a public data set on sentiment analysis from the GLUE benchmark. The latter takes advantage of another related public data set of much larger scale, while disregarding its potentially noisy labels. Embedding analysis and case study on the in-house data further highlight the strength of the resulting model. By making the data processing and model training source code public, we hope the techniques presented here can help reduce energy consumption of the state of the art Transformer models and also level the playing field for small organizations lacking access to cutting edge machine learning hardwares.
Kalman Filtering Attention for User Behavior Modeling in CTR Prediction
Oct 20, 2020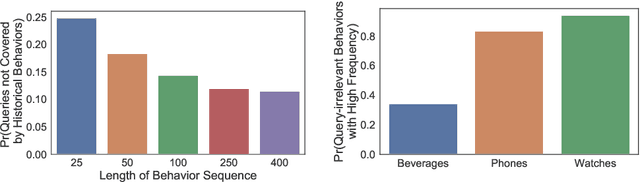


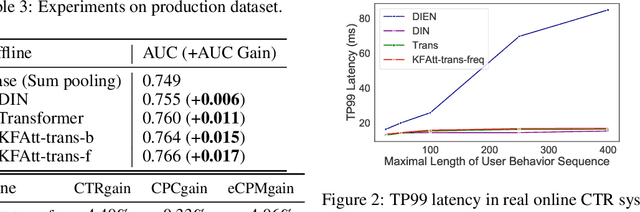
Click-through rate (CTR) prediction is one of the fundamental tasks for e-commerce search engines. As search becomes more personalized, it is necessary to capture the user interest from rich behavior data. Existing user behavior modeling algorithms develop different attention mechanisms to emphasize query-relevant behaviors and suppress irrelevant ones. Despite being extensively studied, these attentions still suffer from two limitations. First, conventional attentions mostly limit the attention field only to a single user's behaviors, which is not suitable in e-commerce where users often hunt for new demands that are irrelevant to any historical behaviors. Second, these attentions are usually biased towards frequent behaviors, which is unreasonable since high frequency does not necessarily indicate great importance. To tackle the two limitations, we propose a novel attention mechanism, termed Kalman Filtering Attention (KFAtt), that considers the weighted pooling in attention as a maximum a posteriori (MAP) estimation. By incorporating a priori, KFAtt resorts to global statistics when few user behaviors are relevant. Moreover, a frequency capping mechanism is incorporated to correct the bias towards frequent behaviors. Offline experiments on both benchmark and a 10 billion scale real production dataset, together with an Online A/B test, show that KFAtt outperforms all compared state-of-the-arts. KFAtt has been deployed in the ranking system of a leading e commerce website, serving the main traffic of hundreds of millions of active users everyday.
Group-wise Contrastive Learning for Neural Dialogue Generation
Oct 13, 2020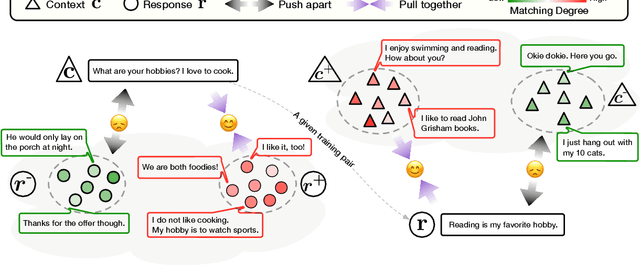
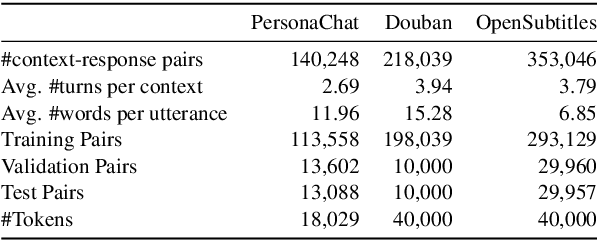
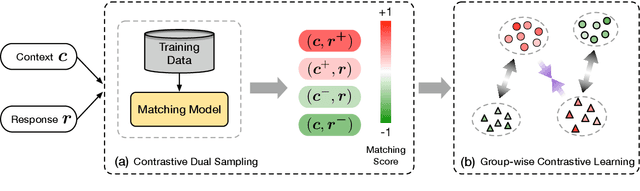
Neural dialogue response generation has gained much popularity in recent years. Maximum Likelihood Estimation (MLE) objective is widely adopted in existing dialogue model learning. However, models trained with MLE objective function are plagued by the low-diversity issue when it comes to the open-domain conversational setting. Inspired by the observation that humans not only learn from the positive signals but also benefit from correcting behaviors of undesirable actions, in this work, we introduce contrastive learning into dialogue generation, where the model explicitly perceives the difference between the well-chosen positive and negative utterances. Specifically, we employ a pretrained baseline model as a reference. During contrastive learning, the target dialogue model is trained to give higher conditional probabilities for the positive samples, and lower conditional probabilities for those negative samples, compared to the reference model. To manage the multi-mapping relations prevailed in human conversation, we augment contrastive dialogue learning with group-wise dual sampling. Extensive experimental results show that the proposed group-wise contrastive learning framework is suited for training a wide range of neural dialogue generation models with very favorable performance over the baseline training approaches.
Adversarial Mixture Of Experts with Category Hierarchy Soft Constraint
Jul 27, 2020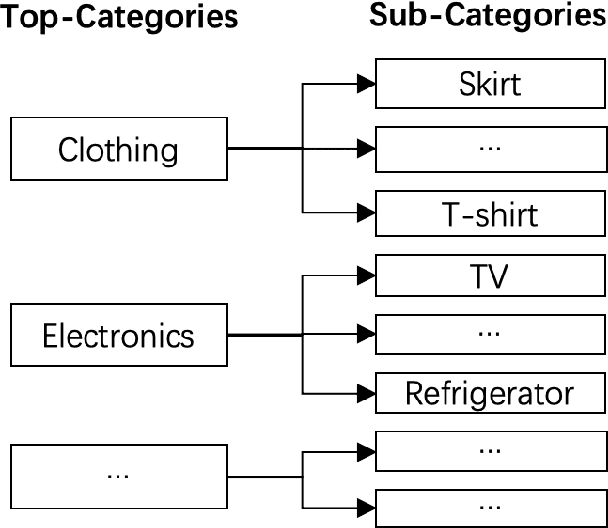
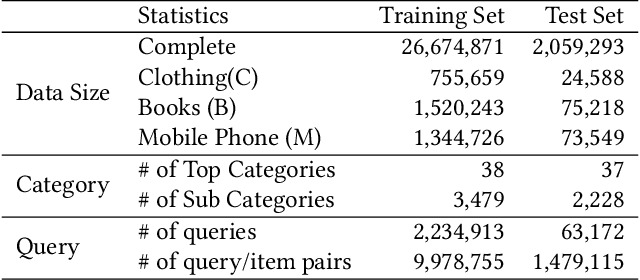
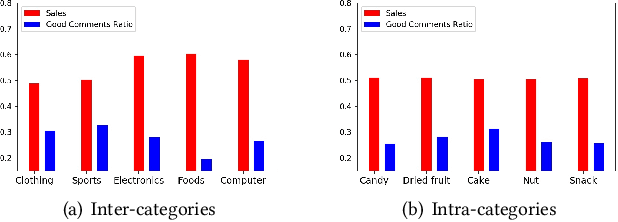
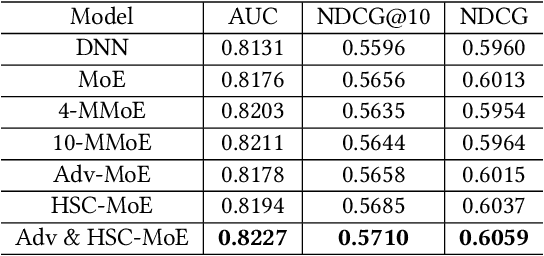
Product search is the most common way for people to satisfy their shopping needs on e-commerce websites. Products are typically annotated with one of several broad categorical tags, such as "Clothing" or "Electronics", as well as finer-grained categories like "Refrigerator" or "TV", both under "Electronics". These tags are used to construct a hierarchy of query categories. Feature distributions such as price and brand popularity vary wildly across query categories. In addition, feature importance for the purpose of CTR/CVR predictions differs from one category to another. In this work, we leverage the Mixture of Expert (MoE) framework to learn a ranking model that specializes for each query category. In particular, our gate network relies solely on the category ids extracted from the user query. While classical MoE's pick expert towers spontaneously for each input example, we explore two techniques to establish more explicit and transparent connections between the experts and query categories. To help differentiate experts on their domain specialties, we introduce a form of adversarial regularization among the expert outputs, forcing them to disagree with one another. As a result, they tend to approach each prediction problem from different angles, rather than copying one another. This is validated by a much stronger clustering effect of the gate output vectors under different categories. In addition, soft gating constraints based on the categorical hierarchy are imposed to help similar products choose similar gate values. and make them more likely to share similar experts. This allows aggregation of training data among smaller sibling categories to overcome data scarcity issues among the latter. Experiments on a learning-to-rank dataset gathered from a leading e-commerce search log demonstrate that MoE with our improvements consistently outperforms competing models.