 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelevance Matters: A Multi-Task and Multi-Stage Large Language Model Approach for E-commerce Query Rewriting
Mar 03, 2026For e-commerce search, user experience is measured by users' behavioral responses to returned products, like click-through rate and conversion rate, as well as the relevance between returned products and search queries. Consequently, relevance and user conversion constitute the two primary objectives in query rewriting, a strategy to bridge the lexical gap between user expressions and product descriptions. This research proposes a multi-task and multi-stage query rewriting framework grounded in large language models (LLMs). Critically, in contrast to previous works that primarily emphasized rewritten query generation, we inject the relevance task into query rewriting. Specifically, leveraging a pretrained model on user data and product information from JD.com, the approach initiates with multi-task supervised fine-tuning (SFT) comprising of the rewritten query generation task and the relevance tagging task between queries and rewrites. Subsequently, we employ Group Relative Policy Optimization (GRPO) for the model's objective alignment oriented toward enhancing the relevance and stimulating user conversions. Through offline evaluation and online A/B test, our framework illustrates substantial improvements in the effectiveness of e-commerce query rewriting, resulting in elevating the search results' relevance and boosting the number of purchases made per user (UCVR). Since August 2025, our approach has been implemented on JD.com, one of China's leading online shopping platforms.
A Simple and Effective Framework for Symmetric Consistent Indexing in Large-Scale Dense Retrieval
Dec 15, 2025Dense retrieval has become the industry standard in large-scale information retrieval systems due to its high efficiency and competitive accuracy. Its core relies on a coarse-to-fine hierarchical architecture that enables rapid candidate selection and precise semantic matching, achieving millisecond-level response over billion-scale corpora. This capability makes it essential not only in traditional search and recommendation scenarios but also in the emerging paradigm of generative recommendation driven by large language models, where semantic IDs-themselves a form of coarse-to-fine representation-play a foundational role. However, the widely adopted dual-tower encoding architecture introduces inherent challenges, primarily representational space misalignment and retrieval index inconsistency, which degrade matching accuracy, retrieval stability, and performance on long-tail queries. These issues are further magnified in semantic ID generation, ultimately limiting the performance ceiling of downstream generative models. To address these challenges, this paper proposes a simple and effective framework named SCI comprising two synergistic modules: a symmetric representation alignment module that employs an innovative input-swapping mechanism to unify the dual-tower representation space without adding parameters, and an consistent indexing with dual-tower synergy module that redesigns retrieval paths using a dual-view indexing strategy to maintain consistency from training to inference. The framework is systematic, lightweight, and engineering-friendly, requiring minimal overhead while fully supporting billion-scale deployment. We provide theoretical guarantees for our approach, with its effectiveness validated by results across public datasets and real-world e-commerce datasets.
LREF: A Novel LLM-based Relevance Framework for E-commerce
Mar 12, 2025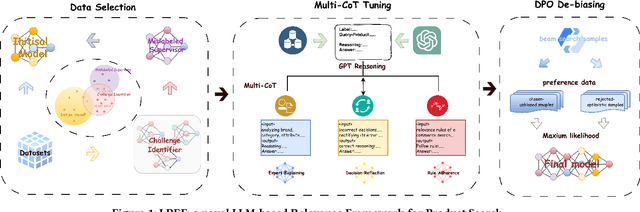
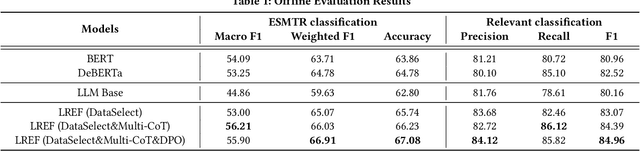


Query and product relevance prediction is a critical component for ensuring a smooth user experience in e-commerce search. Traditional studies mainly focus on BERT-based models to assess the semantic relevance between queries and products. However, the discriminative paradigm and limited knowledge capacity of these approaches restrict their ability to comprehend the relevance between queries and products fully. With the rapid advancement of Large Language Models (LLMs), recent research has begun to explore their application to industrial search systems, as LLMs provide extensive world knowledge and flexible optimization for reasoning processes. Nonetheless, directly leveraging LLMs for relevance prediction tasks introduces new challenges, including a high demand for data quality, the necessity for meticulous optimization of reasoning processes, and an optimistic bias that can result in over-recall. To overcome the above problems, this paper proposes a novel framework called the LLM-based RElevance Framework (LREF) aimed at enhancing e-commerce search relevance. The framework comprises three main stages: supervised fine-tuning (SFT) with Data Selection, Multiple Chain of Thought (Multi-CoT) tuning, and Direct Preference Optimization (DPO) for de-biasing. We evaluate the performance of the framework through a series of offline experiments on large-scale real-world datasets, as well as online A/B testing. The results indicate significant improvements in both offline and online metrics. Ultimately, the model was deployed in a well-known e-commerce application, yielding substantial commercial benefits.
Breaking the Hourglass Phenomenon of Residual Quantization: Enhancing the Upper Bound of Generative Retrieval
Jul 31, 2024



Generative retrieval (GR) has emerged as a transformative paradigm in search and recommender systems, leveraging numeric-based identifier representations to enhance efficiency and generalization. Notably, methods like TIGER employing Residual Quantization-based Semantic Identifiers (RQ-SID), have shown significant promise in e-commerce scenarios by effectively managing item IDs. However, a critical issue termed the "\textbf{Hourglass}" phenomenon, occurs in RQ-SID, where intermediate codebook tokens become overly concentrated, hindering the full utilization of generative retrieval methods. This paper analyses and addresses this problem by identifying data sparsity and long-tailed distribution as the primary causes. Through comprehensive experiments and detailed ablation studies, we analyze the impact of these factors on codebook utilization and data distribution. Our findings reveal that the "Hourglass" phenomenon substantially impacts the performance of RQ-SID in generative retrieval. We propose effective solutions to mitigate this issue, thereby significantly enhancing the effectiveness of generative retrieval in real-world E-commerce applications.
Generative Retrieval with Preference Optimization for E-commerce Search
Jul 29, 2024Generative retrieval introduces a groundbreaking paradigm to document retrieval by directly generating the identifier of a pertinent document in response to a specific query. This paradigm has demonstrated considerable benefits and potential, particularly in representation and generalization capabilities, within the context of large language models. However, it faces significant challenges in E-commerce search scenarios, including the complexity of generating detailed item titles from brief queries, the presence of noise in item titles with weak language order, issues with long-tail queries, and the interpretability of results. To address these challenges, we have developed an innovative framework for E-commerce search, called generative retrieval with preference optimization. This framework is designed to effectively learn and align an autoregressive model with target data, subsequently generating the final item through constraint-based beam search. By employing multi-span identifiers to represent raw item titles and transforming the task of generating titles from queries into the task of generating multi-span identifiers from queries, we aim to simplify the generation process. The framework further aligns with human preferences using click data and employs a constrained search method to identify key spans for retrieving the final item, thereby enhancing result interpretability. Our extensive experiments show that this framework achieves competitive performance on a real-world dataset, and online A/B tests demonstrate the superiority and effectiveness in improving conversion gains.
MODRL-TA:A Multi-Objective Deep Reinforcement Learning Framework for Traffic Allocation in E-Commerce Search
Jul 22, 2024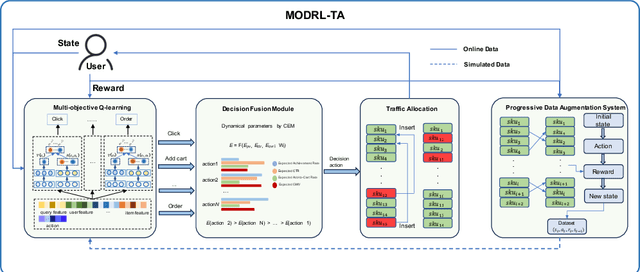
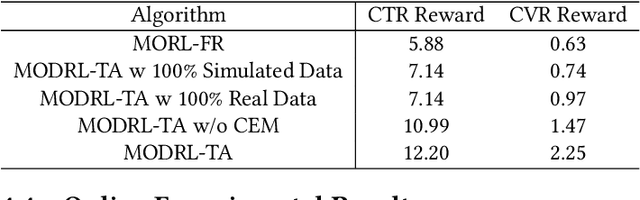
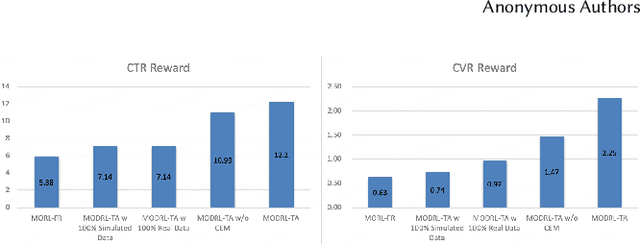
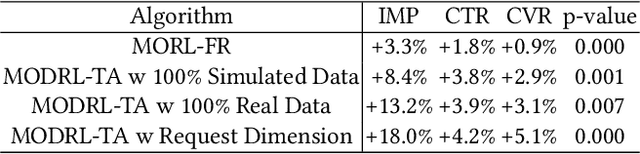
Traffic allocation is a process of redistributing natural traffic to products by adjusting their positions in the post-search phase, aimed at effectively fostering merchant growth, precisely meeting customer demands, and ensuring the maximization of interests across various parties within e-commerce platforms. Existing methods based on learning to rank neglect the long-term value of traffic allocation, whereas approaches of reinforcement learning suffer from balancing multiple objectives and the difficulties of cold starts within realworld data environments. To address the aforementioned issues, this paper propose a multi-objective deep reinforcement learning framework consisting of multi-objective Q-learning (MOQ), a decision fusion algorithm (DFM) based on the cross-entropy method(CEM), and a progressive data augmentation system(PDA). Specifically. MOQ constructs ensemble RL models, each dedicated to an objective, such as click-through rate, conversion rate, etc. These models individually determine the position of items as actions, aiming to estimate the long-term value of multiple objectives from an individual perspective. Then we employ DFM to dynamically adjust weights among objectives to maximize long-term value, addressing temporal dynamics in objective preferences in e-commerce scenarios. Initially, PDA trained MOQ with simulated data from offline logs. As experiments progressed, it strategically integrated real user interaction data, ultimately replacing the simulated dataset to alleviate distributional shifts and the cold start problem. Experimental results on real-world online e-commerce systems demonstrate the significant improvements of MODRL-TA, and we have successfully deployed MODRL-TA on an e-commerce search platform.
A Preference-oriented Diversity Model Based on Mutual-information in Re-ranking for E-commerce Search
May 24, 2024Re-ranking is a process of rearranging ranking list to more effectively meet user demands by accounting for the interrelationships between items. Existing methods predominantly enhance the precision of search results, often at the expense of diversity, leading to outcomes that may not fulfill the varied needs of users. Conversely, methods designed to promote diversity might compromise the precision of the results, failing to satisfy the users' requirements for accuracy. To alleviate the above problems, this paper proposes a Preference-oriented Diversity Model Based on Mutual-information (PODM-MI), which consider both accuracy and diversity in the re-ranking process. Specifically, PODM-MI adopts Multidimensional Gaussian distributions based on variational inference to capture users' diversity preferences with uncertainty. Then we maximize the mutual information between the diversity preferences of the users and the candidate items using the maximum variational inference lower bound to enhance their correlations. Subsequently, we derive a utility matrix based on the correlations, enabling the adaptive ranking of items in line with user preferences and establishing a balance between the aforementioned objectives. Experimental results on real-world online e-commerce systems demonstrate the significant improvements of PODM-MI, and we have successfully deployed PODM-MI on an e-commerce search platform.
Optimizing E-commerce Search: Toward a Generalizable and Rank-Consistent Pre-Ranking Model
May 09, 2024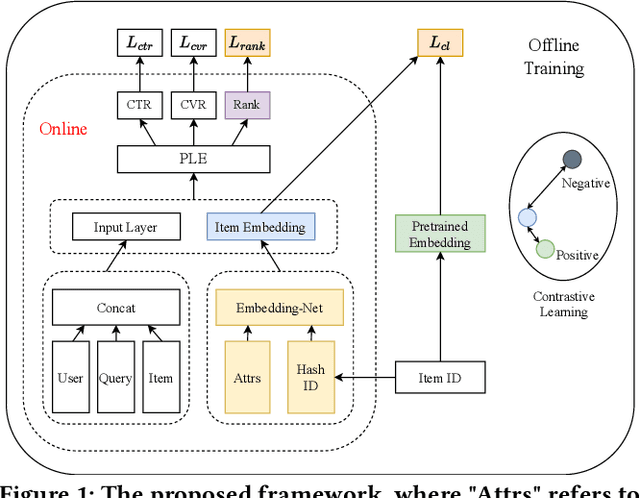

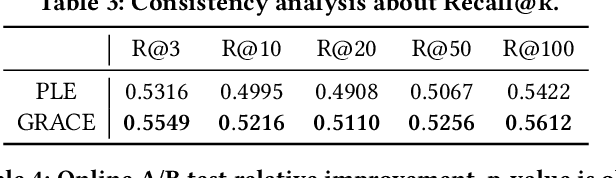
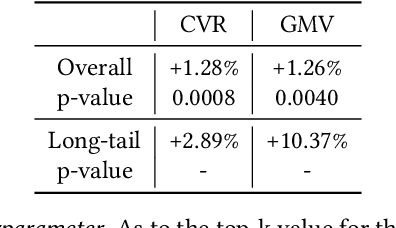
In large e-commerce platforms, search systems are typically composed of a series of modules, including recall, pre-ranking, and ranking phases. The pre-ranking phase, serving as a lightweight module, is crucial for filtering out the bulk of products in advance for the downstream ranking module. Industrial efforts on optimizing the pre-ranking model have predominantly focused on enhancing ranking consistency, model structure, and generalization towards long-tail items. Beyond these optimizations, meeting the system performance requirements presents a significant challenge. Contrasting with existing industry works, we propose a novel method: a Generalizable and RAnk-ConsistEnt Pre-Ranking Model (GRACE), which achieves: 1) Ranking consistency by introducing multiple binary classification tasks that predict whether a product is within the top-k results as estimated by the ranking model, which facilitates the addition of learning objectives on common point-wise ranking models; 2) Generalizability through contrastive learning of representation for all products by pre-training on a subset of ranking product embeddings; 3) Ease of implementation in feature construction and online deployment. Our extensive experiments demonstrate significant improvements in both offline metrics and online A/B test: a 0.75% increase in AUC and a 1.28% increase in CVR.
Attention Weighted Mixture of Experts with Contrastive Learning for Personalized Ranking in E-commerce
Jun 08, 2023



Ranking model plays an essential role in e-commerce search and recommendation. An effective ranking model should give a personalized ranking list for each user according to the user preference. Existing algorithms usually extract a user representation vector from the user behavior sequence, then feed the vector into a feed-forward network (FFN) together with other features for feature interactions, and finally produce a personalized ranking score. Despite tremendous progress in the past, there is still room for improvement. Firstly, the personalized patterns of feature interactions for different users are not explicitly modeled. Secondly, most of existing algorithms have poor personalized ranking results for long-tail users with few historical behaviors due to the data sparsity. To overcome the two challenges, we propose Attention Weighted Mixture of Experts (AW-MoE) with contrastive learning for personalized ranking. Firstly, AW-MoE leverages the MoE framework to capture personalized feature interactions for different users. To model the user preference, the user behavior sequence is simultaneously fed into expert networks and the gate network. Within the gate network, one gate unit and one activation unit are designed to adaptively learn the fine-grained activation vector for experts using an attention mechanism. Secondly, a random masking strategy is applied to the user behavior sequence to simulate long-tail users, and an auxiliary contrastive loss is imposed to the output of the gate network to improve the model generalization for these users. This is validated by a higher performance gain on the long-tail user test set. Experiment results on a JD real production dataset and a public dataset demonstrate the effectiveness of AW-MoE, which significantly outperforms state-of-art methods. Notably, AW-MoE has been successfully deployed in the JD e-commerce search engine, ...
JDsearch: A Personalized Product Search Dataset with Real Queries and Full Interactions
May 24, 2023



Recently, personalized product search attracts great attention and many models have been proposed. To evaluate the effectiveness of these models, previous studies mainly utilize the simulated Amazon recommendation dataset, which contains automatically generated queries and excludes cold users and tail products. We argue that evaluating with such a dataset may yield unreliable results and conclusions, and deviate from real user satisfaction. To overcome these problems, in this paper, we release a personalized product search dataset comprised of real user queries and diverse user-product interaction types (clicking, adding to cart, following, and purchasing) collected from JD.com, a popular Chinese online shopping platform. More specifically, we sample about 170,000 active users on a specific date, then record all their interacted products and issued queries in one year, without removing any tail users and products. This finally results in roughly 12,000,000 products, 9,400,000 real searches, and 26,000,000 user-product interactions. We study the characteristics of this dataset from various perspectives and evaluate representative personalization models to verify its feasibility. The dataset can be publicly accessed at Github: https://github.com/rucliujn/JDsearch.