 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Re-Ranking with Multimodal Fusion and Target-Oriented Auxiliary Tasks in E-Commerce Search
Aug 11, 2024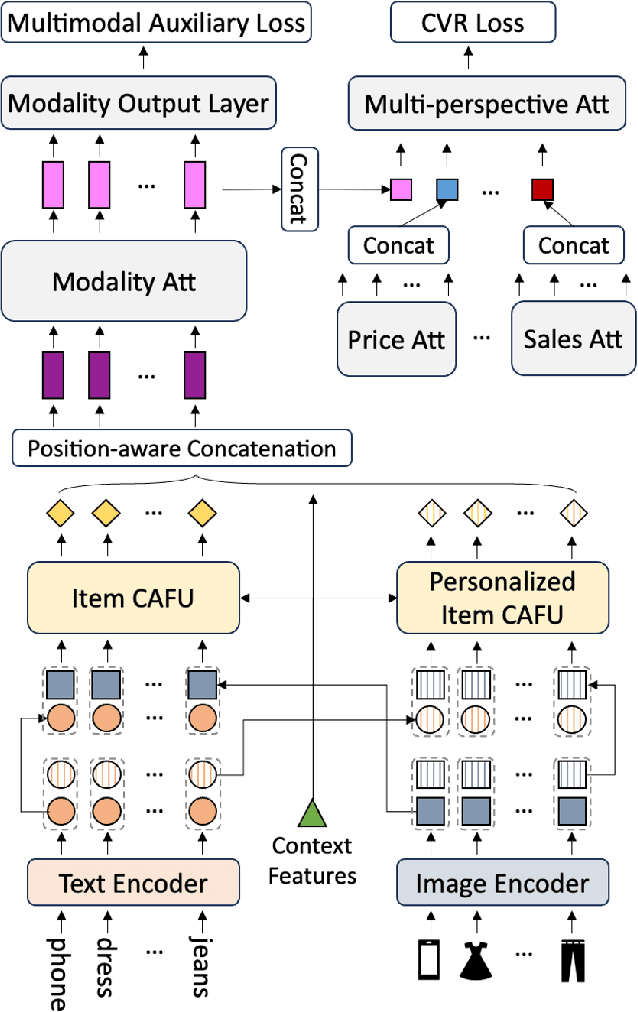
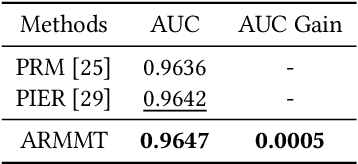

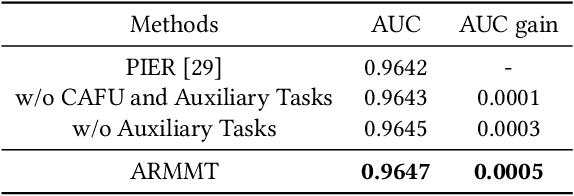
In the rapidly evolving field of e-commerce, the effectiveness of search re-ranking models is crucial for enhancing user experience and driving conversion rates. Despite significant advancements in feature representation and model architecture, the integration of multimodal information remains underexplored. This study addresses this gap by investigating the computation and fusion of textual and visual information in the context of re-ranking. We propose \textbf{A}dvancing \textbf{R}e-Ranking with \textbf{M}ulti\textbf{m}odal Fusion and \textbf{T}arget-Oriented Auxiliary Tasks (ARMMT), which integrates an attention-based multimodal fusion technique and an auxiliary ranking-aligned task to enhance item representation and improve targeting capabilities. This method not only enriches the understanding of product attributes but also enables more precise and personalized recommendations. Experimental evaluations on JD.com's search platform demonstrate that ARMMT achieves state-of-the-art performance in multimodal information integration, evidenced by a 0.22\% increase in the Conversion Rate (CVR), significantly contributing to Gross Merchandise Volume (GMV). This pioneering approach has the potential to revolutionize e-commerce re-ranking, leading to elevated user satisfaction and business growth.
Breaking the Hourglass Phenomenon of Residual Quantization: Enhancing the Upper Bound of Generative Retrieval
Jul 31, 2024



Generative retrieval (GR) has emerged as a transformative paradigm in search and recommender systems, leveraging numeric-based identifier representations to enhance efficiency and generalization. Notably, methods like TIGER employing Residual Quantization-based Semantic Identifiers (RQ-SID), have shown significant promise in e-commerce scenarios by effectively managing item IDs. However, a critical issue termed the "\textbf{Hourglass}" phenomenon, occurs in RQ-SID, where intermediate codebook tokens become overly concentrated, hindering the full utilization of generative retrieval methods. This paper analyses and addresses this problem by identifying data sparsity and long-tailed distribution as the primary causes. Through comprehensive experiments and detailed ablation studies, we analyze the impact of these factors on codebook utilization and data distribution. Our findings reveal that the "Hourglass" phenomenon substantially impacts the performance of RQ-SID in generative retrieval. We propose effective solutions to mitigate this issue, thereby significantly enhancing the effectiveness of generative retrieval in real-world E-commerce applications.
A Preference-oriented Diversity Model Based on Mutual-information in Re-ranking for E-commerce Search
May 24, 2024Re-ranking is a process of rearranging ranking list to more effectively meet user demands by accounting for the interrelationships between items. Existing methods predominantly enhance the precision of search results, often at the expense of diversity, leading to outcomes that may not fulfill the varied needs of users. Conversely, methods designed to promote diversity might compromise the precision of the results, failing to satisfy the users' requirements for accuracy. To alleviate the above problems, this paper proposes a Preference-oriented Diversity Model Based on Mutual-information (PODM-MI), which consider both accuracy and diversity in the re-ranking process. Specifically, PODM-MI adopts Multidimensional Gaussian distributions based on variational inference to capture users' diversity preferences with uncertainty. Then we maximize the mutual information between the diversity preferences of the users and the candidate items using the maximum variational inference lower bound to enhance their correlations. Subsequently, we derive a utility matrix based on the correlations, enabling the adaptive ranking of items in line with user preferences and establishing a balance between the aforementioned objectives. Experimental results on real-world online e-commerce systems demonstrate the significant improvements of PODM-MI, and we have successfully deployed PODM-MI on an e-commerce search platform.
Optimizing E-commerce Search: Toward a Generalizable and Rank-Consistent Pre-Ranking Model
May 09, 2024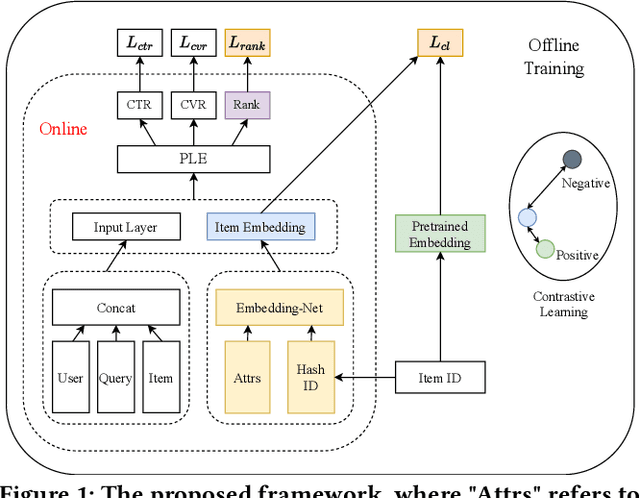

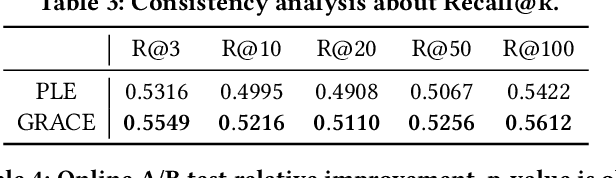
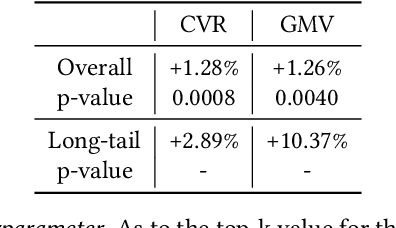
In large e-commerce platforms, search systems are typically composed of a series of modules, including recall, pre-ranking, and ranking phases. The pre-ranking phase, serving as a lightweight module, is crucial for filtering out the bulk of products in advance for the downstream ranking module. Industrial efforts on optimizing the pre-ranking model have predominantly focused on enhancing ranking consistency, model structure, and generalization towards long-tail items. Beyond these optimizations, meeting the system performance requirements presents a significant challenge. Contrasting with existing industry works, we propose a novel method: a Generalizable and RAnk-ConsistEnt Pre-Ranking Model (GRACE), which achieves: 1) Ranking consistency by introducing multiple binary classification tasks that predict whether a product is within the top-k results as estimated by the ranking model, which facilitates the addition of learning objectives on common point-wise ranking models; 2) Generalizability through contrastive learning of representation for all products by pre-training on a subset of ranking product embeddings; 3) Ease of implementation in feature construction and online deployment. Our extensive experiments demonstrate significant improvements in both offline metrics and online A/B test: a 0.75% increase in AUC and a 1.28% increase in CVR.
Sequential Search with Off-Policy Reinforcement Learning
Feb 01, 2022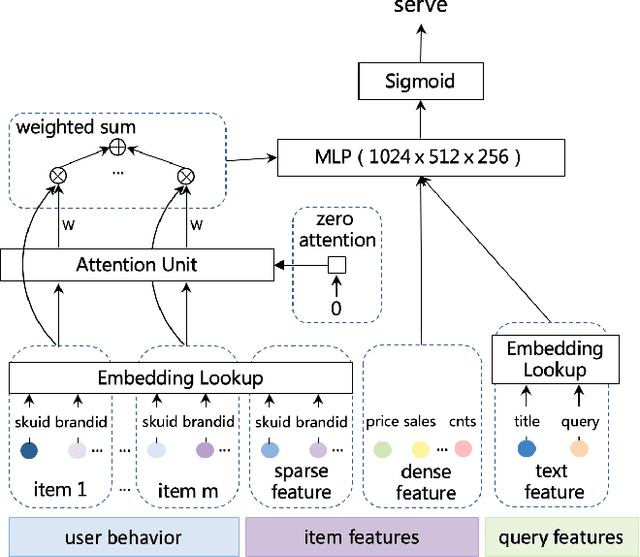
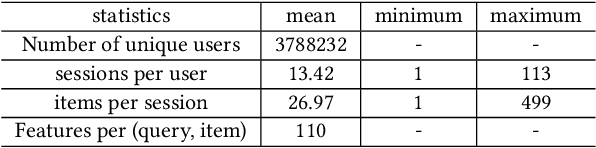
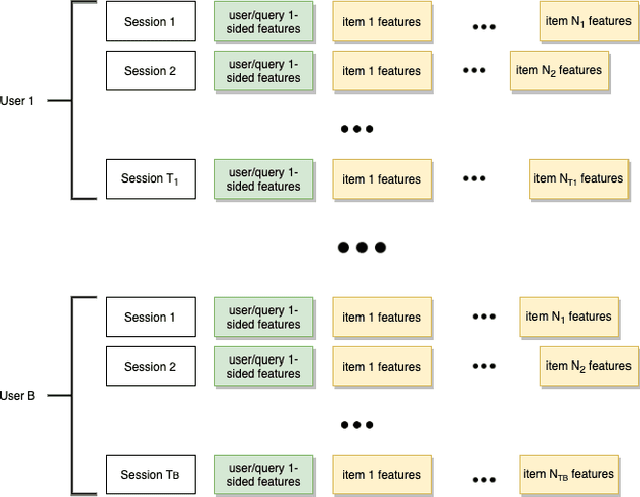
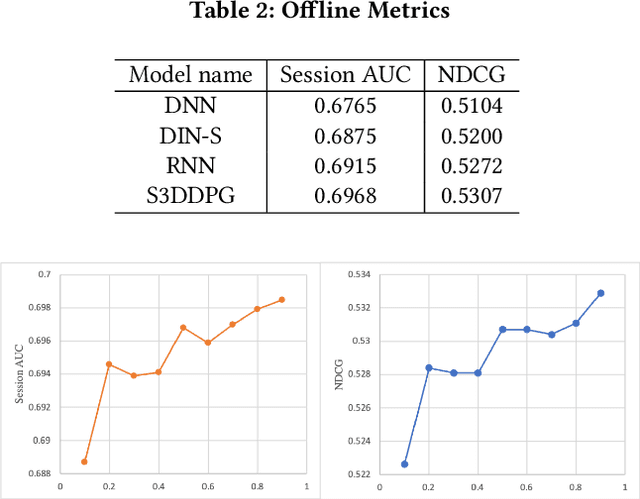
Recent years have seen a significant amount of interests in Sequential Recommendation (SR), which aims to understand and model the sequential user behaviors and the interactions between users and items over time. Surprisingly, despite the huge success Sequential Recommendation has achieved, there is little study on Sequential Search (SS), a twin learning task that takes into account a user's current and past search queries, in addition to behavior on historical query sessions. The SS learning task is even more important than the counterpart SR task for most of E-commence companies due to its much larger online serving demands as well as traffic volume. To this end, we propose a highly scalable hybrid learning model that consists of an RNN learning framework leveraging all features in short-term user-item interactions, and an attention model utilizing selected item-only features from long-term interactions. As a novel optimization step, we fit multiple short user sequences in a single RNN pass within a training batch, by solving a greedy knapsack problem on the fly. Moreover, we explore the use of off-policy reinforcement learning in multi-session personalized search ranking. Specifically, we design a pairwise Deep Deterministic Policy Gradient model that efficiently captures users' long term reward in terms of pairwise classification error. Extensive ablation experiments demonstrate significant improvement each component brings to its state-of-the-art baseline, on a variety of offline and online metrics.