 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Last Human-Written Paper: Agent-Native Research Artifacts
Apr 27, 2026Scientific publication compresses a branching, iterative research process into a linear narrative, discarding the majority of what was discovered along the way. This compilation imposes two structural costs: a Storytelling Tax, where failed experiments, rejected hypotheses, and the branching exploration process are discarded to fit a linear narrative; and an Engineering Tax, where the gap between reviewer-sufficient prose and agent-sufficient specification leaves critical implementation details unwritten. Tolerable for human readers, these costs become critical when AI agents must understand, reproduce, and extend published work. We introduce the Agent-Native Research Artifact (Ara), a protocol that replaces the narrative paper with a machine-executable research package structured around four layers: scientific logic, executable code with full specifications, an exploration graph that preserves the failures compilation discards, and evidence grounding every claim in raw outputs. Three mechanisms support the ecosystem: a Live Research Manager that captures decisions and dead ends during ordinary development; an Ara Compiler that translates legacy PDFs and repos into Aras; and an Ara-native review system that automates objective checks so human reviewers can focus on significance, novelty, and taste. On PaperBench and RE-Bench, Ara raises question-answering accuracy from 72.4% to 93.7% and reproduction success from 57.4% to 64.4%. On RE-Bench's five open-ended extension tasks, preserved failure traces in Ara accelerate progress, but can also constrain a capable agent from stepping outside the prior-run box depending on the agent's capabilities.
Towards Efficient and Generalizable Retrieval: Adaptive Semantic Quantization and Residual Knowledge Transfer
Feb 27, 2026While semantic ID-based generative retrieval enables efficient end-to-end modeling in industrial applications, these methods face a persistent trade-off: head items are susceptible to ID collisions that negatively impact downstream tasks, whereas data-sparse tail items, including cold-start items, exhibit limited generalization. To address this issue, we propose the Anchored Curriculum with Sequential Adaptive Quantization (SA^2CRQ) framework. The framework introduces Sequential Adaptive Residual Quantization (SARQ) to dynamically allocate code lengths based on item path entropy, assigning longer, discriminative IDs to head items and shorter, generalizable IDs to tail items. To mitigate data sparsity, the Anchored Curriculum Residual Quantization (ACRQ) component utilizes a frozen semantic manifold learned from head items to regularize and accelerate the representation learning of tail items. Experimental results from a large-scale industrial search system and multiple public datasets indicate that SA^2CRQ yields consistent improvements over existing baselines, particularly in cold-start retrieval scenarios.
RAD-DPO: Robust Adaptive Denoising Direct Preference Optimization for Generative Retrieval in E-commerce
Feb 27, 2026Generative Retrieval (GR) has emerged as a powerful paradigm in e-commerce search, retrieving items via autoregressive decoding of Semantic IDs (SIDs). However, aligning GR with complex user preferences remains challenging. While Direct Preference Optimization (DPO) offers an efficient alignment solution, its direct application to structured SIDs suffers from three limitations: (i) it penalizes shared hierarchical prefixes, causing gradient conflicts; (ii) it is vulnerable to noisy pseudo-negatives from implicit feedback; and (iii) in multi-label queries with multiple relevant items, it exacerbates a probability "squeezing effect" among valid candidates. To address these issues, we propose RAD-DPO, which introduces token-level gradient detachment to protect prefix structures, similarity-based dynamic reward weighting to mitigate label noise, and a multi-label global contrastive objective integrated with global SFT loss to explicitly expand positive coverage. Extensive offline experiments and online A/B testing on a large-scale e-commerce platform demonstrate significant improvements in ranking quality and training efficiency.
A Simple and Effective Framework for Symmetric Consistent Indexing in Large-Scale Dense Retrieval
Dec 15, 2025Dense retrieval has become the industry standard in large-scale information retrieval systems due to its high efficiency and competitive accuracy. Its core relies on a coarse-to-fine hierarchical architecture that enables rapid candidate selection and precise semantic matching, achieving millisecond-level response over billion-scale corpora. This capability makes it essential not only in traditional search and recommendation scenarios but also in the emerging paradigm of generative recommendation driven by large language models, where semantic IDs-themselves a form of coarse-to-fine representation-play a foundational role. However, the widely adopted dual-tower encoding architecture introduces inherent challenges, primarily representational space misalignment and retrieval index inconsistency, which degrade matching accuracy, retrieval stability, and performance on long-tail queries. These issues are further magnified in semantic ID generation, ultimately limiting the performance ceiling of downstream generative models. To address these challenges, this paper proposes a simple and effective framework named SCI comprising two synergistic modules: a symmetric representation alignment module that employs an innovative input-swapping mechanism to unify the dual-tower representation space without adding parameters, and an consistent indexing with dual-tower synergy module that redesigns retrieval paths using a dual-view indexing strategy to maintain consistency from training to inference. The framework is systematic, lightweight, and engineering-friendly, requiring minimal overhead while fully supporting billion-scale deployment. We provide theoretical guarantees for our approach, with its effectiveness validated by results across public datasets and real-world e-commerce datasets.
Cloud Infrastructure Management in the Age of AI Agents
Jun 13, 2025Cloud infrastructure is the cornerstone of the modern IT industry. However, managing this infrastructure effectively requires considerable manual effort from the DevOps engineering team. We make a case for developing AI agents powered by large language models (LLMs) to automate cloud infrastructure management tasks. In a preliminary study, we investigate the potential for AI agents to use different cloud/user interfaces such as software development kits (SDK), command line interfaces (CLI), Infrastructure-as-Code (IaC) platforms, and web portals. We report takeaways on their effectiveness on different management tasks, and identify research challenges and potential solutions.
EXP-Bench: Can AI Conduct AI Research Experiments?
May 30, 2025



Automating AI research holds immense potential for accelerating scientific progress, yet current AI agents struggle with the complexities of rigorous, end-to-end experimentation. We introduce EXP-Bench, a novel benchmark designed to systematically evaluate AI agents on complete research experiments sourced from influential AI publications. Given a research question and incomplete starter code, EXP-Bench challenges AI agents to formulate hypotheses, design and implement experimental procedures, execute them, and analyze results. To enable the creation of such intricate and authentic tasks with high-fidelity, we design a semi-autonomous pipeline to extract and structure crucial experimental details from these research papers and their associated open-source code. With the pipeline, EXP-Bench curated 461 AI research tasks from 51 top-tier AI research papers. Evaluations of leading LLM-based agents, such as OpenHands and IterativeAgent on EXP-Bench demonstrate partial capabilities: while scores on individual experimental aspects such as design or implementation correctness occasionally reach 20-35%, the success rate for complete, executable experiments was a mere 0.5%. By identifying these bottlenecks and providing realistic step-by-step experiment procedures, EXP-Bench serves as a vital tool for future AI agents to improve their ability to conduct AI research experiments. EXP-Bench is open-sourced at https://github.com/Just-Curieous/Curie/tree/main/benchmark/exp_bench.
Curie: Toward Rigorous and Automated Scientific Experimentation with AI Agents
Feb 26, 2025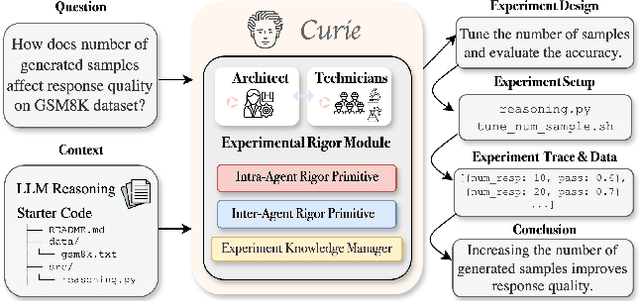
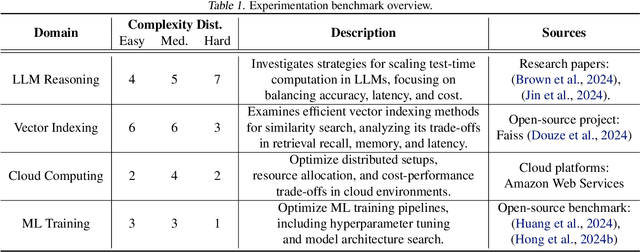
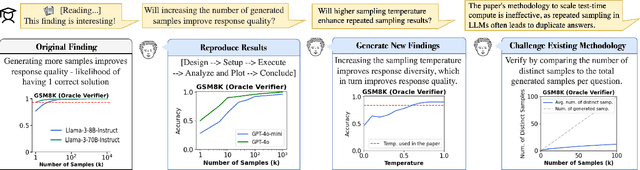
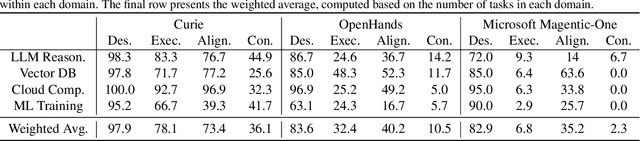
Scientific experimentation, a cornerstone of human progress, demands rigor in reliability, methodical control, and interpretability to yield meaningful results. Despite the growing capabilities of large language models (LLMs) in automating different aspects of the scientific process, automating rigorous experimentation remains a significant challenge. To address this gap, we propose Curie, an AI agent framework designed to embed rigor into the experimentation process through three key components: an intra-agent rigor module to enhance reliability, an inter-agent rigor module to maintain methodical control, and an experiment knowledge module to enhance interpretability. To evaluate Curie, we design a novel experimental benchmark composed of 46 questions across four computer science domains, derived from influential research papers, and widely adopted open-source projects. Compared to the strongest baseline tested, we achieve a 3.4$\times$ improvement in correctly answering experimental questions. Curie is open-sourced at https://github.com/Just-Curieous/Curie.
Generative Retrieval with Preference Optimization for E-commerce Search
Jul 29, 2024Generative retrieval introduces a groundbreaking paradigm to document retrieval by directly generating the identifier of a pertinent document in response to a specific query. This paradigm has demonstrated considerable benefits and potential, particularly in representation and generalization capabilities, within the context of large language models. However, it faces significant challenges in E-commerce search scenarios, including the complexity of generating detailed item titles from brief queries, the presence of noise in item titles with weak language order, issues with long-tail queries, and the interpretability of results. To address these challenges, we have developed an innovative framework for E-commerce search, called generative retrieval with preference optimization. This framework is designed to effectively learn and align an autoregressive model with target data, subsequently generating the final item through constraint-based beam search. By employing multi-span identifiers to represent raw item titles and transforming the task of generating titles from queries into the task of generating multi-span identifiers from queries, we aim to simplify the generation process. The framework further aligns with human preferences using click data and employs a constrained search method to identify key spans for retrieving the final item, thereby enhancing result interpretability. Our extensive experiments show that this framework achieves competitive performance on a real-world dataset, and online A/B tests demonstrate the superiority and effectiveness in improving conversion gains.
Optimizing E-commerce Search: Toward a Generalizable and Rank-Consistent Pre-Ranking Model
May 09, 2024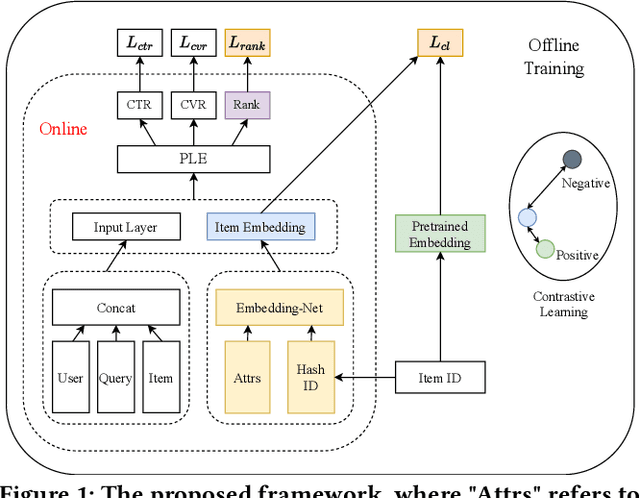

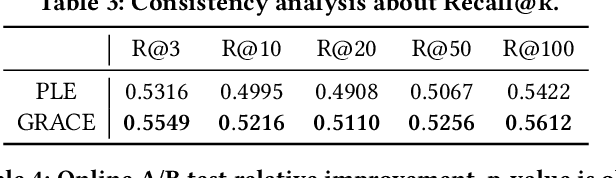
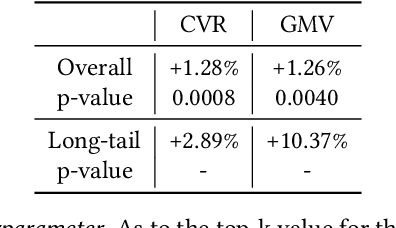
In large e-commerce platforms, search systems are typically composed of a series of modules, including recall, pre-ranking, and ranking phases. The pre-ranking phase, serving as a lightweight module, is crucial for filtering out the bulk of products in advance for the downstream ranking module. Industrial efforts on optimizing the pre-ranking model have predominantly focused on enhancing ranking consistency, model structure, and generalization towards long-tail items. Beyond these optimizations, meeting the system performance requirements presents a significant challenge. Contrasting with existing industry works, we propose a novel method: a Generalizable and RAnk-ConsistEnt Pre-Ranking Model (GRACE), which achieves: 1) Ranking consistency by introducing multiple binary classification tasks that predict whether a product is within the top-k results as estimated by the ranking model, which facilitates the addition of learning objectives on common point-wise ranking models; 2) Generalizability through contrastive learning of representation for all products by pre-training on a subset of ranking product embeddings; 3) Ease of implementation in feature construction and online deployment. Our extensive experiments demonstrate significant improvements in both offline metrics and online A/B test: a 0.75% increase in AUC and a 1.28% increase in CVR.
Differentiable Retrieval Augmentation via Generative Language Modeling for E-commerce Query Intent Classification
Aug 21, 2023Retrieval augmentation, which enhances downstream models by a knowledge retriever and an external corpus instead of by merely increasing the number of model parameters, has been successfully applied to many natural language processing (NLP) tasks such as text classification, question answering and so on. However, existing methods that separately or asynchronously train the retriever and downstream model mainly due to the non-differentiability between the two parts, usually lead to degraded performance compared to end-to-end joint training. In this paper, we propose Differentiable Retrieval Augmentation via Generative lANguage modeling(Dragan), to address this problem by a novel differentiable reformulation. We demonstrate the effectiveness of our proposed method on a challenging NLP task in e-commerce search, namely query intent classification. Both the experimental results and ablation study show that the proposed method significantly and reasonably improves the state-of-the-art baselines on both offline evaluation and online A/B test.