 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenRec: A Preference-Oriented Generative Framework for Large-Scale Recommendation
Apr 16, 2026Generative Retrieval (GR) offers a promising paradigm for recommendation through next-token prediction (NTP). However, scaling it to large-scale industrial systems introduces three challenges: (i) within a single request, the identical model inputs may produce inconsistent outputs due to the pagination request mechanism; (ii) the prohibitive cost of encoding long user behavior sequences with multi-token item representations based on semantic IDs, and (iii) aligning the generative policy with nuanced user preference signals. We present GenRec, a preference-oriented generative framework deployed on the JD App that addresses above challenges within a single decoder-only architecture. For training objective, we propose Page-wise NTP task, which supervises over an entire interaction page rather than each interacted item individually, providing denser gradient signal and resolving the one-to-many ambiguity of point-wise training. On the prefilling side, an asymmetric linear Token Merger compresses multi-token Semantic IDs in the prompt while preserving full-resolution decoding, reducing input length by ~2X with negligible accuracy loss. To further align outputs with user satisfaction, we introduce GRPO-SR, a reinforcement learning method that pairs Group Relative Policy Optimization with NLL regularization for training stability, and employs Hybrid Rewards combining a dense reward model with a relevance gate to mitigate reward hacking. In month-long online A/B tests serving production traffic, GenRec achieves 9.5% improvement in click count and 8.7% in transaction count over the existing pipeline.
RAD-DPO: Robust Adaptive Denoising Direct Preference Optimization for Generative Retrieval in E-commerce
Feb 27, 2026Generative Retrieval (GR) has emerged as a powerful paradigm in e-commerce search, retrieving items via autoregressive decoding of Semantic IDs (SIDs). However, aligning GR with complex user preferences remains challenging. While Direct Preference Optimization (DPO) offers an efficient alignment solution, its direct application to structured SIDs suffers from three limitations: (i) it penalizes shared hierarchical prefixes, causing gradient conflicts; (ii) it is vulnerable to noisy pseudo-negatives from implicit feedback; and (iii) in multi-label queries with multiple relevant items, it exacerbates a probability "squeezing effect" among valid candidates. To address these issues, we propose RAD-DPO, which introduces token-level gradient detachment to protect prefix structures, similarity-based dynamic reward weighting to mitigate label noise, and a multi-label global contrastive objective integrated with global SFT loss to explicitly expand positive coverage. Extensive offline experiments and online A/B testing on a large-scale e-commerce platform demonstrate significant improvements in ranking quality and training efficiency.
Towards Efficient and Generalizable Retrieval: Adaptive Semantic Quantization and Residual Knowledge Transfer
Feb 27, 2026While semantic ID-based generative retrieval enables efficient end-to-end modeling in industrial applications, these methods face a persistent trade-off: head items are susceptible to ID collisions that negatively impact downstream tasks, whereas data-sparse tail items, including cold-start items, exhibit limited generalization. To address this issue, we propose the Anchored Curriculum with Sequential Adaptive Quantization (SA^2CRQ) framework. The framework introduces Sequential Adaptive Residual Quantization (SARQ) to dynamically allocate code lengths based on item path entropy, assigning longer, discriminative IDs to head items and shorter, generalizable IDs to tail items. To mitigate data sparsity, the Anchored Curriculum Residual Quantization (ACRQ) component utilizes a frozen semantic manifold learned from head items to regularize and accelerate the representation learning of tail items. Experimental results from a large-scale industrial search system and multiple public datasets indicate that SA^2CRQ yields consistent improvements over existing baselines, particularly in cold-start retrieval scenarios.
Adversarial Alignment and Disentanglement for Cross-Domain CTR Prediction with Domain-Encompassing Features
Jan 24, 2026Cross-domain recommendation (CDR) has been increasingly explored to address data sparsity and cold-start issues. However, recent approaches typically disentangle domain-invariant features shared between source and target domains, as well as domain-specific features for each domain. However, they often rely solely on domain-invariant features combined with target domain-specific features, which can lead to suboptimal performance. To overcome the limitations, this paper presents the Adversarial Alignment and Disentanglement Cross-Domain Recommendation ($A^2DCDR$ ) model, an innovative approach designed to capture a comprehensive range of cross-domain information, including both domain-invariant and valuable non-aligned features. The $A^2DCDR$ model enhances cross-domain recommendation through three key components: refining MMD with adversarial training for better generalization, employing a feature disentangler and reconstruction mechanism for intra-domain disentanglement, and introducing a novel fused representation combining domain-invariant, non-aligned features with original contextual data. Experiments on real-world datasets and online A/B testing show that $A^2DCDR$ outperforms existing methods, confirming its effectiveness and practical applicability. The code is provided at https://github.com/youzi0925/A-2DCDR/tree/main.
A Simple and Effective Framework for Symmetric Consistent Indexing in Large-Scale Dense Retrieval
Dec 15, 2025Dense retrieval has become the industry standard in large-scale information retrieval systems due to its high efficiency and competitive accuracy. Its core relies on a coarse-to-fine hierarchical architecture that enables rapid candidate selection and precise semantic matching, achieving millisecond-level response over billion-scale corpora. This capability makes it essential not only in traditional search and recommendation scenarios but also in the emerging paradigm of generative recommendation driven by large language models, where semantic IDs-themselves a form of coarse-to-fine representation-play a foundational role. However, the widely adopted dual-tower encoding architecture introduces inherent challenges, primarily representational space misalignment and retrieval index inconsistency, which degrade matching accuracy, retrieval stability, and performance on long-tail queries. These issues are further magnified in semantic ID generation, ultimately limiting the performance ceiling of downstream generative models. To address these challenges, this paper proposes a simple and effective framework named SCI comprising two synergistic modules: a symmetric representation alignment module that employs an innovative input-swapping mechanism to unify the dual-tower representation space without adding parameters, and an consistent indexing with dual-tower synergy module that redesigns retrieval paths using a dual-view indexing strategy to maintain consistency from training to inference. The framework is systematic, lightweight, and engineering-friendly, requiring minimal overhead while fully supporting billion-scale deployment. We provide theoretical guarantees for our approach, with its effectiveness validated by results across public datasets and real-world e-commerce datasets.
LREF: A Novel LLM-based Relevance Framework for E-commerce
Mar 12, 2025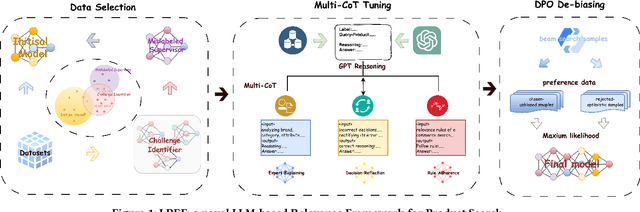
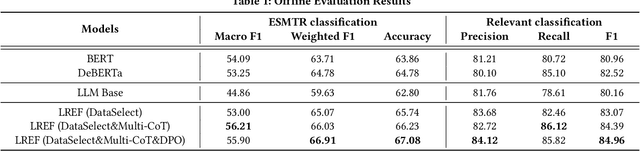


Query and product relevance prediction is a critical component for ensuring a smooth user experience in e-commerce search. Traditional studies mainly focus on BERT-based models to assess the semantic relevance between queries and products. However, the discriminative paradigm and limited knowledge capacity of these approaches restrict their ability to comprehend the relevance between queries and products fully. With the rapid advancement of Large Language Models (LLMs), recent research has begun to explore their application to industrial search systems, as LLMs provide extensive world knowledge and flexible optimization for reasoning processes. Nonetheless, directly leveraging LLMs for relevance prediction tasks introduces new challenges, including a high demand for data quality, the necessity for meticulous optimization of reasoning processes, and an optimistic bias that can result in over-recall. To overcome the above problems, this paper proposes a novel framework called the LLM-based RElevance Framework (LREF) aimed at enhancing e-commerce search relevance. The framework comprises three main stages: supervised fine-tuning (SFT) with Data Selection, Multiple Chain of Thought (Multi-CoT) tuning, and Direct Preference Optimization (DPO) for de-biasing. We evaluate the performance of the framework through a series of offline experiments on large-scale real-world datasets, as well as online A/B testing. The results indicate significant improvements in both offline and online metrics. Ultimately, the model was deployed in a well-known e-commerce application, yielding substantial commercial benefits.
Advancing Re-Ranking with Multimodal Fusion and Target-Oriented Auxiliary Tasks in E-Commerce Search
Aug 11, 2024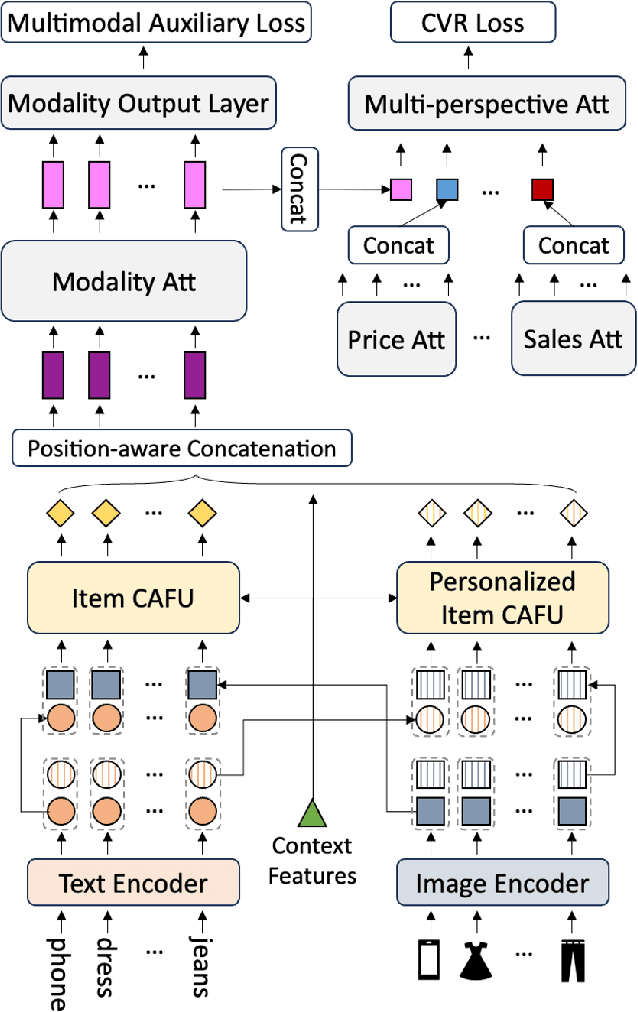
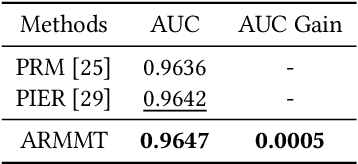

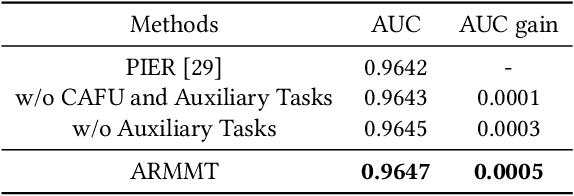
In the rapidly evolving field of e-commerce, the effectiveness of search re-ranking models is crucial for enhancing user experience and driving conversion rates. Despite significant advancements in feature representation and model architecture, the integration of multimodal information remains underexplored. This study addresses this gap by investigating the computation and fusion of textual and visual information in the context of re-ranking. We propose \textbf{A}dvancing \textbf{R}e-Ranking with \textbf{M}ulti\textbf{m}odal Fusion and \textbf{T}arget-Oriented Auxiliary Tasks (ARMMT), which integrates an attention-based multimodal fusion technique and an auxiliary ranking-aligned task to enhance item representation and improve targeting capabilities. This method not only enriches the understanding of product attributes but also enables more precise and personalized recommendations. Experimental evaluations on JD.com's search platform demonstrate that ARMMT achieves state-of-the-art performance in multimodal information integration, evidenced by a 0.22\% increase in the Conversion Rate (CVR), significantly contributing to Gross Merchandise Volume (GMV). This pioneering approach has the potential to revolutionize e-commerce re-ranking, leading to elevated user satisfaction and business growth.
MODRL-TA:A Multi-Objective Deep Reinforcement Learning Framework for Traffic Allocation in E-Commerce Search
Jul 22, 2024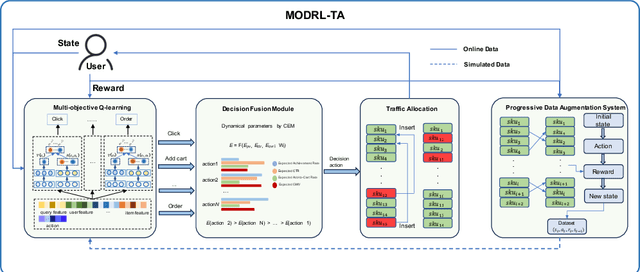
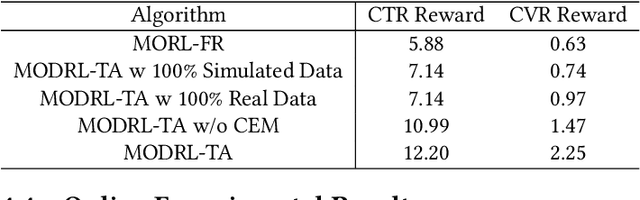
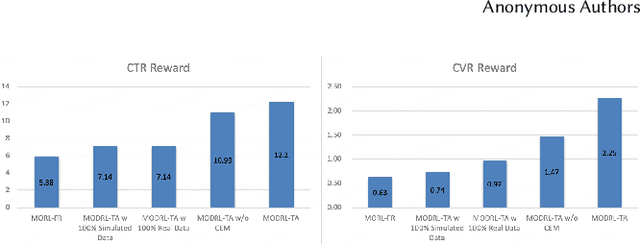
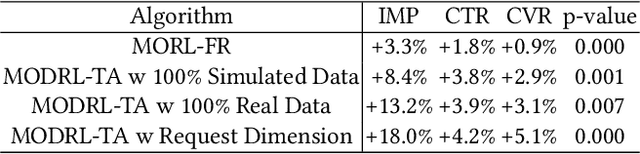
Traffic allocation is a process of redistributing natural traffic to products by adjusting their positions in the post-search phase, aimed at effectively fostering merchant growth, precisely meeting customer demands, and ensuring the maximization of interests across various parties within e-commerce platforms. Existing methods based on learning to rank neglect the long-term value of traffic allocation, whereas approaches of reinforcement learning suffer from balancing multiple objectives and the difficulties of cold starts within realworld data environments. To address the aforementioned issues, this paper propose a multi-objective deep reinforcement learning framework consisting of multi-objective Q-learning (MOQ), a decision fusion algorithm (DFM) based on the cross-entropy method(CEM), and a progressive data augmentation system(PDA). Specifically. MOQ constructs ensemble RL models, each dedicated to an objective, such as click-through rate, conversion rate, etc. These models individually determine the position of items as actions, aiming to estimate the long-term value of multiple objectives from an individual perspective. Then we employ DFM to dynamically adjust weights among objectives to maximize long-term value, addressing temporal dynamics in objective preferences in e-commerce scenarios. Initially, PDA trained MOQ with simulated data from offline logs. As experiments progressed, it strategically integrated real user interaction data, ultimately replacing the simulated dataset to alleviate distributional shifts and the cold start problem. Experimental results on real-world online e-commerce systems demonstrate the significant improvements of MODRL-TA, and we have successfully deployed MODRL-TA on an e-commerce search platform.
A Preference-oriented Diversity Model Based on Mutual-information in Re-ranking for E-commerce Search
May 24, 2024Re-ranking is a process of rearranging ranking list to more effectively meet user demands by accounting for the interrelationships between items. Existing methods predominantly enhance the precision of search results, often at the expense of diversity, leading to outcomes that may not fulfill the varied needs of users. Conversely, methods designed to promote diversity might compromise the precision of the results, failing to satisfy the users' requirements for accuracy. To alleviate the above problems, this paper proposes a Preference-oriented Diversity Model Based on Mutual-information (PODM-MI), which consider both accuracy and diversity in the re-ranking process. Specifically, PODM-MI adopts Multidimensional Gaussian distributions based on variational inference to capture users' diversity preferences with uncertainty. Then we maximize the mutual information between the diversity preferences of the users and the candidate items using the maximum variational inference lower bound to enhance their correlations. Subsequently, we derive a utility matrix based on the correlations, enabling the adaptive ranking of items in line with user preferences and establishing a balance between the aforementioned objectives. Experimental results on real-world online e-commerce systems demonstrate the significant improvements of PODM-MI, and we have successfully deployed PODM-MI on an e-commerce search platform.
A Unified Search and Recommendation Framework Based on Multi-Scenario Learning for Ranking in E-commerce
May 17, 2024


Search and recommendation (S&R) are the two most important scenarios in e-commerce. The majority of users typically interact with products in S&R scenarios, indicating the need and potential for joint modeling. Traditional multi-scenario models use shared parameters to learn the similarity of multiple tasks, and task-specific parameters to learn the divergence of individual tasks. This coarse-grained modeling approach does not effectively capture the differences between S&R scenarios. Furthermore, this approach does not sufficiently exploit the information across the global label space. These issues can result in the suboptimal performance of multi-scenario models in handling both S&R scenarios. To address these issues, we propose an effective and universal framework for Unified Search and Recommendation (USR), designed with S&R Views User Interest Extractor Layer (IE) and S&R Views Feature Generator Layer (FG) to separately generate user interests and scenario-agnostic feature representations for S&R. Next, we introduce a Global Label Space Multi-Task Layer (GLMT) that uses global labels as supervised signals of auxiliary tasks and jointly models the main task and auxiliary tasks using conditional probability. Extensive experimental evaluations on real-world industrial datasets show that USR can be applied to various multi-scenario models and significantly improve their performance. Online A/B testing also indicates substantial performance gains across multiple metrics. Currently, USR has been successfully deployed in the 7Fresh App.