 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Static Best-of-N: Bayesian List-wise Alignment for LLM-based Recommendation
May 06, 2026Large Language Models have revolutionized recommender systems (LLM4Rec) by leveraging their generative capabilities to model complex user preferences. However, existing LLM4Rec methods primarily rely on token-level objectives, making it difficult to optimize list-level and non-differentiable metrics (e.g., NDCG, fairness) that define actual recommendation quality. While Best-of-N (BoN) directly optimizes these metrics during inference, its high computational cost hinders real-world deployment. To address this, BoN Alignment aims to distill the search capability into the model itself, yet current approaches suffer from two critical limitations: (1) Indiscriminate Supervision, where the static reference fails to distinguish the relative quality of candidates exceeding its empirical range, leading to a loss of ranking guidance; and (2) Gradient Decay, where the effective supervision signal rapidly diminishes as the evolving policy improves, resulting in inefficient optimization. To overcome these challenges, we propose BLADE (Bayesian List-wise Alignment via Dynamic Estimation). Unlike static approaches, BLADE introduces a Bayesian framework that continuously updates the target distribution by fusing historical priors with dynamic evidence from the model's current rollouts. This mechanism constructs a self-evolving target that adapts to the model's growing capabilities, ensuring the training signal remains informative throughout the learning process. Extensive experiments on three real-world datasets demonstrate that BLADE significantly outperforms state-of-the-art baselines. Crucially, it breaks the static performance upper bound, achieving sustained gains in both ranking accuracy (Recall, NDCG) and complex list-wise metrics (Fairness, Diversity). The code is available via https://github.com/RegionCh/BLADE.
Sequence-aware Large Language Models for Explainable Recommendation
Mar 25, 2026Large Language Models (LLMs) have shown strong potential in generating natural language explanations for recommender systems. However, existing methods often overlook the sequential dynamics of user behavior and rely on evaluation metrics misaligned with practical utility. We propose SELLER (SEquence-aware LLM-based framework for Explainable Recommendation), which integrates explanation generation with utility-aware evaluation. SELLER combines a dual-path encoder-capturing both user behavior and item semantics with a Mixture-of-Experts adapter to align these signals with LLMs. A unified evaluation framework assesses explanations via both textual quality and their effect on recommendation outcomes. Experiments on public benchmarks show that SELLER consistently outperforms prior methods in explanation quality and real-world utility.
Breaking User-Centric Agency: A Tri-Party Framework for Agent-Based Recommendation
Mar 11, 2026Recent advances in large language models (LLMs) have stimulated growing interest in agent-based recommender systems, enabling language-driven interaction and reasoning for more expressive preference modeling. However, most existing agentic approaches remain predominantly user-centric, treating items as passive entities and neglecting the interests of other critical stakeholders. This limitation exacerbates exposure concentration and long-tail under-representation, threatening long-term system sustainability. In this work, we identify this fundamental limitation and propose the first Tri-party LLM-agent Recommendation framework (TriRec) that explicitly coordinates user utility, item exposure, and platform-level fairness. The framework employs a two-stage architecture: Stage~1 empowers item agents with personalized self-promotion to improve matching quality and alleviate cold-start barriers, while Stage~2 uses a platform agent for sequential multi-objective re-ranking, balancing user relevance, item utility, and exposure fairness. Experiments on multiple benchmarks show consistent gains in accuracy, fairness, and item-level utility. Moreover, we find that item self-promotion can simultaneously enhance fairness and effectiveness, challenging the conventional trade-off assumption between relevance and fairness. Our code is available at https://github.com/Marfekey/TriRec.
Uncertainty-aware Generative Recommendation
Feb 12, 2026Generative Recommendation has emerged as a transformative paradigm, reformulating recommendation as an end-to-end autoregressive sequence generation task. Despite its promise, existing preference optimization methods typically rely on binary outcome correctness, suffering from a systemic limitation we term uncertainty blindness. This issue manifests in the neglect of the model's intrinsic generation confidence, the variation in sample learning difficulty, and the lack of explicit confidence expression, directly leading to unstable training dynamics and unquantifiable decision risks. In this paper, we propose Uncertainty-aware Generative Recommendation (UGR), a unified framework that leverages uncertainty as a critical signal for adaptive optimization. UGR synergizes three mechanisms: (1) an uncertainty-weighted reward to penalize confident errors; (2) difficulty-aware optimization dynamics to prevent premature convergence; and (3) explicit confidence alignment to empower the model with confidence expression capabilities. Extensive experiments demonstrate that UGR not only yields superior recommendation performance but also fundamentally stabilizes training, preventing the performance degradation often observed in standard methods. Furthermore, the learned confidence enables reliable downstream risk-aware applications.
Don't Start Over: A Cost-Effective Framework for Migrating Personalized Prompts Between LLMs
Jan 17, 2026Personalization in Large Language Models (LLMs) often relies on user-specific soft prompts. However, these prompts become obsolete when the foundation model is upgraded, necessitating costly, full-scale retraining. To overcome this limitation, we propose the Prompt-level User Migration Adapter (PUMA), a lightweight framework to efficiently migrate personalized prompts across incompatible models. PUMA utilizes a parameter-efficient adapter to bridge the semantic gap, combined with a group-based user selection strategy to significantly reduce training costs. Experiments on three large-scale datasets show our method matches or even surpasses the performance of retraining from scratch, reducing computational cost by up to 98%. The framework demonstrates strong generalization across diverse model architectures and robustness in advanced scenarios like chained and aggregated migrations, offering a practical path for the sustainable evolution of personalized AI by decoupling user assets from the underlying models.
MindRec: A Diffusion-driven Coarse-to-Fine Paradigm for Generative Recommendation
Nov 18, 2025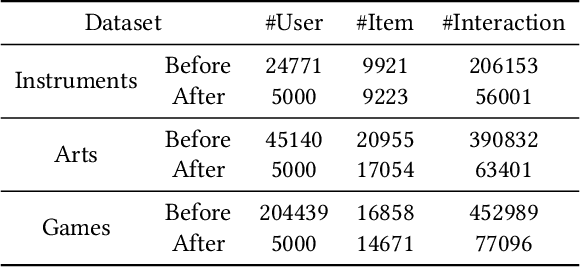
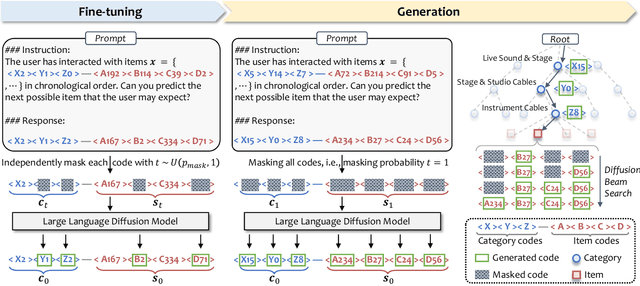
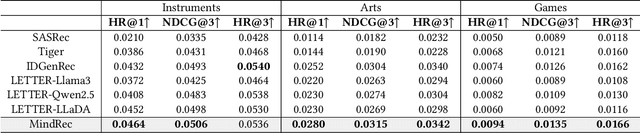
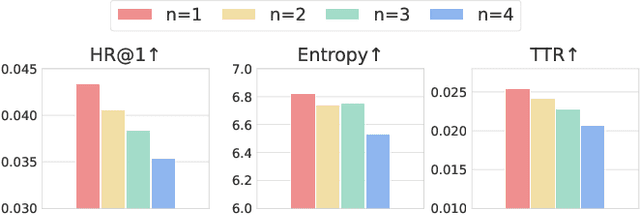
Recent advancements in large language model-based recommendation systems often represent items as text or semantic IDs and generate recommendations in an auto-regressive manner. However, due to the left-to-right greedy decoding strategy and the unidirectional logical flow, such methods often fail to produce globally optimal recommendations. In contrast, human reasoning does not follow a rigid left-to-right sequence. Instead, it often begins with keywords or intuitive insights, which are then refined and expanded. Inspired by this fact, we propose MindRec, a diffusion-driven coarse-to-fine generative paradigm that emulates human thought processes. Built upon a diffusion language model, MindRec departs from auto-regressive generation by leveraging a masked diffusion process to reconstruct items in a flexible, non-sequential manner. Particularly, our method first generates key tokens that reflect user preferences, and then expands them into the complete item, enabling adaptive and human-like generation. To further emulate the structured nature of human decision-making, we organize items into a hierarchical category tree. This structure guides the model to first produce the coarse-grained category and then progressively refine its selection through finer-grained subcategories before generating the specific item. To mitigate the local optimum problem inherent in greedy decoding, we design a novel beam search algorithm, Diffusion Beam Search, tailored for our mind-inspired generation paradigm. Experimental results demonstrate that MindRec yields a 9.5\% average improvement in top-1 accuracy over state-of-the-art methods, highlighting its potential to enhance recommendation performance. The implementation is available via https://github.com/Mr-Peach0301/MindRec.
MGFRec: Towards Reinforced Reasoning Recommendation with Multiple Groundings and Feedback
Oct 27, 2025



The powerful reasoning and generative capabilities of large language models (LLMs) have inspired researchers to apply them to reasoning-based recommendation tasks, which require in-depth reasoning about user interests and the generation of recommended items. However, previous reasoning-based recommendation methods have typically performed inference within the language space alone, without incorporating the actual item space. This has led to over-interpreting user interests and deviating from real items. Towards this research gap, we propose performing multiple rounds of grounding during inference to help the LLM better understand the actual item space, which could ensure that its reasoning remains aligned with real items. Furthermore, we introduce a user agent that provides feedback during each grounding step, enabling the LLM to better recognize and adapt to user interests. Comprehensive experiments conducted on three Amazon review datasets demonstrate the effectiveness of incorporating multiple groundings and feedback. These findings underscore the critical importance of reasoning within the actual item space, rather than being confined to the language space, for recommendation tasks.
Navigating Through Paper Flood: Advancing LLM-based Paper Evaluation through Domain-Aware Retrieval and Latent Reasoning
Aug 07, 2025With the rapid and continuous increase in academic publications, identifying high-quality research has become an increasingly pressing challenge. While recent methods leveraging Large Language Models (LLMs) for automated paper evaluation have shown great promise, they are often constrained by outdated domain knowledge and limited reasoning capabilities. In this work, we present PaperEval, a novel LLM-based framework for automated paper evaluation that addresses these limitations through two key components: 1) a domain-aware paper retrieval module that retrieves relevant concurrent work to support contextualized assessments of novelty and contributions, and 2) a latent reasoning mechanism that enables deep understanding of complex motivations and methodologies, along with comprehensive comparison against concurrently related work, to support more accurate and reliable evaluation. To guide the reasoning process, we introduce a progressive ranking optimization strategy that encourages the LLM to iteratively refine its predictions with an emphasis on relative comparison. Experiments on two datasets demonstrate that PaperEval consistently outperforms existing methods in both academic impact and paper quality evaluation. In addition, we deploy PaperEval in a real-world paper recommendation system for filtering high-quality papers, which has gained strong engagement on social media -- amassing over 8,000 subscribers and attracting over 10,000 views for many filtered high-quality papers -- demonstrating the practical effectiveness of PaperEval.
Fine-grained List-wise Alignment for Generative Medication Recommendation
May 26, 2025Accurate and safe medication recommendations are critical for effective clinical decision-making, especially in multimorbidity cases. However, existing systems rely on point-wise prediction paradigms that overlook synergistic drug effects and potential adverse drug-drug interactions (DDIs). We propose FLAME, a fine-grained list-wise alignment framework for large language models (LLMs), enabling drug-by-drug generation of drug lists. FLAME formulates recommendation as a sequential decision process, where each step adds or removes a single drug. To provide fine-grained learning signals, we devise step-wise Group Relative Policy Optimization (GRPO) with potential-based reward shaping, which explicitly models DDIs and optimizes the contribution of each drug to the overall prescription. Furthermore, FLAME enhances patient modeling by integrating structured clinical knowledge and collaborative information into the representation space of LLMs. Experiments on benchmark datasets demonstrate that FLAME achieves state-of-the-art performance, delivering superior accuracy, controllable safety-accuracy trade-offs, and strong generalization across diverse clinical scenarios. Our code is available at https://github.com/cxfann/Flame.
Process-Supervised LLM Recommenders via Flow-guided Tuning
Mar 10, 2025While large language models (LLMs) are increasingly adapted for recommendation systems via supervised fine-tuning (SFT), this approach amplifies popularity bias due to its likelihood maximization objective, compromising recommendation diversity and fairness. To address this, we present Flow-guided fine-tuning recommender (Flower), which replaces SFT with a Generative Flow Network (GFlowNet) framework that enacts process supervision through token-level reward propagation. Flower's key innovation lies in decomposing item-level rewards into constituent token rewards, enabling direct alignment between token generation probabilities and their reward signals. This mechanism achieves three critical advancements: (1) popularity bias mitigation and fairness enhancement through empirical distribution matching, (2) preservation of diversity through GFlowNet's proportional sampling, and (3) flexible integration of personalized preferences via adaptable token rewards. Experiments demonstrate Flower's superior distribution-fitting capability and its significant advantages over traditional SFT in terms of fairness, diversity, and accuracy, highlighting its potential to improve LLM-based recommendation systems. The implementation is available via https://github.com/Mr-Peach0301/Flower