 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoising-Enhanced YOLO for Robust SAR Ship Detection
Feb 27, 2026With the rapid advancement of deep learning, synthetic aperture radar (SAR) imagery has become a key modality for ship detection. However, robust performance remains challenging in complex scenes, where clutter and speckle noise can induce false alarms and small targets are easily missed. To address these issues, we propose CPN-YOLO, a high-precision ship detection framework built upon YOLOv8 with three targeted improvements. First, we introduce a learnable large-kernel denoising module for input pre-processing, producing cleaner representations and more discriminative features across diverse ship types. Second, we design a feature extraction enhancement strategy based on the PPA attention mechanism to strengthen multi-scale modeling and improve sensitivity to small ships. Third, we incorporate a Gaussian similarity loss derived from the normalized Wasserstein distance (NWD) to better measure similarity under complex bounding-box distributions and improve generalization. Extensive experiments on HRSID and SSDD demonstrate the effectiveness of our method. On SSDD, CPN-YOLO surpasses the YOLOv8 baseline, achieving 97.0% precision, 95.1% recall, and 98.9% mAP, and consistently outperforms other representative deep-learning detectors in overall performance.
MindRec: A Diffusion-driven Coarse-to-Fine Paradigm for Generative Recommendation
Nov 18, 2025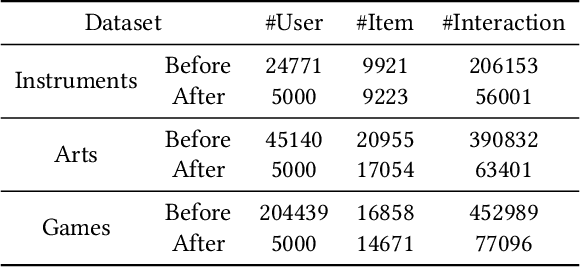
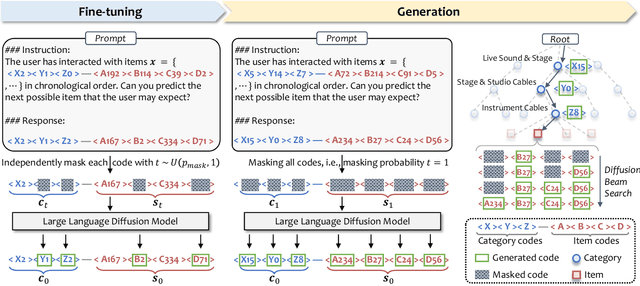
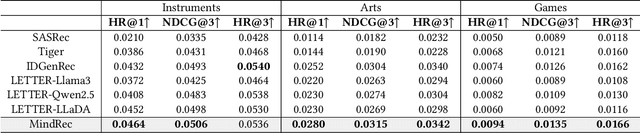
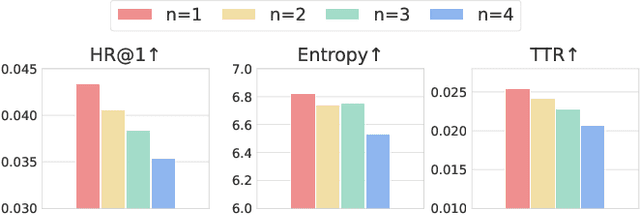
Recent advancements in large language model-based recommendation systems often represent items as text or semantic IDs and generate recommendations in an auto-regressive manner. However, due to the left-to-right greedy decoding strategy and the unidirectional logical flow, such methods often fail to produce globally optimal recommendations. In contrast, human reasoning does not follow a rigid left-to-right sequence. Instead, it often begins with keywords or intuitive insights, which are then refined and expanded. Inspired by this fact, we propose MindRec, a diffusion-driven coarse-to-fine generative paradigm that emulates human thought processes. Built upon a diffusion language model, MindRec departs from auto-regressive generation by leveraging a masked diffusion process to reconstruct items in a flexible, non-sequential manner. Particularly, our method first generates key tokens that reflect user preferences, and then expands them into the complete item, enabling adaptive and human-like generation. To further emulate the structured nature of human decision-making, we organize items into a hierarchical category tree. This structure guides the model to first produce the coarse-grained category and then progressively refine its selection through finer-grained subcategories before generating the specific item. To mitigate the local optimum problem inherent in greedy decoding, we design a novel beam search algorithm, Diffusion Beam Search, tailored for our mind-inspired generation paradigm. Experimental results demonstrate that MindRec yields a 9.5\% average improvement in top-1 accuracy over state-of-the-art methods, highlighting its potential to enhance recommendation performance. The implementation is available via https://github.com/Mr-Peach0301/MindRec.
Position-aware Graph Transformer for Recommendation
Dec 25, 2024Collaborative recommendation fundamentally involves learning high-quality user and item representations from interaction data. Recently, graph convolution networks (GCNs) have advanced the field by utilizing high-order connectivity patterns in interaction graphs, as evidenced by state-of-the-art methods like PinSage and LightGCN. However, one key limitation has not been well addressed in existing solutions: capturing long-range collaborative filtering signals, which are crucial for modeling user preference. In this work, we propose a new graph transformer (GT) framework -- \textit{Position-aware Graph Transformer for Recommendation} (PGTR), which combines the global modeling capability of Transformer blocks with the local neighborhood feature extraction of GCNs. The key insight is to explicitly incorporate node position and structure information from the user-item interaction graph into GT architecture via several purpose-designed positional encodings. The long-range collaborative signals from the Transformer block are then combined linearly with the local neighborhood features from the GCN backbone to enhance node embeddings for final recommendations. Empirical studies demonstrate the effectiveness of the proposed PGTR method when implemented on various GCN-based backbones across four real-world datasets, and the robustness against interaction sparsity as well as noise.
How Graph Convolutions Amplify Popularity Bias for Recommendation?
May 24, 2023Graph convolutional networks (GCNs) have become prevalent in recommender system (RS) due to their superiority in modeling collaborative patterns. Although improving the overall accuracy, GCNs unfortunately amplify popularity bias -- tail items are less likely to be recommended. This effect prevents the GCN-based RS from making precise and fair recommendations, decreasing the effectiveness of recommender systems in the long run. In this paper, we investigate how graph convolutions amplify the popularity bias in RS. Through theoretical analyses, we identify two fundamental factors: (1) with graph convolution (\textit{i.e.,} neighborhood aggregation), popular items exert larger influence than tail items on neighbor users, making the users move towards popular items in the representation space; (2) after multiple times of graph convolution, popular items would affect more high-order neighbors and become more influential. The two points make popular items get closer to almost users and thus being recommended more frequently. To rectify this, we propose to estimate the amplified effect of popular nodes on each node's representation, and intervene the effect after each graph convolution. Specifically, we adopt clustering to discover highly-influential nodes and estimate the amplification effect of each node, then remove the effect from the node embeddings at each graph convolution layer. Our method is simple and generic -- it can be used in the inference stage to correct existing models rather than training a new model from scratch, and can be applied to various GCN models. We demonstrate our method on two representative GCN backbones LightGCN and UltraGCN, verifying its ability in improving the recommendations of tail items without sacrificing the performance of popular items. Codes are open-sourced \footnote{https://github.com/MEICRS/DAP}.
GDSRec: Graph-Based Decentralized Collaborative Filtering for Social Recommendation
May 20, 2022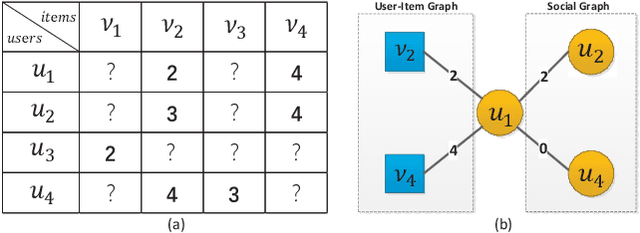
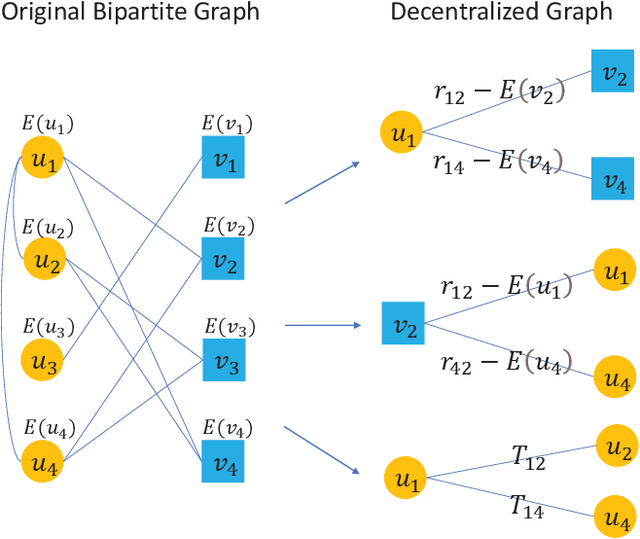
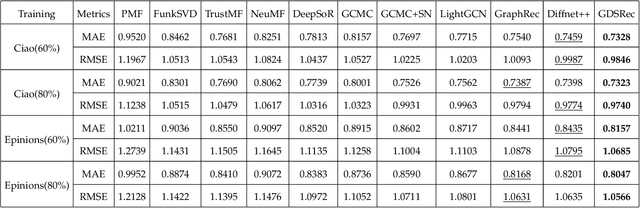
Generating recommendations based on user-item interactions and user-user social relations is a common use case in web-based systems. These connections can be naturally represented as graph-structured data and thus utilizing graph neural networks (GNNs) for social recommendation has become a promising research direction. However, existing graph-based methods fails to consider the bias offsets of users (items). For example, a low rating from a fastidious user may not imply a negative attitude toward this item because the user tends to assign low ratings in common cases. Such statistics should be considered into the graph modeling procedure. While some past work considers the biases, we argue that these proposed methods only treat them as scalars and can not capture the complete bias information hidden in data. Besides, social connections between users should also be differentiable so that users with similar item preference would have more influence on each other. To this end, we propose Graph-Based Decentralized Collaborative Filtering for Social Recommendation (GDSRec). GDSRec treats the biases as vectors and fuses them into the process of learning user and item representations. The statistical bias offsets are captured by decentralized neighborhood aggregation while the social connection strength is defined according to the preference similarity and then incorporated into the model design. We conduct extensive experiments on two benchmark datasets to verify the effectiveness of the proposed model. Experimental results show that the proposed GDSRec achieves superior performance compared with state-of-the-art related baselines. Our implementations are available in \url{https://github.com/MEICRS/GDSRec}.
Intelligent Online Selling Point Extraction for E-Commerce Recommendation
Dec 16, 2021


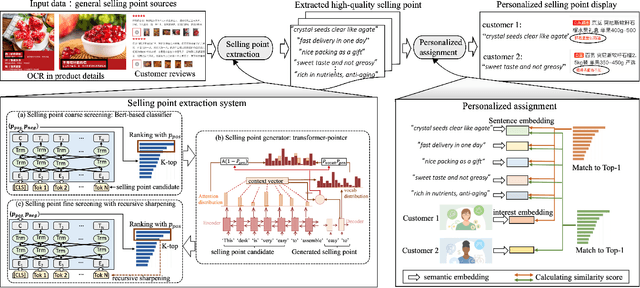
In the past decade, automatic product description generation for e-commerce have witnessed significant advancement. As the services provided by e-commerce platforms become diverse, it is necessary to dynamically adapt the patterns of descriptions generated. The selling point of products is an important type of product description for which the length should be as short as possible while still conveying key information. In addition, this kind of product description should be eye-catching to the readers. Currently, product selling points are normally written by human experts. Thus, the creation and maintenance of these contents incur high costs. These costs can be significantly reduced if product selling points can be automatically generated by machines. In this paper, we report our experience developing and deploying the Intelligent Online Selling Point Extraction (IOSPE) system to serve the recommendation system in the JD.com e-commerce platform. Since July 2020, IOSPE has become a core service for 62 key categories of products (covering more than 4 million products). So far, it has generated more than 0.1 billion selling points, thereby significantly scaling up the selling point creation operation and saving human labour. These IOSPE generated selling points have increased the click-through rate (CTR) by 1.89\% and the average duration the customers spent on the products by more than 2.03\% compared to the previous practice, which are significant improvements for such a large-scale e-commerce platform.
Automatic Product Copywriting for E-Commerce
Dec 15, 2021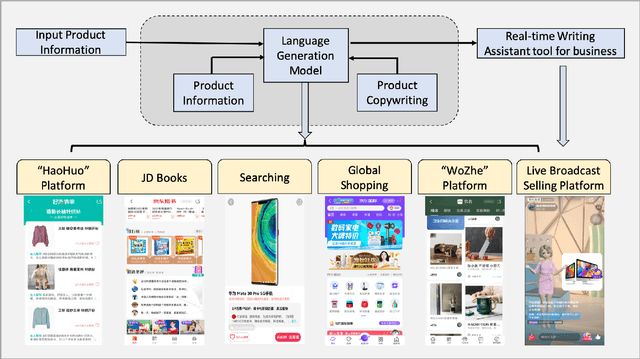

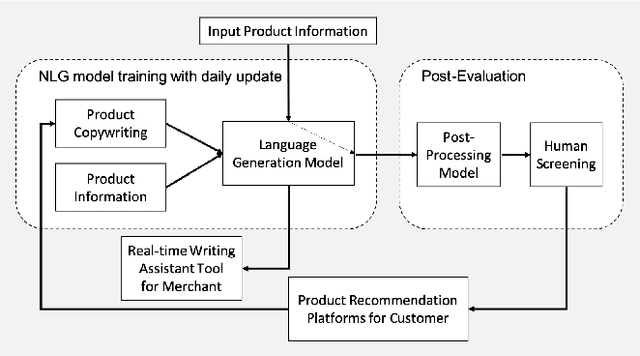
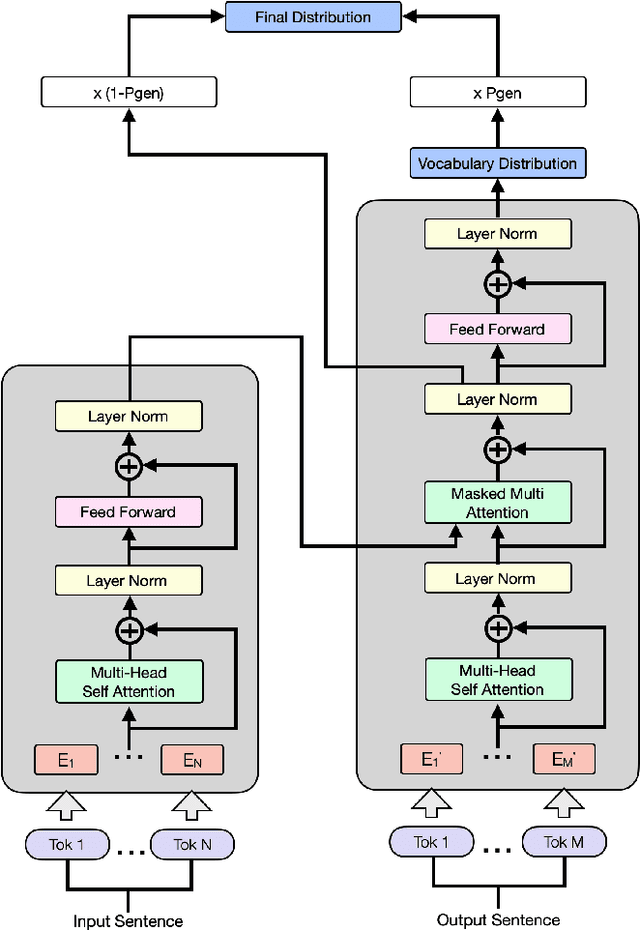
Product copywriting is a critical component of e-commerce recommendation platforms. It aims to attract users' interest and improve user experience by highlighting product characteristics with textual descriptions. In this paper, we report our experience deploying the proposed Automatic Product Copywriting Generation (APCG) system into the JD.com e-commerce product recommendation platform. It consists of two main components: 1) natural language generation, which is built from a transformer-pointer network and a pre-trained sequence-to-sequence model based on millions of training data from our in-house platform; and 2) copywriting quality control, which is based on both automatic evaluation and human screening. For selected domains, the models are trained and updated daily with the updated training data. In addition, the model is also used as a real-time writing assistant tool on our live broadcast platform. The APCG system has been deployed in JD.com since Feb 2021. By Sep 2021, it has generated 2.53 million product descriptions, and improved the overall averaged click-through rate (CTR) and the Conversion Rate (CVR) by 4.22% and 3.61%, compared to baselines, respectively on a year-on-year basis. The accumulated Gross Merchandise Volume (GMV) made by our system is improved by 213.42%, compared to the number in Feb 2021.
Bandwidth Slicing to Boost Federated Learning in Edge Computing
Oct 24, 2019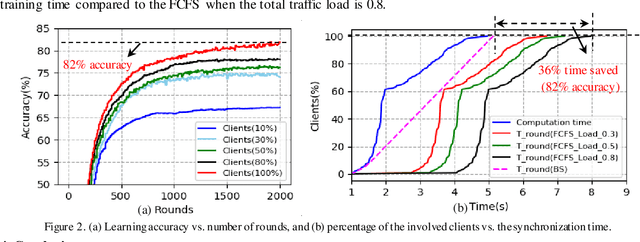
Bandwidth slicing is introduced to support federated learning in edge computing to assure low communication delay for training traffic. Results reveal that bandwidth slicing significantly improves training efficiency while achieving good learning accuracy.
Indoor Sound Source Localization with Probabilistic Neural Network
Dec 21, 2017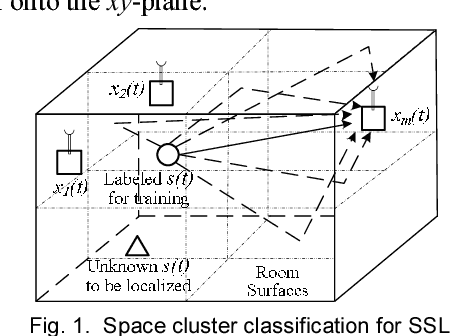
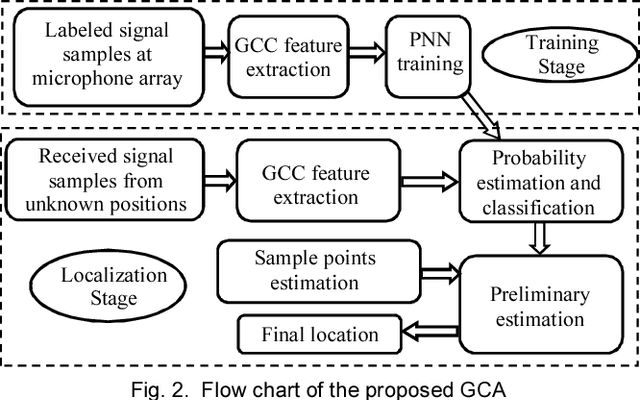
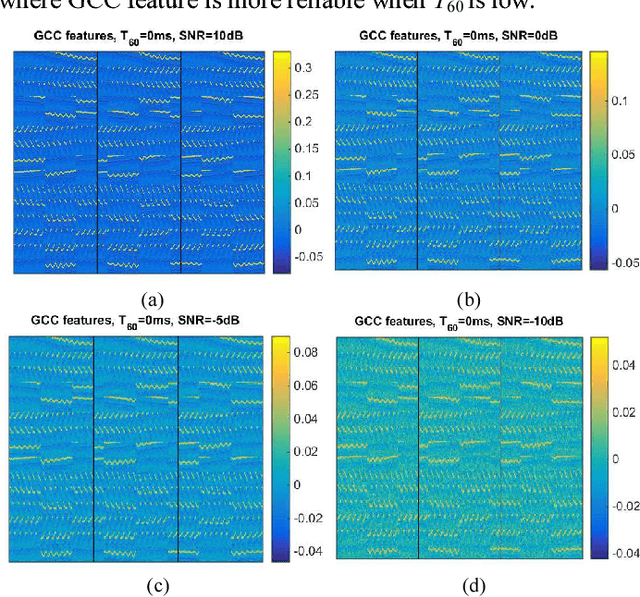
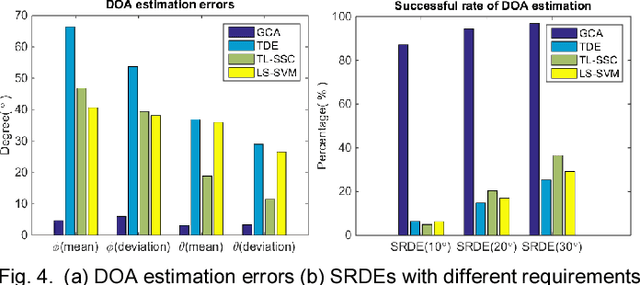
It is known that adverse environments such as high reverberation and low signal-to-noise ratio (SNR) pose a great challenge to indoor sound source localization. To address this challenge, in this paper, we propose a sound source localization algorithm based on probabilistic neural network, namely Generalized cross correlation Classification Algorithm (GCA). Experimental results for adverse environments with high reverberation time T60 up to 600ms and low SNR such as -10dB show that, the average azimuth angle error and elevation angle error by GCA are only 4.6 degrees and 3.1 degrees respectively. Compared with three recently published algorithms, GCA has increased the success rate on direction of arrival estimation significantly with good robustness to environmental changes. These results show that the proposed GCA can localize accurately and robustly for diverse indoor applications where the site acoustic features can be studied prior to the localization stage.