 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHopChain: Multi-Hop Data Synthesis for Generalizable Vision-Language Reasoning
Mar 19, 2026Vision-language models (VLMs) show strong multimodal capabilities but still struggle with fine-grained vision-language reasoning. We find that long chain-of-thought (CoT) reasoning exposes diverse failure modes, including perception, reasoning, knowledge, and hallucination errors, which can compound across intermediate steps. However, most existing vision-language data used for reinforcement learning with verifiable rewards (RLVR) does not involve complex reasoning chains that rely on visual evidence throughout, leaving these weaknesses largely unexposed. We therefore propose HopChain, a scalable framework for synthesizing multi-hop vision-language reasoning data for RLVR training of VLMs. Each synthesized multi-hop query forms a logically dependent chain of instance-grounded hops, where earlier hops establish the instances, sets, or conditions needed for later hops, while the final answer remains a specific, unambiguous number suitable for verifiable rewards. We train Qwen3.5-35B-A3B and Qwen3.5-397B-A17B under two RLVR settings: the original data alone, and the original data plus HopChain's multi-hop data, and compare them across 24 benchmarks spanning STEM and Puzzle, General VQA, Text Recognition and Document Understanding, and Video Understanding. Although this multi-hop data is not synthesized for any specific benchmark, it improves 20 of 24 benchmarks on both models, indicating broad and generalizable gains. Consistently, replacing full chained queries with half-multi-hop or single-hop variants reduces the average score across five representative benchmarks from 70.4 to 66.7 and 64.3, respectively. Notably, multi-hop gains peak in long-CoT vision-language reasoning, exceeding 50 points in the ultra-long-CoT regime. These experiments establish HopChain as an effective, scalable framework for synthesizing multi-hop data that improves generalizable vision-language reasoning.
GLEAM: A Multimodal Imaging Dataset and HAMM for Glaucoma Classification
Mar 13, 2026We propose glaucoma lesion evaluation and analysis with multimodal imaging (GLEAM), the first publicly available tri-modal glaucoma dataset comprising scanning laser ophthalmoscopy fundus images, circumpapillary OCT images, and visual field pattern deviation maps, annotated with four disease stages, enabling effective exploitation of multimodal complementary information and facilitating accurate diagnosis and treatment across disease stages. To effectively integrate cross-modal information, we propose hierarchical attentive masked modeling (HAMM) for multimodal glaucoma classification. Our framework employs hierarchical attentive encoders and light decoders to focus cross-modal representation learning on the encoder.
Revealing Behavioral Plasticity in Large Language Models: A Token-Conditional Perspective
Mar 09, 2026In this work, we reveal that Large Language Models (LLMs) possess intrinsic behavioral plasticity-akin to chameleons adapting their coloration to environmental cues-that can be exposed through token-conditional generation and stabilized via reinforcement learning. Specifically, by conditioning generation on carefully selected token prefixes sampled from responses exhibiting desired behaviors, LLMs seamlessly adapt their behavioral modes at inference time (e.g., switching from step-by-step reasoning to direct answering) without retraining. Based on this insight, we propose Token-Conditioned Reinforcement Learning (ToCoRL), a principled framework that leverages RL to internalize this chameleon-like plasticity, transforming transient inference-time adaptations into stable and learnable behavioral patterns. ToCoRL guides exploration with token-conditional generation and keep enhancing exploitation, enabling emergence of appropriate behaviors. Extensive experiments show that ToCoRL enables precise behavioral control without capability degradation. Notably, we show that large reasoning models, while performing strongly on complex mathematics, can be effectively adapted to excel at factual question answering, which was a capability previously hindered by their step-by-step reasoning patterns.
TELEVAL: A Dynamic Benchmark Designed for Spoken Language Models in Chinese Interactive Scenarios
Jul 24, 2025Spoken language models (SLMs) have seen rapid progress in recent years, along with the development of numerous benchmarks for evaluating their performance. However, most existing benchmarks primarily focus on evaluating whether SLMs can perform complex tasks comparable to those tackled by large language models (LLMs), often failing to align with how users naturally interact in real-world conversational scenarios. In this paper, we propose TELEVAL, a dynamic benchmark specifically designed to evaluate SLMs' effectiveness as conversational agents in realistic Chinese interactive settings. TELEVAL defines three evaluation dimensions: Explicit Semantics, Paralinguistic and Implicit Semantics, and System Abilities. It adopts a dialogue format consistent with real-world usage and evaluates text and audio outputs separately. TELEVAL particularly focuses on the model's ability to extract implicit cues from user speech and respond appropriately without additional instructions. Our experiments demonstrate that despite recent progress, existing SLMs still have considerable room for improvement in natural conversational tasks. We hope that TELEVAL can serve as a user-centered evaluation framework that directly reflects the user experience and contributes to the development of more capable dialogue-oriented SLMs.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
Leveraging Black-box Models to Assess Feature Importance in Unconditional Distribution
Dec 07, 2024



Understanding how changes in explanatory features affect the unconditional distribution of the outcome is important in many applications. However, existing black-box predictive models are not readily suited for analyzing such questions. In this work, we develop an approximation method to compute the feature importance curves relevant to the unconditional distribution of outcomes, while leveraging the power of pre-trained black-box predictive models. The feature importance curves measure the changes across quantiles of outcome distribution given an external impact of change in the explanatory features. Through extensive numerical experiments and real data examples, we demonstrate that our approximation method produces sparse and faithful results, and is computationally efficient.
Guided and Fused: Efficient Frozen CLIP-ViT with Feature Guidance and Multi-Stage Feature Fusion for Generalizable Deepfake Detection
Aug 25, 2024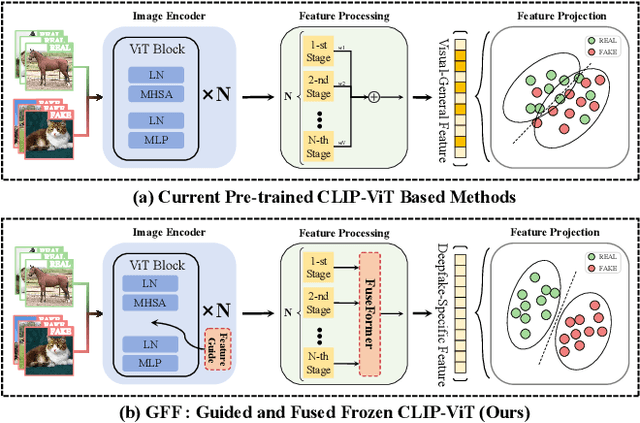



The rise of generative models has sparked concerns about image authenticity online, highlighting the urgent need for an effective and general detector. Recent methods leveraging the frozen pre-trained CLIP-ViT model have made great progress in deepfake detection. However, these models often rely on visual-general features directly extracted by the frozen network, which contain excessive information irrelevant to the task, resulting in limited detection performance. To address this limitation, in this paper, we propose an efficient Guided and Fused Frozen CLIP-ViT (GFF), which integrates two simple yet effective modules. The Deepfake-Specific Feature Guidance Module (DFGM) guides the frozen pre-trained model in extracting features specifically for deepfake detection, reducing irrelevant information while preserving its generalization capabilities. The Multi-Stage Fusion Module (FuseFormer) captures low-level and high-level information by fusing features extracted from each stage of the ViT. This dual-module approach significantly improves deepfake detection by fully leveraging CLIP-ViT's inherent advantages. Extensive experiments demonstrate the effectiveness and generalization ability of GFF, which achieves state-of-the-art performance with optimal results in only 5 training epochs. Even when trained on only 4 classes of ProGAN, GFF achieves nearly 99% accuracy on unseen GANs and maintains an impressive 97% accuracy on unseen diffusion models.
Leveraging Web-Crawled Data for High-Quality Fine-Tuning
Aug 15, 2024


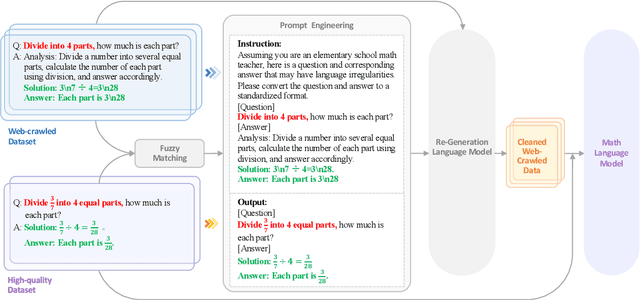
Most large language models are fine-tuned using either expensive human-annotated data or GPT-4 generated data which cannot guarantee performance in certain domains. We argue that although the web-crawled data often has formatting errors causing semantic inaccuracies, it can still serve as a valuable source for high-quality supervised fine-tuning in specific domains without relying on advanced models like GPT-4. To this end, we create a paired training dataset automatically by aligning web-crawled data with a smaller set of high-quality data. By training a language model on this dataset, we can convert web data with irregular formats into high-quality ones. Our experiments show that training with the model-transformed data yields better results, surpassing training with only high-quality data by an average score of 9.4% in Chinese math problems. Additionally, our 7B model outperforms several open-source models larger than 32B and surpasses well-known closed-source models such as GPT-3.5, highlighting the efficacy of our approach.
Revisiting Modularity Maximization for Graph Clustering: A Contrastive Learning Perspective
Jun 20, 2024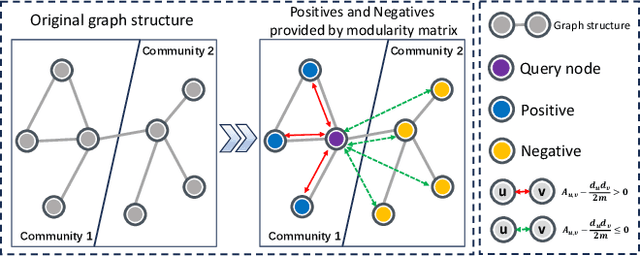
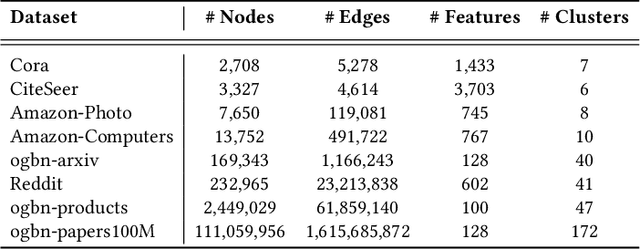
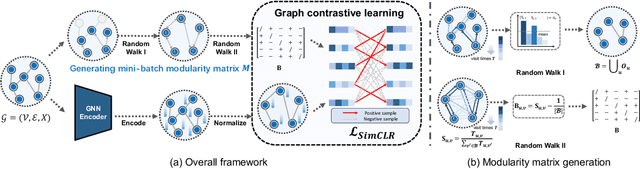
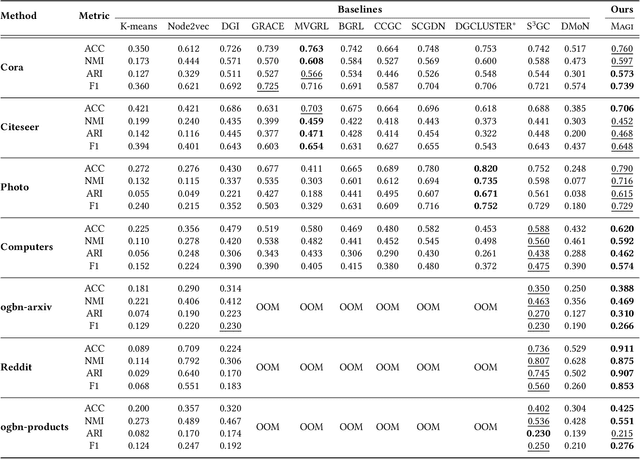
Graph clustering, a fundamental and challenging task in graph mining, aims to classify nodes in a graph into several disjoint clusters. In recent years, graph contrastive learning (GCL) has emerged as a dominant line of research in graph clustering and advances the new state-of-the-art. However, GCL-based methods heavily rely on graph augmentations and contrastive schemes, which may potentially introduce challenges such as semantic drift and scalability issues. Another promising line of research involves the adoption of modularity maximization, a popular and effective measure for community detection, as the guiding principle for clustering tasks. Despite the recent progress, the underlying mechanism of modularity maximization is still not well understood. In this work, we dig into the hidden success of modularity maximization for graph clustering. Our analysis reveals the strong connections between modularity maximization and graph contrastive learning, where positive and negative examples are naturally defined by modularity. In light of our results, we propose a community-aware graph clustering framework, coined MAGI, which leverages modularity maximization as a contrastive pretext task to effectively uncover the underlying information of communities in graphs, while avoiding the problem of semantic drift. Extensive experiments on multiple graph datasets verify the effectiveness of MAGI in terms of scalability and clustering performance compared to state-of-the-art graph clustering methods. Notably, MAGI easily scales a sufficiently large graph with 100M nodes while outperforming strong baselines.
A Selective Review on Statistical Methods for Massive Data Computation: Distributed Computing, Subsampling, and Minibatch Techniques
Mar 17, 2024This paper presents a selective review of statistical computation methods for massive data analysis. A huge amount of statistical methods for massive data computation have been rapidly developed in the past decades. In this work, we focus on three categories of statistical computation methods: (1) distributed computing, (2) subsampling methods, and (3) minibatch gradient techniques. The first class of literature is about distributed computing and focuses on the situation, where the dataset size is too huge to be comfortably handled by one single computer. In this case, a distributed computation system with multiple computers has to be utilized. The second class of literature is about subsampling methods and concerns about the situation, where the sample size of dataset is small enough to be placed on one single computer but too large to be easily processed by its memory as a whole. The last class of literature studies those minibatch gradient related optimization techniques, which have been extensively used for optimizing various deep learning models.