 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting AI-Generated Images via Distributional Deviations from Real Images
Jan 07, 2026The rapid advancement of generative models has significantly enhanced the quality of AI-generated images, raising concerns about misinformation and the erosion of public trust. Detecting AI-generated images has thus become a critical challenge, particularly in terms of generalizing to unseen generative models. Existing methods using frozen pre-trained CLIP models show promise in generalization but treat the image encoder as a basic feature extractor, failing to fully exploit its potential. In this paper, we perform an in-depth analysis of the frozen CLIP image encoder (CLIP-ViT), revealing that it effectively clusters real images in a high-level, abstract feature space. However, it does not truly possess the ability to distinguish between real and AI-generated images. Based on this analysis, we propose a Masking-based Pre-trained model Fine-Tuning (MPFT) strategy, which introduces a Texture-Aware Masking (TAM) mechanism to mask textured areas containing generative model-specific patterns during fine-tuning. This approach compels CLIP-ViT to attend to the "distributional deviations"from authentic images for AI-generated image detection, thereby achieving enhanced generalization performance. Extensive experiments on the GenImage and UniversalFakeDetect datasets demonstrate that our method, fine-tuned with only a minimal number of images, significantly outperforms existing approaches, achieving up to 98.2% and 94.6% average accuracy on the two datasets, respectively.
Multi-Scale Cross-Fusion and Edge-Supervision Network for Image Splicing Localization
Dec 17, 2024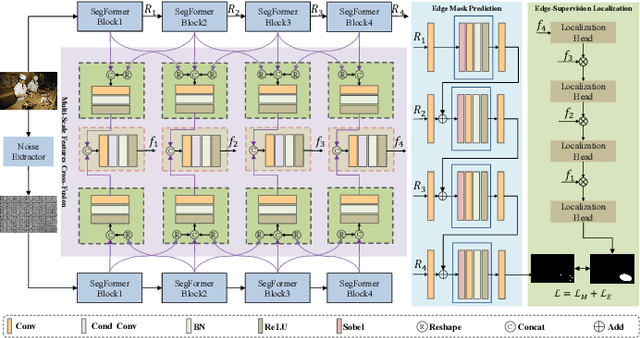



Image Splicing Localization (ISL) is a fundamental yet challenging task in digital forensics. Although current approaches have achieved promising performance, the edge information is insufficiently exploited, resulting in poor integrality and high false alarms. To tackle this problem, we propose a multi-scale cross-fusion and edge-supervision network for ISL. Specifically, our framework consists of three key steps: multi-scale features cross-fusion, edge mask prediction and edge-supervision localization. Firstly, we input the RGB image and its noise image into a segmentation network to learn multi-scale features, which are then aggregated via a cross-scale fusion followed by a cross-domain fusion to enhance feature representation. Secondly, we design an edge mask prediction module to effectively mine the reliable boundary artifacts. Finally, the cross-fused features and the reliable edge mask information are seamlessly integrated via an attention mechanism to incrementally supervise and facilitate model training. Extensive experiments on publicly available datasets demonstrate that our proposed method is superior to state-of-the-art schemes.
Learning on Less: Constraining Pre-trained Model Learning for Generalizable Diffusion-Generated Image Detection
Dec 01, 2024



Diffusion Models enable realistic image generation, raising the risk of misinformation and eroding public trust. Currently, detecting images generated by unseen diffusion models remains challenging due to the limited generalization capabilities of existing methods. To address this issue, we rethink the effectiveness of pre-trained models trained on large-scale, real-world images. Our findings indicate that: 1) Pre-trained models can cluster the features of real images effectively. 2) Models with pre-trained weights can approximate an optimal generalization solution at a specific training step, but it is extremely unstable. Based on these facts, we propose a simple yet effective training method called Learning on Less (LoL). LoL utilizes a random masking mechanism to constrain the model's learning of the unique patterns specific to a certain type of diffusion model, allowing it to focus on less image content. This leverages the inherent strengths of pre-trained weights while enabling a more stable approach to optimal generalization, which results in the extraction of a universal feature that differentiates various diffusion-generated images from real images. Extensive experiments on the GenImage benchmark demonstrate the remarkable generalization capability of our proposed LoL. With just 1% training data, LoL significantly outperforms the current state-of-the-art, achieving a 13.6% improvement in average ACC across images generated by eight different models.
Image Forgery Localization via Guided Noise and Multi-Scale Feature Aggregation
Nov 17, 2024



Image Forgery Localization (IFL) technology aims to detect and locate the forged areas in an image, which is very important in the field of digital forensics. However, existing IFL methods suffer from feature degradation during training using multi-layer convolutions or the self-attention mechanism, and perform poorly in detecting small forged regions and in robustness against post-processing. To tackle these, we propose a guided and multi-scale feature aggregated network for IFL. Spectifically, in order to comprehensively learn the noise feature under different types of forgery, we develop an effective noise extraction module in a guided way. Then, we design a Feature Aggregation Module (FAM) that uses dynamic convolution to adaptively aggregate RGB and noise features over multiple scales. Moreover, we propose an Atrous Residual Pyramid Module (ARPM) to enhance features representation and capture both global and local features using different receptive fields to improve the accuracy and robustness of forgery localization. Expensive experiments on 5 public datasets have shown that our proposed model outperforms several the state-of-the-art methods, specially on small region forged image.
TMFNet: Two-Stream Multi-Channels Fusion Networks for Color Image Operation Chain Detection
Sep 12, 2024



Image operation chain detection techniques have gained increasing attention recently in the field of multimedia forensics. However, existing detection methods suffer from the generalization problem. Moreover, the channel correlation of color images that provides additional forensic evidence is often ignored. To solve these issues, in this article, we propose a novel two-stream multi-channels fusion networks for color image operation chain detection in which the spatial artifact stream and the noise residual stream are explored in a complementary manner. Specifically, we first propose a novel deep residual architecture without pooling in the spatial artifact stream for learning the global features representation of multi-channel correlation. Then, a set of filters is designed to aggregate the correlation information of multi-channels while capturing the low-level features in the noise residual stream. Subsequently, the high-level features are extracted by the deep residual model. Finally, features from the two streams are fed into a fusion module, to effectively learn richer discriminative representations of the operation chain. Extensive experiments show that the proposed method achieves state-of-the-art generalization ability while maintaining robustness to JPEG compression. The source code used in these experiments will be released at https://github.com/LeiTan-98/TMFNet.
Guided and Fused: Efficient Frozen CLIP-ViT with Feature Guidance and Multi-Stage Feature Fusion for Generalizable Deepfake Detection
Aug 25, 2024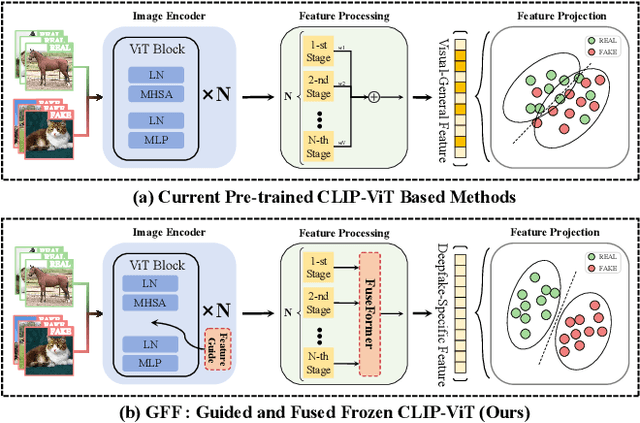



The rise of generative models has sparked concerns about image authenticity online, highlighting the urgent need for an effective and general detector. Recent methods leveraging the frozen pre-trained CLIP-ViT model have made great progress in deepfake detection. However, these models often rely on visual-general features directly extracted by the frozen network, which contain excessive information irrelevant to the task, resulting in limited detection performance. To address this limitation, in this paper, we propose an efficient Guided and Fused Frozen CLIP-ViT (GFF), which integrates two simple yet effective modules. The Deepfake-Specific Feature Guidance Module (DFGM) guides the frozen pre-trained model in extracting features specifically for deepfake detection, reducing irrelevant information while preserving its generalization capabilities. The Multi-Stage Fusion Module (FuseFormer) captures low-level and high-level information by fusing features extracted from each stage of the ViT. This dual-module approach significantly improves deepfake detection by fully leveraging CLIP-ViT's inherent advantages. Extensive experiments demonstrate the effectiveness and generalization ability of GFF, which achieves state-of-the-art performance with optimal results in only 5 training epochs. Even when trained on only 4 classes of ProGAN, GFF achieves nearly 99% accuracy on unseen GANs and maintains an impressive 97% accuracy on unseen diffusion models.
Image Splicing Detection, Localization and Attribution via JPEG Primary Quantization Matrix Estimation and Clustering
Feb 02, 2021
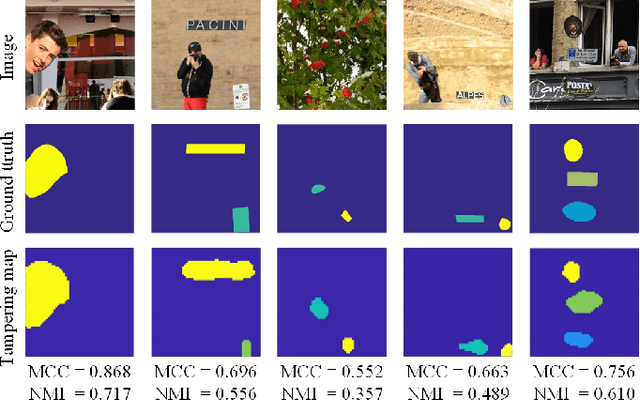
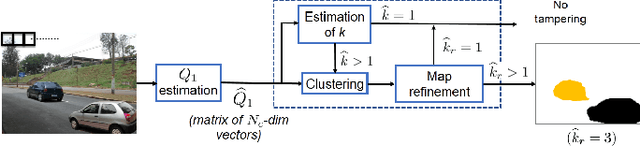
Detection of inconsistencies of double JPEG artefacts across different image regions is often used to detect local image manipulations, like image splicing, and to localize them. In this paper, we move one step further, proposing an end-to-end system that, in addition to detecting and localizing spliced regions, can also distinguish regions coming from different donor images. We assume that both the spliced regions and the background image have undergone a double JPEG compression, and use a local estimate of the primary quantization matrix to distinguish between spliced regions taken from different sources. To do so, we cluster the image blocks according to the estimated primary quantization matrix and refine the result by means of morphological reconstruction. The proposed method can work in a wide variety of settings including aligned and non-aligned double JPEG compression, and regardless of whether the second compression is stronger or weaker than the first one. We validated the proposed approach by means of extensive experiments showing its superior performance with respect to baseline methods working in similar conditions.