 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIND: A Simple yet Effective Baseline for Diffusion-Generated Image Detection
Mar 15, 2026The remarkable realism of images generated by diffusion models poses critical detection challenges. Current methods utilize reconstruction error as a discriminative feature, exploiting the observation that real images exhibit higher reconstruction errors when processed through diffusion models. However, these approaches require costly reconstruction computations and depend on specific diffusion models, making their performance highly model-dependent. We identify a fundamental difference: real images are more difficult to fit with Gaussian distributions compared to synthetic ones. In this paper, we propose Forgery Identification via Noise Disturbance (FIND), a novel method that requires only a simple binary classifier. It eliminates reconstruction by directly targeting the core distributional difference between real and synthetic images. Our key operation is to add Gaussian noise to real images during training and label these noisy versions as synthetic. This step allows the classifier to focus on the statistical patterns that distinguish real from synthetic images. We theoretically prove that the noise-augmented real images resemble diffusion-generated images in their ease of Gaussian fitting. Furthermore, simply by adding noise, they still retain visual similarity to the original images, highlighting the most discriminative distribution-related features. The proposed FIND improves performance by 11.7% on the GenImage benchmark while running 126x faster than existing methods. By removing the need for auxiliary diffusion models and reconstruction, it offers a practical, efficient, and generalizable way to detect diffusion-generated content.
Bridging Day and Night: Target-Class Hallucination Suppression in Unpaired Image Translation
Feb 17, 2026Day-to-night unpaired image translation is important to downstream tasks but remains challenging due to large appearance shifts and the lack of direct pixel-level supervision. Existing methods often introduce semantic hallucinations, where objects from target classes such as traffic signs and vehicles, as well as man-made light effects, are incorrectly synthesized. These hallucinations significantly degrade downstream performance. We propose a novel framework that detects and suppresses hallucinations of target-class features during unpaired translation. To detect hallucination, we design a dual-head discriminator that additionally performs semantic segmentation to identify hallucinated content in background regions. To suppress these hallucinations, we introduce class-specific prototypes, constructed by aggregating features of annotated target-domain objects, which act as semantic anchors for each class. Built upon a Schrodinger Bridge-based translation model, our framework performs iterative refinement, where detected hallucination features are explicitly pushed away from class prototypes in feature space, thus preserving object semantics across the translation trajectory.Experiments show that our method outperforms existing approaches both qualitatively and quantitatively. On the BDD100K dataset, it improves mAP by 15.5% for day-to-night domain adaptation, with a notable 31.7% gain for classes such as traffic lights that are prone to hallucinations.
Aggregating Diverse Cue Experts for AI-Generated Image Detection
Jan 13, 2026The rapid emergence of image synthesis models poses challenges to the generalization of AI-generated image detectors. However, existing methods often rely on model-specific features, leading to overfitting and poor generalization. In this paper, we introduce the Multi-Cue Aggregation Network (MCAN), a novel framework that integrates different yet complementary cues in a unified network. MCAN employs a mixture-of-encoders adapter to dynamically process these cues, enabling more adaptive and robust feature representation. Our cues include the input image itself, which represents the overall content, and high-frequency components that emphasize edge details. Additionally, we introduce a Chromatic Inconsistency (CI) cue, which normalizes intensity values and captures noise information introduced during the image acquisition process in real images, making these noise patterns more distinguishable from those in AI-generated content. Unlike prior methods, MCAN's novelty lies in its unified multi-cue aggregation framework, which integrates spatial, frequency-domain, and chromaticity-based information for enhanced representation learning. These cues are intrinsically more indicative of real images, enhancing cross-model generalization. Extensive experiments on the GenImage, Chameleon, and UniversalFakeDetect benchmark validate the state-of-the-art performance of MCAN. In the GenImage dataset, MCAN outperforms the best state-of-the-art method by up to 7.4% in average ACC across eight different image generators.
WeakMCN: Multi-task Collaborative Network for Weakly Supervised Referring Expression Comprehension and Segmentation
May 24, 2025Weakly supervised referring expression comprehension(WREC) and segmentation(WRES) aim to learn object grounding based on a given expression using weak supervision signals like image-text pairs. While these tasks have traditionally been modeled separately, we argue that they can benefit from joint learning in a multi-task framework. To this end, we propose WeakMCN, a novel multi-task collaborative network that effectively combines WREC and WRES with a dual-branch architecture. Specifically, the WREC branch is formulated as anchor-based contrastive learning, which also acts as a teacher to supervise the WRES branch. In WeakMCN, we propose two innovative designs to facilitate multi-task collaboration, namely Dynamic Visual Feature Enhancement(DVFE) and Collaborative Consistency Module(CCM). DVFE dynamically combines various pre-trained visual knowledge to meet different task requirements, while CCM promotes cross-task consistency from the perspective of optimization. Extensive experimental results on three popular REC and RES benchmarks, i.e., RefCOCO, RefCOCO+, and RefCOCOg, consistently demonstrate performance gains of WeakMCN over state-of-the-art single-task alternatives, e.g., up to 3.91% and 13.11% on RefCOCO for WREC and WRES tasks, respectively. Furthermore, experiments also validate the strong generalization ability of WeakMCN in both semi-supervised REC and RES settings against existing methods, e.g., +8.94% for semi-REC and +7.71% for semi-RES on 1% RefCOCO. The code is publicly available at https://github.com/MRUIL/WeakMCN.
Adversarial Shallow Watermarking
Apr 28, 2025



Recent advances in digital watermarking make use of deep neural networks for message embedding and extraction. They typically follow the ``encoder-noise layer-decoder''-based architecture. By deliberately establishing a differentiable noise layer to simulate the distortion of the watermarked signal, they jointly train the deep encoder and decoder to fit the noise layer to guarantee robustness. As a result, they are usually weak against unknown distortions that are not used in their training pipeline. In this paper, we propose a novel watermarking framework to resist unknown distortions, namely Adversarial Shallow Watermarking (ASW). ASW utilizes only a shallow decoder that is randomly parameterized and designed to be insensitive to distortions for watermarking extraction. During the watermark embedding, ASW freezes the shallow decoder and adversarially optimizes a host image until its updated version (i.e., the watermarked image) stably triggers the shallow decoder to output the watermark message. During the watermark extraction, it accurately recovers the message from the watermarked image by leveraging the insensitive nature of the shallow decoder against arbitrary distortions. Our ASW is training-free, encoder-free, and noise layer-free. Experiments indicate that the watermarked images created by ASW have strong robustness against various unknown distortions. Compared to the existing ``encoder-noise layer-decoder'' approaches, ASW achieves comparable results on known distortions and better robustness on unknown distortions.
Knowing Where to Focus: Attention-Guided Alignment for Text-based Person Search
Dec 19, 2024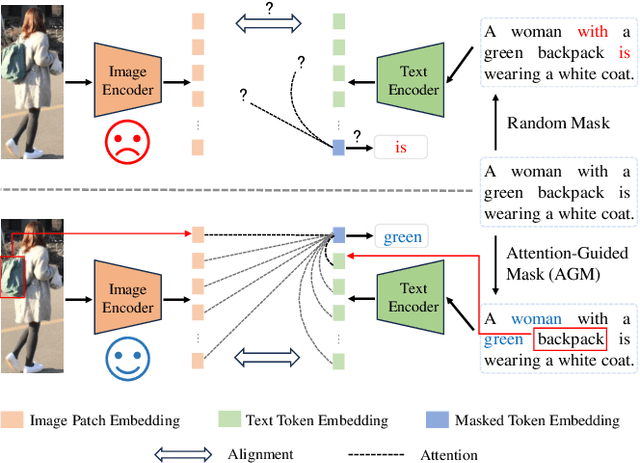
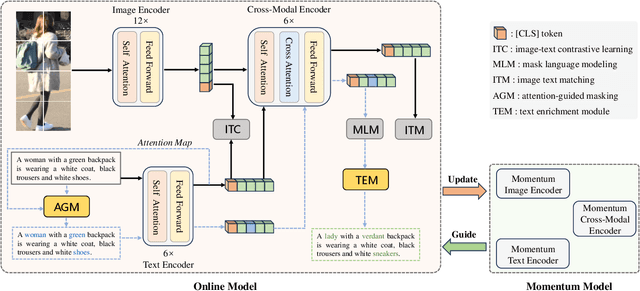


In the realm of Text-Based Person Search (TBPS), mainstream methods aim to explore more efficient interaction frameworks between text descriptions and visual data. However, recent approaches encounter two principal challenges. Firstly, the widely used random-based Masked Language Modeling (MLM) considers all the words in the text equally during training. However, massive semantically vacuous words ('with', 'the', etc.) be masked fail to contribute efficient interaction in the cross-modal MLM and hampers the representation alignment. Secondly, manual descriptions in TBPS datasets are tedious and inevitably contain several inaccuracies. To address these issues, we introduce an Attention-Guided Alignment (AGA) framework featuring two innovative components: Attention-Guided Mask (AGM) Modeling and Text Enrichment Module (TEM). AGM dynamically masks semantically meaningful words by aggregating the attention weight derived from the text encoding process, thereby cross-modal MLM can capture information related to the masked word from text context and images and align their representations. Meanwhile, TEM alleviates low-quality representations caused by repetitive and erroneous text descriptions by replacing those semantically meaningful words with MLM's prediction. It not only enriches text descriptions but also prevents overfitting. Extensive experiments across three challenging benchmarks demonstrate the effectiveness of our AGA, achieving new state-of-the-art results with Rank-1 accuracy reaching 78.36%, 67.31%, and 67.4% on CUHK-PEDES, ICFG-PEDES, and RSTPReid, respectively.
Learning on Less: Constraining Pre-trained Model Learning for Generalizable Diffusion-Generated Image Detection
Dec 01, 2024



Diffusion Models enable realistic image generation, raising the risk of misinformation and eroding public trust. Currently, detecting images generated by unseen diffusion models remains challenging due to the limited generalization capabilities of existing methods. To address this issue, we rethink the effectiveness of pre-trained models trained on large-scale, real-world images. Our findings indicate that: 1) Pre-trained models can cluster the features of real images effectively. 2) Models with pre-trained weights can approximate an optimal generalization solution at a specific training step, but it is extremely unstable. Based on these facts, we propose a simple yet effective training method called Learning on Less (LoL). LoL utilizes a random masking mechanism to constrain the model's learning of the unique patterns specific to a certain type of diffusion model, allowing it to focus on less image content. This leverages the inherent strengths of pre-trained weights while enabling a more stable approach to optimal generalization, which results in the extraction of a universal feature that differentiates various diffusion-generated images from real images. Extensive experiments on the GenImage benchmark demonstrate the remarkable generalization capability of our proposed LoL. With just 1% training data, LoL significantly outperforms the current state-of-the-art, achieving a 13.6% improvement in average ACC across images generated by eight different models.
Image Forgery Localization via Guided Noise and Multi-Scale Feature Aggregation
Nov 17, 2024



Image Forgery Localization (IFL) technology aims to detect and locate the forged areas in an image, which is very important in the field of digital forensics. However, existing IFL methods suffer from feature degradation during training using multi-layer convolutions or the self-attention mechanism, and perform poorly in detecting small forged regions and in robustness against post-processing. To tackle these, we propose a guided and multi-scale feature aggregated network for IFL. Spectifically, in order to comprehensively learn the noise feature under different types of forgery, we develop an effective noise extraction module in a guided way. Then, we design a Feature Aggregation Module (FAM) that uses dynamic convolution to adaptively aggregate RGB and noise features over multiple scales. Moreover, we propose an Atrous Residual Pyramid Module (ARPM) to enhance features representation and capture both global and local features using different receptive fields to improve the accuracy and robustness of forgery localization. Expensive experiments on 5 public datasets have shown that our proposed model outperforms several the state-of-the-art methods, specially on small region forged image.
RLE: A Unified Perspective of Data Augmentation for Cross-Spectral Re-identification
Nov 02, 2024



This paper makes a step towards modeling the modality discrepancy in the cross-spectral re-identification task. Based on the Lambertain model, we observe that the non-linear modality discrepancy mainly comes from diverse linear transformations acting on the surface of different materials. From this view, we unify all data augmentation strategies for cross-spectral re-identification by mimicking such local linear transformations and categorizing them into moderate transformation and radical transformation. By extending the observation, we propose a Random Linear Enhancement (RLE) strategy which includes Moderate Random Linear Enhancement (MRLE) and Radical Random Linear Enhancement (RRLE) to push the boundaries of both types of transformation. Moderate Random Linear Enhancement is designed to provide diverse image transformations that satisfy the original linear correlations under constrained conditions, whereas Radical Random Linear Enhancement seeks to generate local linear transformations directly without relying on external information. The experimental results not only demonstrate the superiority and effectiveness of RLE but also confirm its great potential as a general-purpose data augmentation for cross-spectral re-identification. The code is available at \textcolor{magenta}{\url{https://github.com/stone96123/RLE}}.
TMFNet: Two-Stream Multi-Channels Fusion Networks for Color Image Operation Chain Detection
Sep 12, 2024



Image operation chain detection techniques have gained increasing attention recently in the field of multimedia forensics. However, existing detection methods suffer from the generalization problem. Moreover, the channel correlation of color images that provides additional forensic evidence is often ignored. To solve these issues, in this article, we propose a novel two-stream multi-channels fusion networks for color image operation chain detection in which the spatial artifact stream and the noise residual stream are explored in a complementary manner. Specifically, we first propose a novel deep residual architecture without pooling in the spatial artifact stream for learning the global features representation of multi-channel correlation. Then, a set of filters is designed to aggregate the correlation information of multi-channels while capturing the low-level features in the noise residual stream. Subsequently, the high-level features are extracted by the deep residual model. Finally, features from the two streams are fed into a fusion module, to effectively learn richer discriminative representations of the operation chain. Extensive experiments show that the proposed method achieves state-of-the-art generalization ability while maintaining robustness to JPEG compression. The source code used in these experiments will be released at https://github.com/LeiTan-98/TMFNet.