 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Unified Generation and Understanding Models Maintain Semantic Equivalence Across Different Output Modalities?
Feb 27, 2026Unified Multimodal Large Language Models (U-MLLMs) integrate understanding and generation within a single architecture. However, existing evaluations typically assess these capabilities separately, overlooking semantic equivalence, i.e., the ability to manifest consistent reasoning results regardless of the output modality. In this work, we investigate whether current U-MLLMs satisfy this premise. We observe that while models demonstrate robust textual reasoning, they fail to maintain semantic equivalence when required to render the same results in the image modality. To rigorously diagnose this discrepancy, we introduce VGUBench, a framework to decouple reasoning logic from generation fidelity. VGUBench comprises three diagnostic tasks: (1)Textual Generative Understanding, establishing a baseline for reasoning accuracy in textual response; (2)Visual Generative Understanding, evaluating the ability to generate visual responses that represent the correct answer; and (3)a Visual Rendering control task, which assesses the ability to directly render explicit visual descriptions into images without complex reasoning. Our evaluation reveals a significant disparity: despite strong performance in textual understanding and visual rendering, U-MLLMs exhibit a marked performance collapse when required to generate visual answers to questions. Furthermore, we find a negligible correlation between visual answering performance and basic rendering quality. These results suggest that the failure stems not from insufficient generation fidelity, but from a breakdown in cross-modal semantic alignment. We provide diagnostic insights to address this challenge in future Unified Generation and Understanding Models.
Unleashing MLLMs on the Edge: A Unified Framework for Cross-Modal ReID via Adaptive SVD Distillation
Feb 13, 2026Practical cloud-edge deployment of Cross-Modal Re-identification (CM-ReID) faces challenges due to maintaining a fragmented ecosystem of specialized cloud models for diverse modalities. While Multi-Modal Large Language Models (MLLMs) offer strong unification potential, existing approaches fail to adapt them into a single end-to-end backbone and lack effective knowledge distillation strategies for edge deployment. To address these limitations, we propose MLLMEmbed-ReID, a unified framework based on a powerful cloud-edge architecture. First, we adapt a foundational MLLM into a state-of-the-art cloud model. We leverage instruction-based prompting to guide the MLLM in generating a unified embedding space across RGB, infrared, sketch, and text modalities. This model is then trained efficiently with a hierarchical Low-Rank Adaptation finetuning (LoRA-SFT) strategy, optimized under a holistic cross-modal alignment objective. Second, to deploy its knowledge onto an edge-native student, we introduce a novel distillation strategy motivated by the low-rank property in the teacher's feature space. To prioritize essential information, this method employs a Principal Component Mapping loss, while relational structures are preserved via a Feature Relation loss. Our lightweight edge-based model achieves state-of-the-art performance on multiple visual CM-ReID benchmarks, while its cloud-based counterpart excels across all CM-ReID benchmarks. The MLLMEmbed-ReID framework thus presents a complete and effective solution for deploying unified MLLM-level intelligence on resource-constrained devices. The code and models will be open-sourced soon.
Evolving, Not Training: Zero-Shot Reasoning Segmentation via Evolutionary Prompting
Dec 31, 2025Reasoning Segmentation requires models to interpret complex, context-dependent linguistic queries to achieve pixel-level localization. Current dominant approaches rely heavily on Supervised Fine-Tuning (SFT) or Reinforcement Learning (RL). However, SFT suffers from catastrophic forgetting and domain dependency, while RL is often hindered by training instability and rigid reliance on predefined reward functions. Although recent training-free methods circumvent these training burdens, they are fundamentally limited by a static inference paradigm. These methods typically rely on a single-pass "generate-then-segment" chain, which suffers from insufficient reasoning depth and lacks the capability to self-correct linguistic hallucinations or spatial misinterpretations. In this paper, we challenge these limitations and propose EVOL-SAM3, a novel zero-shot framework that reformulates reasoning segmentation as an inference-time evolutionary search process. Instead of relying on a fixed prompt, EVOL-SAM3 maintains a population of prompt hypotheses and iteratively refines them through a "Generate-Evaluate-Evolve" loop. We introduce a Visual Arena to assess prompt fitness via reference-free pairwise tournaments, and a Semantic Mutation operator to inject diversity and correct semantic errors. Furthermore, a Heterogeneous Arena module integrates geometric priors with semantic reasoning to ensure robust final selection. Extensive experiments demonstrate that EVOL-SAM3 not only substantially outperforms static baselines but also significantly surpasses fully supervised state-of-the-art methods on the challenging ReasonSeg benchmark in a zero-shot setting. The code is available at https://github.com/AHideoKuzeA/Evol-SAM3.
Understanding What Is Not Said:Referring Remote Sensing Image Segmentation with Scarce Expressions
Oct 26, 2025Referring Remote Sensing Image Segmentation (RRSIS) aims to segment instances in remote sensing images according to referring expressions. Unlike Referring Image Segmentation on general images, acquiring high-quality referring expressions in the remote sensing domain is particularly challenging due to the prevalence of small, densely distributed objects and complex backgrounds. This paper introduces a new learning paradigm, Weakly Referring Expression Learning (WREL) for RRSIS, which leverages abundant class names as weakly referring expressions together with a small set of accurate ones to enable efficient training under limited annotation conditions. Furthermore, we provide a theoretical analysis showing that mixed-referring training yields a provable upper bound on the performance gap relative to training with fully annotated referring expressions, thereby establishing the validity of this new setting. We also propose LRB-WREL, which integrates a Learnable Reference Bank (LRB) to refine weakly referring expressions through sample-specific prompt embeddings that enrich coarse class-name inputs. Combined with a teacher-student optimization framework using dynamically scheduled EMA updates, LRB-WREL stabilizes training and enhances cross-modal generalization under noisy weakly referring supervision. Extensive experiments on our newly constructed benchmark with varying weakly referring data ratios validate both the theoretical insights and the practical effectiveness of WREL and LRB-WREL, demonstrating that they can approach or even surpass models trained with fully annotated referring expressions.
RIS-LAD: A Benchmark and Model for Referring Low-Altitude Drone Image Segmentation
Jul 28, 2025Referring Image Segmentation (RIS), which aims to segment specific objects based on natural language descriptions, plays an essential role in vision-language understanding. Despite its progress in remote sensing applications, RIS in Low-Altitude Drone (LAD) scenarios remains underexplored. Existing datasets and methods are typically designed for high-altitude and static-view imagery. They struggle to handle the unique characteristics of LAD views, such as diverse viewpoints and high object density. To fill this gap, we present RIS-LAD, the first fine-grained RIS benchmark tailored for LAD scenarios. This dataset comprises 13,871 carefully annotated image-text-mask triplets collected from realistic drone footage, with a focus on small, cluttered, and multi-viewpoint scenes. It highlights new challenges absent in previous benchmarks, such as category drift caused by tiny objects and object drift under crowded same-class objects. To tackle these issues, we propose the Semantic-Aware Adaptive Reasoning Network (SAARN). Rather than uniformly injecting all linguistic features, SAARN decomposes and routes semantic information to different stages of the network. Specifically, the Category-Dominated Linguistic Enhancement (CDLE) aligns visual features with object categories during early encoding, while the Adaptive Reasoning Fusion Module (ARFM) dynamically selects semantic cues across scales to improve reasoning in complex scenes. The experimental evaluation reveals that RIS-LAD presents substantial challenges to state-of-the-art RIS algorithms, and also demonstrates the effectiveness of our proposed model in addressing these challenges. The dataset and code will be publicly released soon at: https://github.com/AHideoKuzeA/RIS-LAD/.
More Clear, More Flexible, More Precise: A Comprehensive Oriented Object Detection benchmark for UAV
Apr 28, 2025Applications of unmanned aerial vehicle (UAV) in logistics, agricultural automation, urban management, and emergency response are highly dependent on oriented object detection (OOD) to enhance visual perception. Although existing datasets for OOD in UAV provide valuable resources, they are often designed for specific downstream tasks.Consequently, they exhibit limited generalization performance in real flight scenarios and fail to thoroughly demonstrate algorithm effectiveness in practical environments. To bridge this critical gap, we introduce CODrone, a comprehensive oriented object detection dataset for UAVs that accurately reflects real-world conditions. It also serves as a new benchmark designed to align with downstream task requirements, ensuring greater applicability and robustness in UAV-based OOD.Based on application requirements, we identify four key limitations in current UAV OOD datasets-low image resolution, limited object categories, single-view imaging, and restricted flight altitudes-and propose corresponding improvements to enhance their applicability and robustness.Furthermore, CODrone contains a broad spectrum of annotated images collected from multiple cities under various lighting conditions, enhancing the realism of the benchmark. To rigorously evaluate CODrone as a new benchmark and gain deeper insights into the novel challenges it presents, we conduct a series of experiments based on 22 classical or SOTA methods.Our evaluation not only assesses the effectiveness of CODrone in real-world scenarios but also highlights key bottlenecks and opportunities to advance OOD in UAV applications.Overall, CODrone fills the data gap in OOD from UAV perspective and provides a benchmark with enhanced generalization capability, better aligning with practical applications and future algorithm development.
Knowing Where to Focus: Attention-Guided Alignment for Text-based Person Search
Dec 19, 2024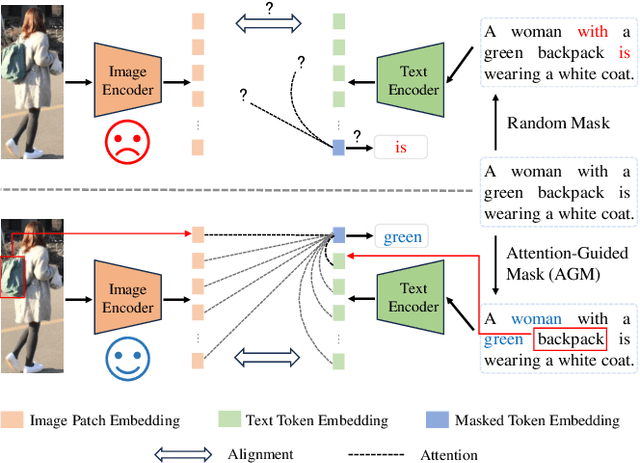
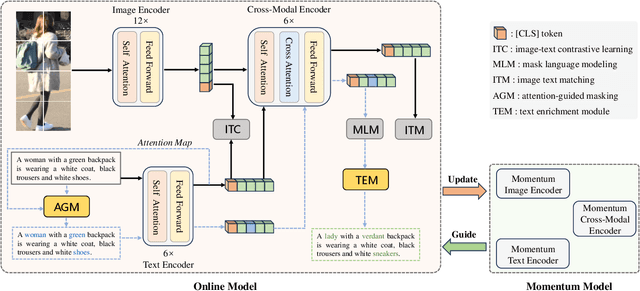


In the realm of Text-Based Person Search (TBPS), mainstream methods aim to explore more efficient interaction frameworks between text descriptions and visual data. However, recent approaches encounter two principal challenges. Firstly, the widely used random-based Masked Language Modeling (MLM) considers all the words in the text equally during training. However, massive semantically vacuous words ('with', 'the', etc.) be masked fail to contribute efficient interaction in the cross-modal MLM and hampers the representation alignment. Secondly, manual descriptions in TBPS datasets are tedious and inevitably contain several inaccuracies. To address these issues, we introduce an Attention-Guided Alignment (AGA) framework featuring two innovative components: Attention-Guided Mask (AGM) Modeling and Text Enrichment Module (TEM). AGM dynamically masks semantically meaningful words by aggregating the attention weight derived from the text encoding process, thereby cross-modal MLM can capture information related to the masked word from text context and images and align their representations. Meanwhile, TEM alleviates low-quality representations caused by repetitive and erroneous text descriptions by replacing those semantically meaningful words with MLM's prediction. It not only enriches text descriptions but also prevents overfitting. Extensive experiments across three challenging benchmarks demonstrate the effectiveness of our AGA, achieving new state-of-the-art results with Rank-1 accuracy reaching 78.36%, 67.31%, and 67.4% on CUHK-PEDES, ICFG-PEDES, and RSTPReid, respectively.
RLE: A Unified Perspective of Data Augmentation for Cross-Spectral Re-identification
Nov 02, 2024



This paper makes a step towards modeling the modality discrepancy in the cross-spectral re-identification task. Based on the Lambertain model, we observe that the non-linear modality discrepancy mainly comes from diverse linear transformations acting on the surface of different materials. From this view, we unify all data augmentation strategies for cross-spectral re-identification by mimicking such local linear transformations and categorizing them into moderate transformation and radical transformation. By extending the observation, we propose a Random Linear Enhancement (RLE) strategy which includes Moderate Random Linear Enhancement (MRLE) and Radical Random Linear Enhancement (RRLE) to push the boundaries of both types of transformation. Moderate Random Linear Enhancement is designed to provide diverse image transformations that satisfy the original linear correlations under constrained conditions, whereas Radical Random Linear Enhancement seeks to generate local linear transformations directly without relying on external information. The experimental results not only demonstrate the superiority and effectiveness of RLE but also confirm its great potential as a general-purpose data augmentation for cross-spectral re-identification. The code is available at \textcolor{magenta}{\url{https://github.com/stone96123/RLE}}.
PartFormer: Awakening Latent Diverse Representation from Vision Transformer for Object Re-Identification
Aug 29, 2024



Extracting robust feature representation is critical for object re-identification to accurately identify objects across non-overlapping cameras. Although having a strong representation ability, the Vision Transformer (ViT) tends to overfit on most distinct regions of training data, limiting its generalizability and attention to holistic object features. Meanwhile, due to the structural difference between CNN and ViT, fine-grained strategies that effectively address this issue in CNN do not continue to be successful in ViT. To address this issue, by observing the latent diverse representation hidden behind the multi-head attention, we present PartFormer, an innovative adaptation of ViT designed to overcome the granularity limitations in object Re-ID tasks. The PartFormer integrates a Head Disentangling Block (HDB) that awakens the diverse representation of multi-head self-attention without the typical loss of feature richness induced by concatenation and FFN layers post-attention. To avoid the homogenization of attention heads and promote robust part-based feature learning, two head diversity constraints are imposed: attention diversity constraint and correlation diversity constraint. These constraints enable the model to exploit diverse and discriminative feature representations from different attention heads. Comprehensive experiments on various object Re-ID benchmarks demonstrate the superiority of the PartFormer. Specifically, our framework significantly outperforms state-of-the-art by 2.4\% mAP scores on the most challenging MSMT17 dataset.
Feature Denoising Diffusion Model for Blind Image Quality Assessment
Jan 22, 2024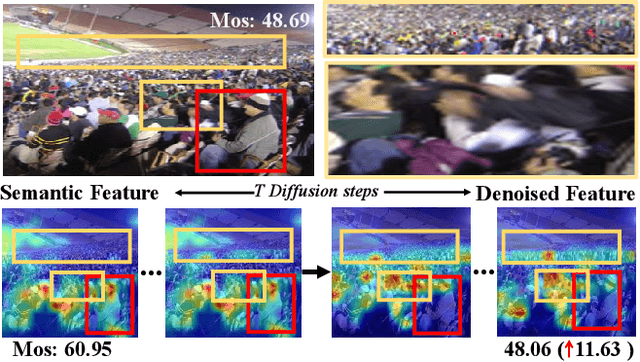
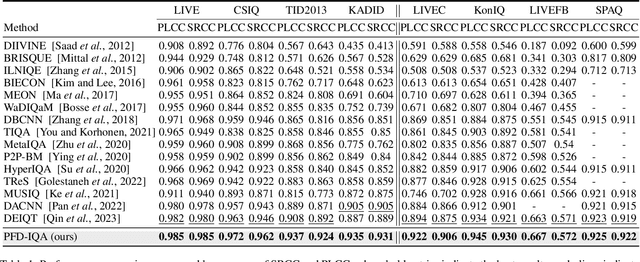
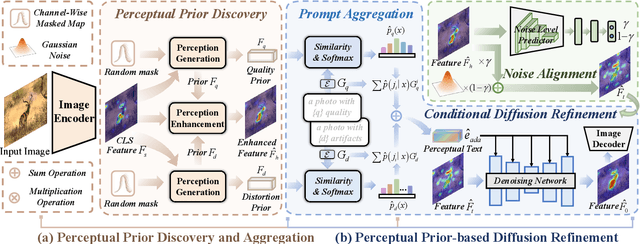
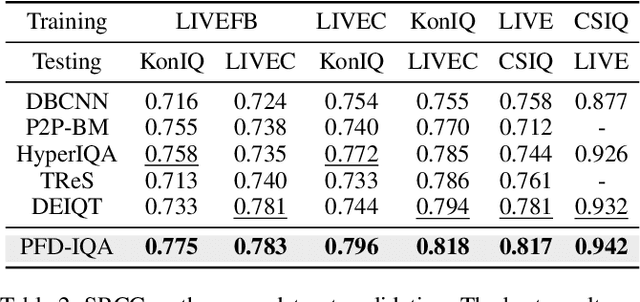
Blind Image Quality Assessment (BIQA) aims to evaluate image quality in line with human perception, without reference benchmarks. Currently, deep learning BIQA methods typically depend on using features from high-level tasks for transfer learning. However, the inherent differences between BIQA and these high-level tasks inevitably introduce noise into the quality-aware features. In this paper, we take an initial step towards exploring the diffusion model for feature denoising in BIQA, namely Perceptual Feature Diffusion for IQA (PFD-IQA), which aims to remove noise from quality-aware features. Specifically, (i) We propose a {Perceptual Prior Discovery and Aggregation module to establish two auxiliary tasks to discover potential low-level features in images that are used to aggregate perceptual text conditions for the diffusion model. (ii) We propose a Perceptual Prior-based Feature Refinement strategy, which matches noisy features to predefined denoising trajectories and then performs exact feature denoising based on text conditions. Extensive experiments on eight standard BIQA datasets demonstrate the superior performance to the state-of-the-art BIQA methods, i.e., achieving the PLCC values of 0.935 ( vs. 0.905 in KADID) and 0.922 ( vs. 0.894 in LIVEC).