 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmentation-Based Attention Entropy: Detecting and Mitigating Object Hallucinations in Large Vision-Language Models
Mar 17, 2026Large Vision-Language Models (LVLMs) achieve strong performance on many multimodal tasks, but object hallucinations severely undermine their reliability. Most existing studies focus on the text modality, attributing hallucinations to overly strong language priors and insufficient visual grounding. In contrast, we observe that abnormal attention patterns within the visual modality can also give rise to hallucinated objects. Building on this observation, we propose Segmentation-based Attention Entropy (SAE), which leverages semantic segmentation to quantify visual attention uncertainty in an object-level semantic space. Based on SAE, we further design a reliability score for hallucination detection and an SAE-guided attention adjustment method that modifies visual attention at inference time to mitigate hallucinations. We evaluate our approach on public benchmarks and in real embodied multimodal scenarios with quadruped robots. Experimental results show that SAE substantially reduces object hallucinations without any additional training cost, thereby enabling more trustworthy LVLM-driven perception and decision-making.
GarmentGS: Point-Cloud Guided Gaussian Splatting for High-Fidelity Non-Watertight 3D Garment Reconstruction
May 04, 2025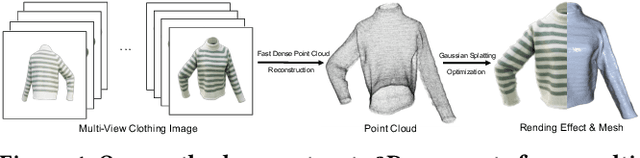
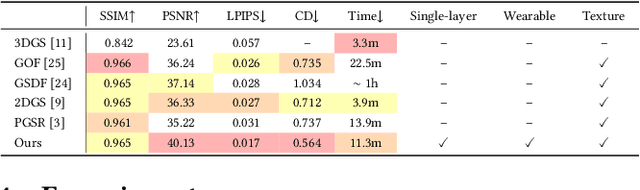
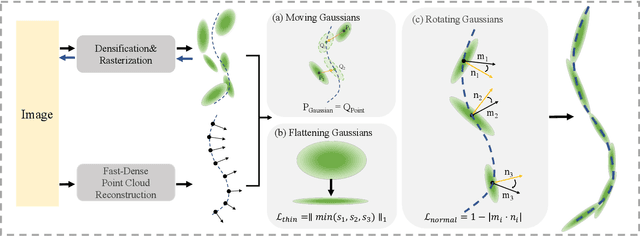
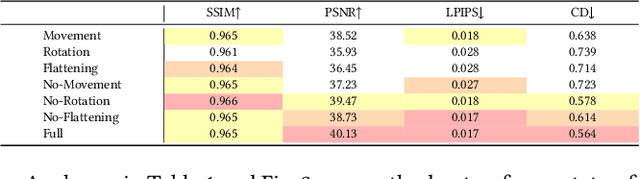
Traditional 3D garment creation requires extensive manual operations, resulting in time and labor costs. Recently, 3D Gaussian Splatting has achieved breakthrough progress in 3D scene reconstruction and rendering, attracting widespread attention and opening new pathways for 3D garment reconstruction. However, due to the unstructured and irregular nature of Gaussian primitives, it is difficult to reconstruct high-fidelity, non-watertight 3D garments. In this paper, we present GarmentGS, a dense point cloud-guided method that can reconstruct high-fidelity garment surfaces with high geometric accuracy and generate non-watertight, single-layer meshes. Our method introduces a fast dense point cloud reconstruction module that can complete garment point cloud reconstruction in 10 minutes, compared to traditional methods that require several hours. Furthermore, we use dense point clouds to guide the movement, flattening, and rotation of Gaussian primitives, enabling better distribution on the garment surface to achieve superior rendering effects and geometric accuracy. Through numerical and visual comparisons, our method achieves fast training and real-time rendering while maintaining competitive quality.
IVLMap: Instance-Aware Visual Language Grounding for Consumer Robot Navigation
Mar 28, 2024Vision-and-Language Navigation (VLN) is a challenging task that requires a robot to navigate in photo-realistic environments with human natural language promptings. Recent studies aim to handle this task by constructing the semantic spatial map representation of the environment, and then leveraging the strong ability of reasoning in large language models for generalizing code for guiding the robot navigation. However, these methods face limitations in instance-level and attribute-level navigation tasks as they cannot distinguish different instances of the same object. To address this challenge, we propose a new method, namely, Instance-aware Visual Language Map (IVLMap), to empower the robot with instance-level and attribute-level semantic mapping, where it is autonomously constructed by fusing the RGBD video data collected from the robot agent with special-designed natural language map indexing in the bird's-in-eye view. Such indexing is instance-level and attribute-level. In particular, when integrated with a large language model, IVLMap demonstrates the capability to i) transform natural language into navigation targets with instance and attribute information, enabling precise localization, and ii) accomplish zero-shot end-to-end navigation tasks based on natural language commands. Extensive navigation experiments are conducted. Simulation results illustrate that our method can achieve an average improvement of 14.4\% in navigation accuracy. Code and demo are released at https://ivlmap.github.io/.
Attention Disturbance and Dual-Path Constraint Network for Occluded Person Re-Identification
Mar 20, 2023



Occluded person re-identification (Re-ID) aims to address the potential occlusion problem when matching occluded or holistic pedestrians from different camera views. Many methods use the background as artificial occlusion and rely on attention networks to exclude noisy interference. However, the significant discrepancy between simple background occlusion and realistic occlusion can negatively impact the generalization of the network.To address this issue, we propose a novel transformer-based Attention Disturbance and Dual-Path Constraint Network (ADP) to enhance the generalization of attention networks. Firstly, to imitate real-world obstacles, we introduce an Attention Disturbance Mask (ADM) module that generates an offensive noise, which can distract attention like a realistic occluder, as a more complex form of occlusion.Secondly, to fully exploit these complex occluded images, we develop a Dual-Path Constraint Module (DPC) that can obtain preferable supervision information from holistic images through dual-path interaction. With our proposed method, the network can effectively circumvent a wide variety of occlusions using the basic ViT baseline. Comprehensive experimental evaluations conducted on person re-ID benchmarks demonstrate the superiority of ADP over state-of-the-art methods.
OSIC: A New One-Stage Image Captioner Coined
Nov 04, 2022Mainstream image caption models are usually two-stage captioners, i.e., calculating object features by pre-trained detector, and feeding them into a language model to generate text descriptions. However, such an operation will cause a task-based information gap to decrease the performance, since the object features in detection task are suboptimal representation and cannot provide all necessary information for subsequent text generation. Besides, object features are usually represented by the last layer features that lose the local details of input images. In this paper, we propose a novel One-Stage Image Captioner (OSIC) with dynamic multi-sight learning, which directly transforms input image into descriptive sentences in one stage. As a result, the task-based information gap can be greatly reduced. To obtain rich features, we use the Swin Transformer to calculate multi-level features, and then feed them into a novel dynamic multi-sight embedding module to exploit both global structure and local texture of input images. To enhance the global modeling of encoder for caption, we propose a new dual-dimensional refining module to non-locally model the interaction of the embedded features. Finally, OSIC can obtain rich and useful information to improve the image caption task. Extensive comparisons on benchmark MS-COCO dataset verified the superior performance of our method.
Human Instance Segmentation and Tracking via Data Association and Single-stage Detector
Mar 31, 2022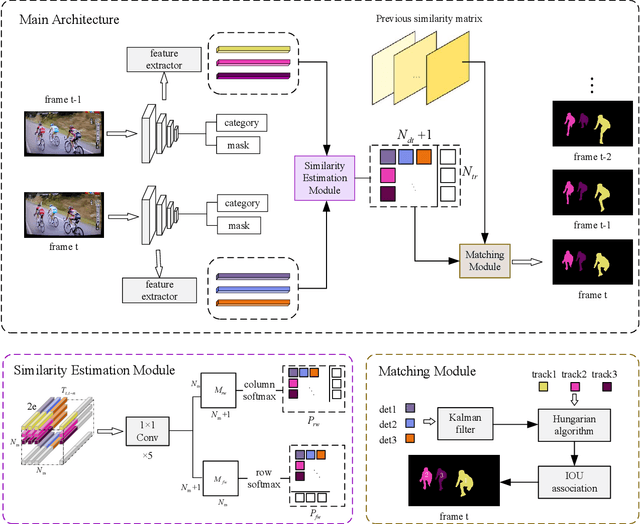


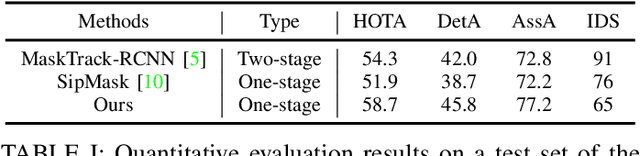
Human video instance segmentation plays an important role in computer understanding of human activities and is widely used in video processing, video surveillance, and human modeling in virtual reality. Most current VIS methods are based on Mask-RCNN framework, where the target appearance and motion information for data matching will increase computational cost and have an impact on segmentation real-time performance; on the other hand, the existing datasets for VIS focus less on all the people appearing in the video. In this paper, to solve the problems, we develop a new method for human video instance segmentation based on single-stage detector. To tracking the instance across the video, we have adopted data association strategy for matching the same instance in the video sequence, where we jointly learn target instance appearances and their affinities in a pair of video frames in an end-to-end fashion. We have also adopted the centroid sampling strategy for enhancing the embedding extraction ability of instance, which is to bias the instance position to the inside of each instance mask with heavy overlap condition. As a result, even there exists a sudden change in the character activity, the instance position will not move out of the mask, so that the problem that the same instance is represented by two different instances can be alleviated. Finally, we collect PVIS dataset by assembling several video instance segmentation datasets to fill the gap of the current lack of datasets dedicated to human video segmentation. Extensive simulations based on such dataset has been conduct. Simulation results verify the effectiveness and efficiency of the proposed work.
Arbitrary Virtual Try-On Network: Characteristics Preservation and Trade-off between Body and Clothing
Nov 24, 2021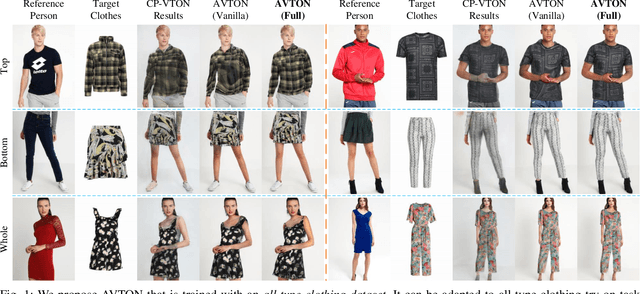
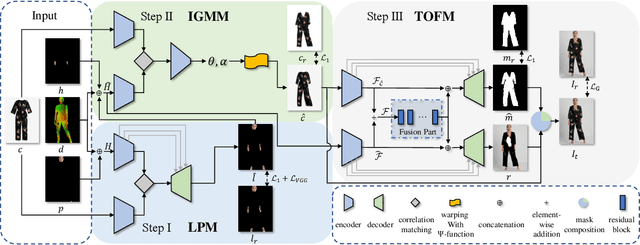


Deep learning based virtual try-on system has achieved some encouraging progress recently, but there still remain several big challenges that need to be solved, such as trying on arbitrary clothes of all types, trying on the clothes from one category to another and generating image-realistic results with few artifacts. To handle this issue, we in this paper first collect a new dataset with all types of clothes, \ie tops, bottoms, and whole clothes, each one has multiple categories with rich information of clothing characteristics such as patterns, logos, and other details. Based on this dataset, we then propose the Arbitrary Virtual Try-On Network (AVTON) that is utilized for all-type clothes, which can synthesize realistic try-on images by preserving and trading off characteristics of the target clothes and the reference person. Our approach includes three modules: 1) Limbs Prediction Module, which is utilized for predicting the human body parts by preserving the characteristics of the reference person. This is especially good for handling cross-category try-on task (\eg long sleeves \(\leftrightarrow\) short sleeves or long pants \(\leftrightarrow\) skirts, \etc), where the exposed arms or legs with the skin colors and details can be reasonably predicted; 2) Improved Geometric Matching Module, which is designed to warp clothes according to the geometry of the target person. We improve the TPS based warping method with a compactly supported radial function (Wendland's \(\Psi\)-function); 3) Trade-Off Fusion Module, which is to trade off the characteristics of the warped clothes and the reference person. This module is to make the generated try-on images look more natural and realistic based on a fine-tune symmetry of the network structure. Extensive simulations are conducted and our approach can achieve better performance compared with the state-of-the-art virtual try-on methods.
MFAGAN: A Compression Framework for Memory-Efficient On-Device Super-Resolution GAN
Jul 27, 2021
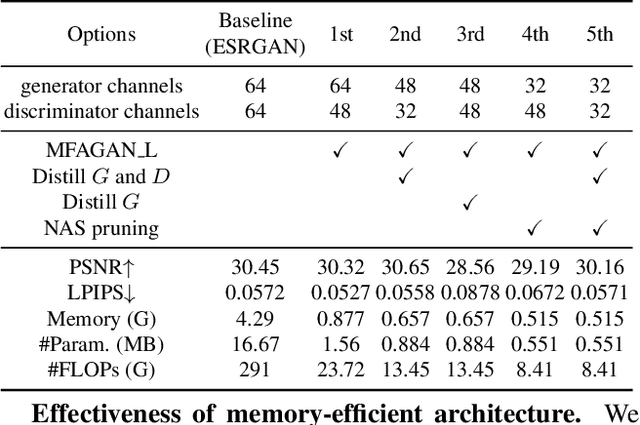
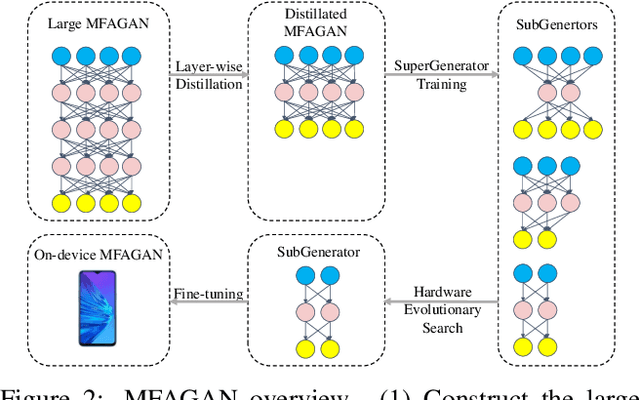

Generative adversarial networks (GANs) have promoted remarkable advances in single-image super-resolution (SR) by recovering photo-realistic images. However, high memory consumption of GAN-based SR (usually generators) causes performance degradation and more energy consumption, hindering the deployment of GAN-based SR into resource-constricted mobile devices. In this paper, we propose a novel compression framework \textbf{M}ulti-scale \textbf{F}eature \textbf{A}ggregation Net based \textbf{GAN} (MFAGAN) for reducing the memory access cost of the generator. First, to overcome the memory explosion of dense connections, we utilize a memory-efficient multi-scale feature aggregation net as the generator. Second, for faster and more stable training, our method introduces the PatchGAN discriminator. Third, to balance the student discriminator and the compressed generator, we distill both the generator and the discriminator. Finally, we perform a hardware-aware neural architecture search (NAS) to find a specialized SubGenerator for the target mobile phone. Benefiting from these improvements, the proposed MFAGAN achieves up to \textbf{8.3}$\times$ memory saving and \textbf{42.9}$\times$ computation reduction, with only minor visual quality degradation, compared with ESRGAN. Empirical studies also show $\sim$\textbf{70} milliseconds latency on Qualcomm Snapdragon 865 chipset.
EGGS: Eigen-Gap Guided Search Making Subspace Clustering Easy
Jul 27, 2021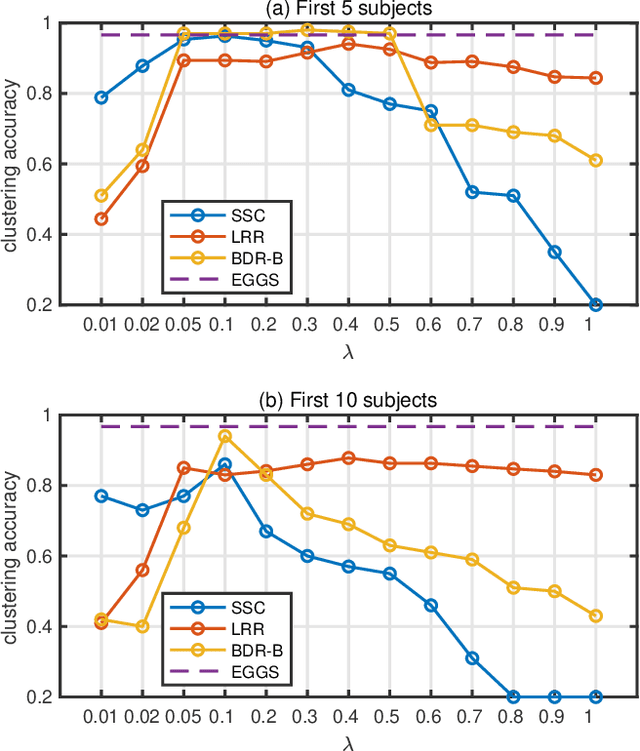
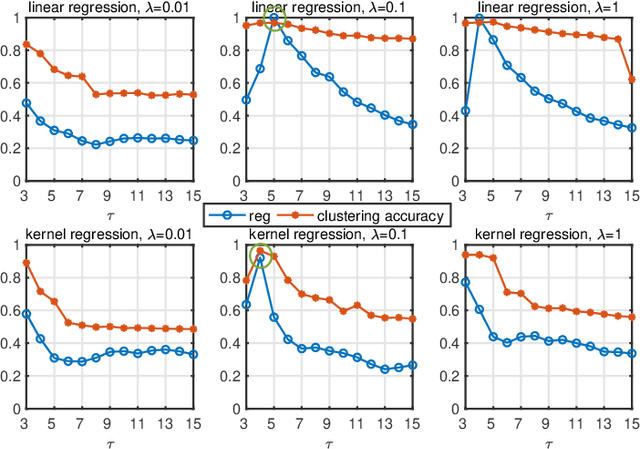
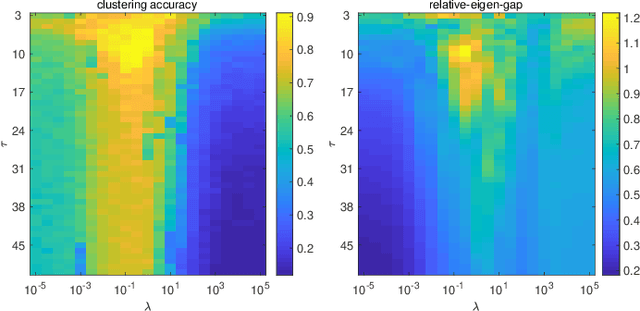
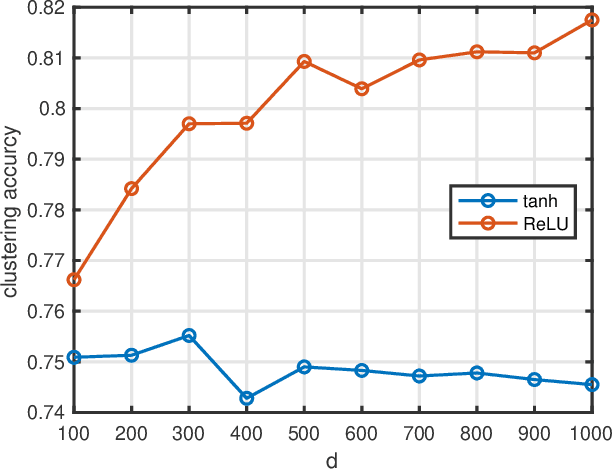
The performance of spectral clustering heavily relies on the quality of affinity matrix. A variety of affinity-matrix-construction methods have been proposed but they have hyper-parameters to determine beforehand, which requires strong experience and lead to difficulty in real applications especially when the inter-cluster similarity is high or/and the dataset is large. On the other hand, we often have to determine to use a linear model or a nonlinear model, which still depends on experience. To solve these two problems, in this paper, we present an eigen-gap guided search method for subspace clustering. The main idea is to find the most reliable affinity matrix among a set of candidates constructed by linear and kernel regressions, where the reliability is quantified by the \textit{relative-eigen-gap} of graph Laplacian defined in this paper. We show, theoretically and numerically, that the Laplacian matrix with a larger relative-eigen-gap often yields a higher clustering accuracy and stability. Our method is able to automatically search the best model and hyper-parameters in a pre-defined space. The search space is very easy to determine and can be arbitrarily large, though a relatively compact search space can reduce the highly unnecessary computation. Our method has high flexibility and convenience in real applications, and also has low computational cost because the affinity matrix is not computed by iterative optimization. We extend the method to large-scale datasets such as MNIST, on which the time cost is less than 90s and the clustering accuracy is state-of-the-art. Extensive experiments of natural image clustering show that our method is more stable, accurate, and efficient than baseline methods.
Semi-DerainGAN: A New Semi-supervised Single Image Deraining Network
Jan 23, 2020

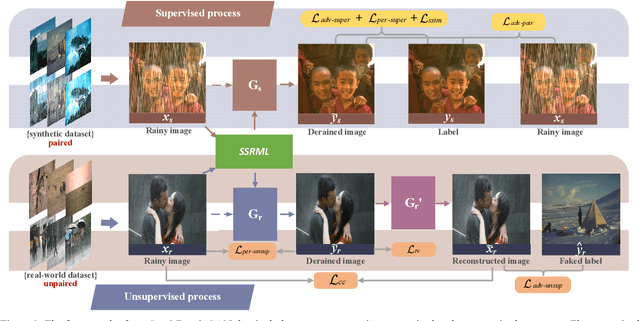
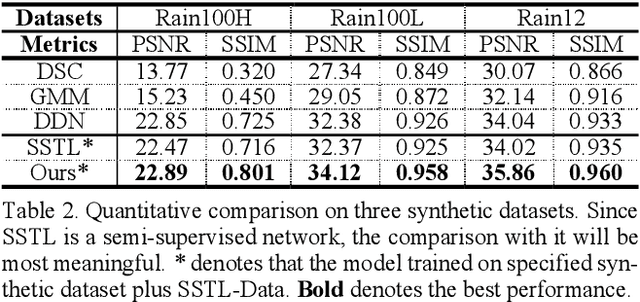
Removing the rain streaks from single image is still a challenging task, since the shapes and direc-tions of rain streaks in the synthetic datasets are very different from real images. Although super-vised deep deraining networks have obtained im-pressive results on synthetic datasets, they still cannot obtain satisfactory results on real images due to weak generalization of rain removal capac-ity, i.e., the pre-trained models usually cannot handle new shapes and directions that may lead to over-derained/under-derained results. In this paper, we propose a new semi-supervised GAN-based deraining network termed Semi-DerainGAN, which can use both synthetic and real rainy images in a uniform network using two supervised and unsupervised processes. Specifically, a semi-supervised rain streak learner termed SSRML sharing the same parameters of both processes is derived, which makes the real images contribute more rain streak information. To deliver better deraining results, we design a paired discriminator for distinguishing the real pairs from fake pairs. Note that we also contribute a new real-world rainy image dataset Real200 to alleviate the dif-ference between the synthetic and real image do-mains. Extensive results on public datasets show that our model can obtain competitive perfor-mance, especially on real images.