 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Matters: Motion-guided Modulation Network for Skeleton-based Micro-Action Recognition
Jul 29, 2025Micro-Actions (MAs) are an important form of non-verbal communication in social interactions, with potential applications in human emotional analysis. However, existing methods in Micro-Action Recognition often overlook the inherent subtle changes in MAs, which limits the accuracy of distinguishing MAs with subtle changes. To address this issue, we present a novel Motion-guided Modulation Network (MMN) that implicitly captures and modulates subtle motion cues to enhance spatial-temporal representation learning. Specifically, we introduce a Motion-guided Skeletal Modulation module (MSM) to inject motion cues at the skeletal level, acting as a control signal to guide spatial representation modeling. In parallel, we design a Motion-guided Temporal Modulation module (MTM) to incorporate motion information at the frame level, facilitating the modeling of holistic motion patterns in micro-actions. Finally, we propose a motion consistency learning strategy to aggregate the motion cues from multi-scale features for micro-action classification. Experimental results on the Micro-Action 52 and iMiGUE datasets demonstrate that MMN achieves state-of-the-art performance in skeleton-based micro-action recognition, underscoring the importance of explicitly modeling subtle motion cues. The code will be available at https://github.com/momiji-bit/MMN.
NTIRE 2025 Image Shadow Removal Challenge Report
Jun 18, 2025



This work examines the findings of the NTIRE 2025 Shadow Removal Challenge. A total of 306 participants have registered, with 17 teams successfully submitting their solutions during the final evaluation phase. Following the last two editions, this challenge had two evaluation tracks: one focusing on reconstruction fidelity and the other on visual perception through a user study. Both tracks were evaluated with images from the WSRD+ dataset, simulating interactions between self- and cast-shadows with a large number of diverse objects, textures, and materials.
The Tenth NTIRE 2025 Image Denoising Challenge Report
Apr 16, 2025



This paper presents an overview of the NTIRE 2025 Image Denoising Challenge ({\sigma} = 50), highlighting the proposed methodologies and corresponding results. The primary objective is to develop a network architecture capable of achieving high-quality denoising performance, quantitatively evaluated using PSNR, without constraints on computational complexity or model size. The task assumes independent additive white Gaussian noise (AWGN) with a fixed noise level of 50. A total of 290 participants registered for the challenge, with 20 teams successfully submitting valid results, providing insights into the current state-of-the-art in image denoising.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
Prompt to Restore, Restore to Prompt: Cyclic Prompting for Universal Adverse Weather Removal
Mar 12, 2025
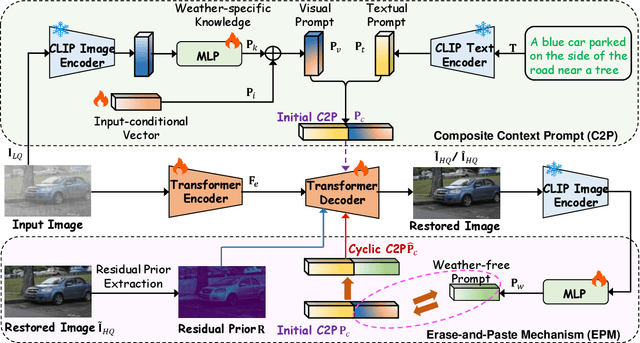
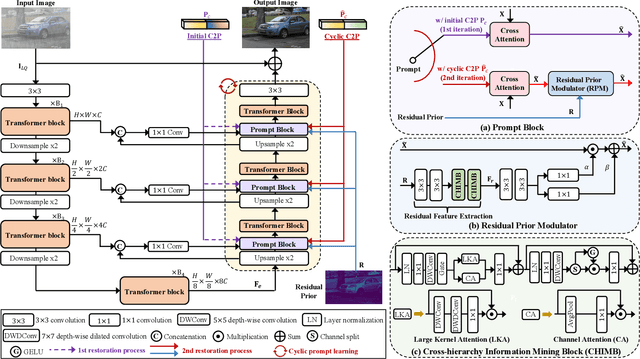

Universal adverse weather removal (UAWR) seeks to address various weather degradations within a unified framework. Recent methods are inspired by prompt learning using pre-trained vision-language models (e.g., CLIP), leveraging degradation-aware prompts to facilitate weather-free image restoration, yielding significant improvements. In this work, we propose CyclicPrompt, an innovative cyclic prompt approach designed to enhance the effectiveness, adaptability, and generalizability of UAWR. CyclicPrompt Comprises two key components: 1) a composite context prompt that integrates weather-related information and context-aware representations into the network to guide restoration. This prompt differs from previous methods by marrying learnable input-conditional vectors with weather-specific knowledge, thereby improving adaptability across various degradations. 2) The erase-and-paste mechanism, after the initial guided restoration, substitutes weather-specific knowledge with constrained restoration priors, inducing high-quality weather-free concepts into the composite prompt to further fine-tune the restoration process. Therefore, we can form a cyclic "Prompt-Restore-Prompt" pipeline that adeptly harnesses weather-specific knowledge, textual contexts, and reliable textures. Extensive experiments on synthetic and real-world datasets validate the superior performance of CyclicPrompt. The code is available at: https://github.com/RongxinL/CyclicPrompt.
Efficient Vision Language Model Fine-tuning for Text-based Person Anomaly Search
Feb 05, 2025



This paper presents the HFUT-LMC team's solution to the WWW 2025 challenge on Text-based Person Anomaly Search (TPAS). The primary objective of this challenge is to accurately identify pedestrians exhibiting either normal or abnormal behavior within a large library of pedestrian images. Unlike traditional video analysis tasks, TPAS significantly emphasizes understanding and interpreting the subtle relationships between text descriptions and visual data. The complexity of this task lies in the model's need to not only match individuals to text descriptions in massive image datasets but also accurately differentiate between search results when faced with similar descriptions. To overcome these challenges, we introduce the Similarity Coverage Analysis (SCA) strategy to address the recognition difficulty caused by similar text descriptions. This strategy effectively enhances the model's capacity to manage subtle differences, thus improving both the accuracy and reliability of the search. Our proposed solution demonstrated excellent performance in this challenge.
Exploiting Ensemble Learning for Cross-View Isolated Sign Language Recognition
Feb 04, 2025



In this paper, we present our solution to the Cross-View Isolated Sign Language Recognition (CV-ISLR) challenge held at WWW 2025. CV-ISLR addresses a critical issue in traditional Isolated Sign Language Recognition (ISLR), where existing datasets predominantly capture sign language videos from a frontal perspective, while real-world camera angles often vary. To accurately recognize sign language from different viewpoints, models must be capable of understanding gestures from multiple angles, making cross-view recognition challenging. To address this, we explore the advantages of ensemble learning, which enhances model robustness and generalization across diverse views. Our approach, built on a multi-dimensional Video Swin Transformer model, leverages this ensemble strategy to achieve competitive performance. Finally, our solution ranked 3rd in both the RGB-based ISLR and RGB-D-based ISLR tracks, demonstrating the effectiveness in handling the challenges of cross-view recognition. The code is available at: https://github.com/Jiafei127/CV_ISLR_WWW2025.
Temporal-Frequency State Space Duality: An Efficient Paradigm for Speech Emotion Recognition
Dec 22, 2024Speech Emotion Recognition (SER) plays a critical role in enhancing user experience within human-computer interaction. However, existing methods are overwhelmed by temporal domain analysis, overlooking the valuable envelope structures of the frequency domain that are equally important for robust emotion recognition. To overcome this limitation, we propose TF-Mamba, a novel multi-domain framework that captures emotional expressions in both temporal and frequency dimensions.Concretely, we propose a temporal-frequency mamba block to extract temporal- and frequency-aware emotional features, achieving an optimal balance between computational efficiency and model expressiveness. Besides, we design a Complex Metric-Distance Triplet (CMDT) loss to enable the model to capture representative emotional clues for SER. Extensive experiments on the IEMOCAP and MELD datasets show that TF-Mamba surpasses existing methods in terms of model size and latency, providing a more practical solution for future SER applications.
Sign-IDD: Iconicity Disentangled Diffusion for Sign Language Production
Dec 19, 2024



Sign Language Production (SLP) aims to generate semantically consistent sign videos from textual statements, where the conversion from textual glosses to sign poses (G2P) is a crucial step. Existing G2P methods typically treat sign poses as discrete three-dimensional coordinates and directly fit them, which overlooks the relative positional relationships among joints. To this end, we provide a new perspective, constraining joint associations and gesture details by modeling the limb bones to improve the accuracy and naturalness of the generated poses. In this work, we propose a pioneering iconicity disentangled diffusion framework, termed Sign-IDD, specifically designed for SLP. Sign-IDD incorporates a novel Iconicity Disentanglement (ID) module to bridge the gap between relative positions among joints. The ID module disentangles the conventional 3D joint representation into a 4D bone representation, comprising the 3D spatial direction vector and 1D spatial distance vector between adjacent joints. Additionally, an Attribute Controllable Diffusion (ACD) module is introduced to further constrain joint associations, in which the attribute separation layer aims to separate the bone direction and length attributes, and the attribute control layer is designed to guide the pose generation by leveraging the above attributes. The ACD module utilizes the gloss embeddings as semantic conditions and finally generates sign poses from noise embeddings. Extensive experiments on PHOENIX14T and USTC-CSL datasets validate the effectiveness of our method. The code is available at: https://github.com/NaVi-start/Sign-IDD.
Micro-gesture Online Recognition using Learnable Query Points
Jul 05, 2024In this paper, we briefly introduce the solution developed by our team, HFUT-VUT, for the Micro-gesture Online Recognition track in the MiGA challenge at IJCAI 2024. The Micro-gesture Online Recognition task involves identifying the category and locating the start and end times of micro-gestures in video clips. Compared to the typical Temporal Action Detection task, the Micro-gesture Online Recognition task focuses more on distinguishing between micro-gestures and pinpointing the start and end times of actions. Our solution ranks 2nd in the Micro-gesture Online Recognition track.