 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCanonSLR: Canonical-View Guided Multi-View Continuous Sign Language Recognition
Apr 20, 2026Continuous Sign Language Recognition (CSLR) has achieved remarkable progress in recent years; however, most existing methods are developed under single-view settings and thus remain insufficiently robust to viewpoint variations in real-world scenarios. To address this limitation, we propose CanonSLR, a canonical-view guided framework for multi-view CSLR. Specifically, we introduce a frontal-view-anchored teacher-student learning strategy, in which a teacher network trained on frontal-view data provides canonical temporal supervision for a student network trained on all viewpoints. To further reduce cross-view semantic discrepancy, we propose Sequence-Level Soft-Target Distillation, which transfers structured temporal knowledge from the frontal view to non-frontal samples, thereby alleviating gloss boundary ambiguity and category confusion caused by occlusion and projection variation. In addition, we introduce Temporal Motion Relational Enhancement to explicitly model motion-aware temporal relations in high-level visual features, strengthening stable dynamic representations while suppressing viewpoint-sensitive appearance disturbances. To support multi-view CSLR research, we further develop a universal multi-view sign language data construction pipeline that transforms original single-view RGB videos into semantically consistent, temporally coherent, and viewpoint-controllable multi-view sign language videos. Based on this pipeline, we extend PHOENIX-2014T and CSL-Daily into two seven-view benchmarks, namely PT14-MV and CSL-MV, providing a new experimental foundation for multi-view CSLR. Extensive experiments on PT14-MV and CSL-MV demonstrate that CanonSLR consistently outperforms existing approaches under multi-view settings and exhibits stronger robustness, especially on challenging non-frontal views.
OmniVL-Guard: Towards Unified Vision-Language Forgery Detection and Grounding via Balanced RL
Feb 12, 2026Existing forgery detection methods are often limited to uni-modal or bi-modal settings, failing to handle the interleaved text, images, and videos prevalent in real-world misinformation. To bridge this gap, this paper targets to develop a unified framework for omnibus vision-language forgery detection and grounding. In this unified setting, the {interplay} between diverse modalities and the dual requirements of simultaneous detection and localization pose a critical ``difficulty bias`` problem: the simpler veracity classification task tends to dominate the gradients, leading to suboptimal performance in fine-grained grounding during multi-task optimization. To address this challenge, we propose \textbf{OmniVL-Guard}, a balanced reinforcement learning framework for omnibus vision-language forgery detection and grounding. Particularly, OmniVL-Guard comprises two core designs: Self-Evolving CoT Generatio and Adaptive Reward Scaling Policy Optimization (ARSPO). {Self-Evolving CoT Generation} synthesizes high-quality reasoning paths, effectively overcoming the cold-start challenge. Building upon this, {Adaptive Reward Scaling Policy Optimization (ARSPO)} dynamically modulates reward scales and task weights, ensuring a balanced joint optimization. Extensive experiments demonstrate that OmniVL-Guard significantly outperforms state-of-the-art methods and exhibits zero-shot robust generalization across out-of-domain scenarios.
Accelerating Controllable Generation via Hybrid-grained Cache
Nov 14, 2025Controllable generative models have been widely used to improve the realism of synthetic visual content. However, such models must handle control conditions and content generation computational requirements, resulting in generally low generation efficiency. To address this issue, we propose a Hybrid-Grained Cache (HGC) approach that reduces computational overhead by adopting cache strategies with different granularities at different computational stages. Specifically, (1) we use a coarse-grained cache (block-level) based on feature reuse to dynamically bypass redundant computations in encoder-decoder blocks between each step of model reasoning. (2) We design a fine-grained cache (prompt-level) that acts within a module, where the fine-grained cache reuses cross-attention maps within consecutive reasoning steps and extends them to the corresponding module computations of adjacent steps. These caches of different granularities can be seamlessly integrated into each computational link of the controllable generation process. We verify the effectiveness of HGC on four benchmark datasets, especially its advantages in balancing generation efficiency and visual quality. For example, on the COCO-Stuff segmentation benchmark, our HGC significantly reduces the computational cost (MACs) by 63% (from 18.22T to 6.70T), while keeping the loss of semantic fidelity (quantized performance degradation) within 1.5%.
Open-World 3D Scene Graph Generation for Retrieval-Augmented Reasoning
Nov 08, 2025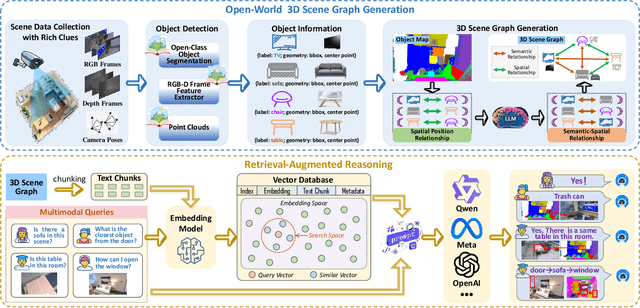

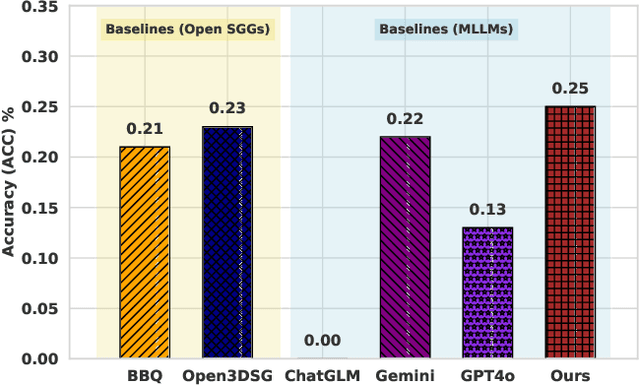
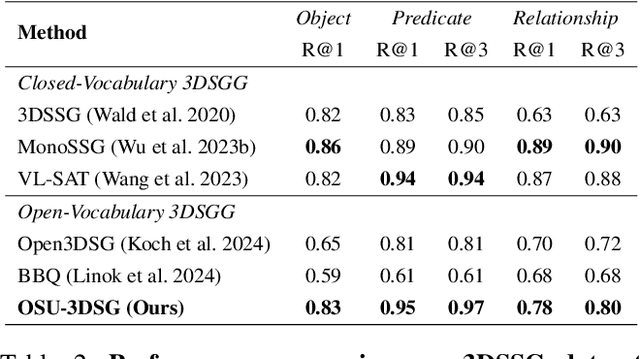
Understanding 3D scenes in open-world settings poses fundamental challenges for vision and robotics, particularly due to the limitations of closed-vocabulary supervision and static annotations. To address this, we propose a unified framework for Open-World 3D Scene Graph Generation with Retrieval-Augmented Reasoning, which enables generalizable and interactive 3D scene understanding. Our method integrates Vision-Language Models (VLMs) with retrieval-based reasoning to support multimodal exploration and language-guided interaction. The framework comprises two key components: (1) a dynamic scene graph generation module that detects objects and infers semantic relationships without fixed label sets, and (2) a retrieval-augmented reasoning pipeline that encodes scene graphs into a vector database to support text/image-conditioned queries. We evaluate our method on 3DSSG and Replica benchmarks across four tasks-scene question answering, visual grounding, instance retrieval, and task planning-demonstrating robust generalization and superior performance in diverse environments. Our results highlight the effectiveness of combining open-vocabulary perception with retrieval-based reasoning for scalable 3D scene understanding.
SLRTP2025 Sign Language Production Challenge: Methodology, Results, and Future Work
Aug 09, 2025Sign Language Production (SLP) is the task of generating sign language video from spoken language inputs. The field has seen a range of innovations over the last few years, with the introduction of deep learning-based approaches providing significant improvements in the realism and naturalness of generated outputs. However, the lack of standardized evaluation metrics for SLP approaches hampers meaningful comparisons across different systems. To address this, we introduce the first Sign Language Production Challenge, held as part of the third SLRTP Workshop at CVPR 2025. The competition's aims are to evaluate architectures that translate from spoken language sentences to a sequence of skeleton poses, known as Text-to-Pose (T2P) translation, over a range of metrics. For our evaluation data, we use the RWTH-PHOENIX-Weather-2014T dataset, a German Sign Language - Deutsche Gebardensprache (DGS) weather broadcast dataset. In addition, we curate a custom hidden test set from a similar domain of discourse. This paper presents the challenge design and the winning methodologies. The challenge attracted 33 participants who submitted 231 solutions, with the top-performing team achieving BLEU-1 scores of 31.40 and DTW-MJE of 0.0574. The winning approach utilized a retrieval-based framework and a pre-trained language model. As part of the workshop, we release a standardized evaluation network, including high-quality skeleton extraction-based keypoints establishing a consistent baseline for the SLP field, which will enable future researchers to compare their work against a broader range of methods.
Motion is the Choreographer: Learning Latent Pose Dynamics for Seamless Sign Language Generation
Aug 06, 2025Sign language video generation requires producing natural signing motions with realistic appearances under precise semantic control, yet faces two critical challenges: excessive signer-specific data requirements and poor generalization. We propose a new paradigm for sign language video generation that decouples motion semantics from signer identity through a two-phase synthesis framework. First, we construct a signer-independent multimodal motion lexicon, where each gloss is stored as identity-agnostic pose, gesture, and 3D mesh sequences, requiring only one recording per sign. This compact representation enables our second key innovation: a discrete-to-continuous motion synthesis stage that transforms retrieved gloss sequences into temporally coherent motion trajectories, followed by identity-aware neural rendering to produce photorealistic videos of arbitrary signers. Unlike prior work constrained by signer-specific datasets, our method treats motion as a first-class citizen: the learned latent pose dynamics serve as a portable "choreography layer" that can be visually realized through different human appearances. Extensive experiments demonstrate that disentangling motion from identity is not just viable but advantageous - enabling both high-quality synthesis and unprecedented flexibility in signer personalization.
SplitGaussian: Reconstructing Dynamic Scenes via Visual Geometry Decomposition
Aug 06, 2025



Reconstructing dynamic 3D scenes from monocular video remains fundamentally challenging due to the need to jointly infer motion, structure, and appearance from limited observations. Existing dynamic scene reconstruction methods based on Gaussian Splatting often entangle static and dynamic elements in a shared representation, leading to motion leakage, geometric distortions, and temporal flickering. We identify that the root cause lies in the coupled modeling of geometry and appearance across time, which hampers both stability and interpretability. To address this, we propose \textbf{SplitGaussian}, a novel framework that explicitly decomposes scene representations into static and dynamic components. By decoupling motion modeling from background geometry and allowing only the dynamic branch to deform over time, our method prevents motion artifacts in static regions while supporting view- and time-dependent appearance refinement. This disentangled design not only enhances temporal consistency and reconstruction fidelity but also accelerates convergence. Extensive experiments demonstrate that SplitGaussian outperforms prior state-of-the-art methods in rendering quality, geometric stability, and motion separation.
StgcDiff: Spatial-Temporal Graph Condition Diffusion for Sign Language Transition Generation
Jun 16, 2025Sign language transition generation seeks to convert discrete sign language segments into continuous sign videos by synthesizing smooth transitions. However,most existing methods merely concatenate isolated signs, resulting in poor visual coherence and semantic accuracy in the generated videos. Unlike textual languages,sign language is inherently rich in spatial-temporal cues, making it more complex to model. To address this,we propose StgcDiff, a graph-based conditional diffusion framework that generates smooth transitions between discrete signs by capturing the unique spatial-temporal dependencies of sign language. Specifically, we first train an encoder-decoder architecture to learn a structure-aware representation of spatial-temporal skeleton sequences. Next, we optimize a diffusion denoiser conditioned on the representations learned by the pre-trained encoder, which is tasked with predicting transition frames from noise. Additionally, we design the Sign-GCN module as the key component in our framework, which effectively models the spatial-temporal features. Extensive experiments conducted on the PHOENIX14T, USTC-CSL100,and USTC-SLR500 datasets demonstrate the superior performance of our method.
Towards Fine-Grained Emotion Understanding via Skeleton-Based Micro-Gesture Recognition
Jun 15, 2025We present our solution to the MiGA Challenge at IJCAI 2025, which aims to recognize micro-gestures (MGs) from skeleton sequences for the purpose of hidden emotion understanding. MGs are characterized by their subtlety, short duration, and low motion amplitude, making them particularly challenging to model and classify. We adopt PoseC3D as the baseline framework and introduce three key enhancements: (1) a topology-aware skeleton representation specifically designed for the iMiGUE dataset to better capture fine-grained motion patterns; (2) an improved temporal processing strategy that facilitates smoother and more temporally consistent motion modeling; and (3) the incorporation of semantic label embeddings as auxiliary supervision to improve the model generalization. Our method achieves a Top-1 accuracy of 67.01\% on the iMiGUE test set. As a result of these contributions, our approach ranks third on the official MiGA Challenge leaderboard. The source code is available at \href{https://github.com/EGO-False-Sleep/Miga25_track1}{https://github.com/EGO-False-Sleep/Miga25\_track1}.
Wi-CBR: WiFi-based Cross-domain Behavior Recognition via Multimodal Collaborative Awareness
Jun 13, 2025WiFi-based human behavior recognition aims to recognize gestures and activities by analyzing wireless signal variations. However, existing methods typically focus on a single type of data, neglecting the interaction and fusion of multiple features. To this end, we propose a novel multimodal collaborative awareness method. By leveraging phase data reflecting changes in dynamic path length and Doppler Shift (DFS) data corresponding to frequency changes related to the speed of gesture movement, we enable efficient interaction and fusion of these features to improve recognition accuracy. Specifically, we first introduce a dual-branch self-attention module to capture spatial-temporal cues within each modality. Then, a group attention mechanism is applied to the concatenated phase and DFS features to mine key group features critical for behavior recognition. Through a gating mechanism, the combined features are further divided into PD-strengthen and PD-weaken branches, optimizing information entropy and promoting cross-modal collaborative awareness. Extensive in-domain and cross-domain experiments on two large publicly available datasets, Widar3.0 and XRF55, demonstrate the superior performance of our method.