 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTri-Efficient Transfer Learning for Point Cloud Videos
Jun 23, 2026While point cloud foundation models have significantly advanced point cloud video understanding, existing parameter-efficient fine-tuning (PEFT) methods still suffer from two critical limitations: prohibitive annotation costs for large-scale point cloud datasets and severe memory bottlenecks. In this paper, we aim to mine richer supervision signals from existing data rather than blindly scaling datasets. A further key principle is that the memory footprint of fine-tuning must be drastically reduced compared to full fine-tuning, which remains elusive for current PEFT techniques. Driven by these challenges, we identify three core desiderata: data-, parameter-, and memory efficiency, and present PoinTriE, a unified framework that excels along all three dimensions. For pre-training, pseudo-motion trajectories are synthesized via rigid transformations, paired with text corpora and 2D projections derived from raw point clouds. We then propose a Geometric-Motion Duality Network optimized via multimodal contrastive learning, rigid rotation prediction, and motion distribution divergence to produce dense self-supervision. During fine-tuning, we freeze the pretrained backbone and only update a lightweight Spatio-temporal Side Network built with LoRA units. Equipped with a gradient flow masking strategy, PoinTriE simultaneously reduces memory consumption and parameter overhead. Extensive experiments confirm that PoinTriE establishes new state-of-the-art results on action recognition and semantic segmentation tasks.
Orchestrated Reality: From Role-Play to Living, Playable Game Worlds -- LLM-Driven World Simulation as a Parameterized-Action POMDP
Jun 14, 2026Many games rely on storytelling combined with systems that track levelling, NPC behaviour, and consequence simulation; bridging tightly-authored narrative with deeply-simulated worlds -- most acute in sandbox and open-world settings -- has been prohibitively expensive. LLM-driven worlds open a new path: a single harness can coordinate numerical state, narrative voice, storytelling pacing, and rule logic together. Realising this requires the LLM system to sustain a persistent world (who is where, what has just happened, what is currently true), which today's deployed systems do not: the narrative voice asserts state in free prose without any validated representation, so a fully autonomous game engine remains infeasible. We treat this as an architectural choice, not a limitation of language models, and report work in progress on a framework -- orchestrated reality -- that makes the world a canonical object owned by a singleton orchestration agent analogous to the tabletop-RPG Game Master (GM). We formalise an LLM-driven game world for a human player as a Parameterized-Action POMDP: state is a tree of canonical JSON entities, actions decompose as $a=(k, x_k)$ (a discrete intent kind plus structured JSON parameters), the agent observes only a narrative projection $o=O(s)$ of state, and the transition kernel $F$ is an LLM-driven Plan-Diff-Validate-Apply (PDVA) pipeline that commits schema-validated, content-hashed JSON deltas. We give the formal model, a JSON-state example, a worked single-turn example, and a catalogue of 15 illustrative incidents drawn from a real deployment showing the framework in action. Empirical validation through a planned human player study -- together with multi-NPC concurrent agency and deployment as an RL environment -- is situated as future work.
Diffusion Masked Pretraining for Dynamic Point Cloud
May 05, 2026Dynamic point cloud pretraining is still dominated by masked reconstruction objectives. However, these objectives inherit two key limitations. Existing methods inject ground-truth tube centers as decoder positional embeddings, causing spatio-temporal positional leakage. Moreover, they supervise inter-frame motion with deterministic proxy targets that systematically discard distributional structure by collapsing multimodal trajectory uncertainty into conditional means. To address these limitations, we propose Diffusion Masked Pretraining (DiMP), a unified self-supervised framework for dynamic point clouds. DiMP introduces diffusion modeling into both positional inference and motion learning. It first applies forward diffusion noise only to masked tube centers, then predicts clean centers from visible spatio-temporal context. This removes positional leakage while preserving visible coordinates as clean temporal anchors. DiMP also reformulates point-wise inter-frame displacement supervision as a DDPM noise-prediction objective conditioned on decoded representations. This design drives the encoder to target the full conditional distribution of plausible motions under a variational surrogate, rather than collapsing to a single deterministic estimate. Extensive experiments demonstrate that DiMP consistently improves downstream accuracy over the backbone alone, with absolute gains of 11.21% on offline action segmentation and 13.65% under causally constrained online inference.Codes are available at https://github.com/InitalZ/DiMP.git.
PointCoT: A Multi-modal Benchmark for Explicit 3D Geometric Reasoning
Feb 27, 2026While Multimodal Large Language Models (MLLMs) demonstrate proficiency in 2D scenes, extending their perceptual intelligence to 3D point cloud understanding remains a significant challenge. Current approaches focus primarily on aligning 3D features with pre-trained models. However, they typically treat geometric reasoning as an implicit mapping process. These methods bypass intermediate logical steps and consequently suffer from geometric hallucinations. They confidently generate plausible responses that fail to ground in precise structural details. To bridge this gap, we present PointCoT, a novel framework that empowers MLLMs with explicit Chain-of-Thought (CoT) reasoning for 3D data. We advocate for a \textit{Look, Think, then Answer} paradigm. In this approach, the model is supervised to generate geometry-grounded rationales before predicting final answers. To facilitate this, we construct Point-Reason-Instruct, a large-scale benchmark comprising $\sim$86k instruction-tuning samples with hierarchical CoT annotations. By leveraging a dual-stream multi-modal architecture, our method synergizes semantic appearance with geometric truth. Extensive experiments demonstrate that PointCoT achieves state-of-the-art performance on complex reasoning tasks.
Bridging Knowledge Gap Between Image Inpainting and Large-Area Visible Watermark Removal
Apr 07, 2025Visible watermark removal which involves watermark cleaning and background content restoration is pivotal to evaluate the resilience of watermarks. Existing deep neural network (DNN)-based models still struggle with large-area watermarks and are overly dependent on the quality of watermark mask prediction. To overcome these challenges, we introduce a novel feature adapting framework that leverages the representation modeling capacity of a pre-trained image inpainting model. Our approach bridges the knowledge gap between image inpainting and watermark removal by fusing information of the residual background content beneath watermarks into the inpainting backbone model. We establish a dual-branch system to capture and embed features from the residual background content, which are merged into intermediate features of the inpainting backbone model via gated feature fusion modules. Moreover, for relieving the dependence on high-quality watermark masks, we introduce a new training paradigm by utilizing coarse watermark masks to guide the inference process. This contributes to a visible image removal model which is insensitive to the quality of watermark mask during testing. Extensive experiments on both a large-scale synthesized dataset and a real-world dataset demonstrate that our approach significantly outperforms existing state-of-the-art methods. The source code is available in the supplementary materials.
Navigating Semantic Drift in Task-Agnostic Class-Incremental Learning
Feb 11, 2025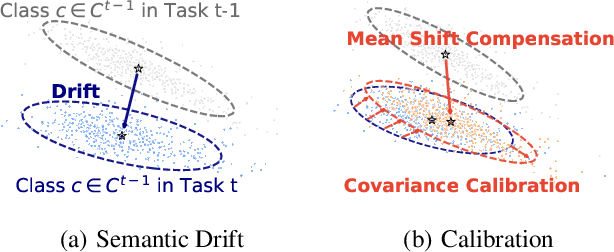
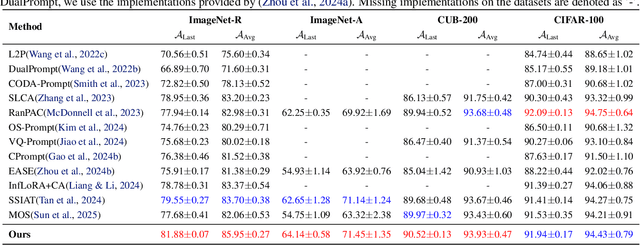
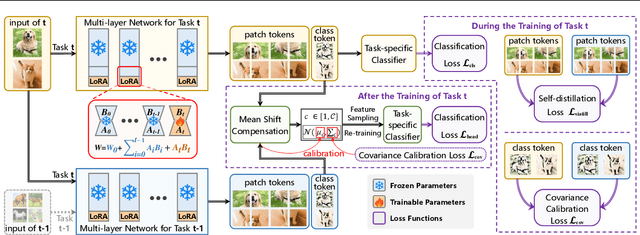
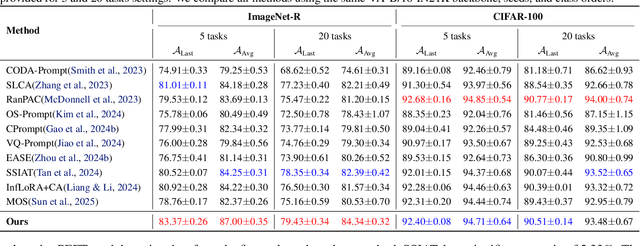
Class-incremental learning (CIL) seeks to enable a model to sequentially learn new classes while retaining knowledge of previously learned ones. Balancing flexibility and stability remains a significant challenge, particularly when the task ID is unknown. To address this, our study reveals that the gap in feature distribution between novel and existing tasks is primarily driven by differences in mean and covariance moments. Building on this insight, we propose a novel semantic drift calibration method that incorporates mean shift compensation and covariance calibration. Specifically, we calculate each class's mean by averaging its sample embeddings and estimate task shifts using weighted embedding changes based on their proximity to the previous mean, effectively capturing mean shifts for all learned classes with each new task. We also apply Mahalanobis distance constraint for covariance calibration, aligning class-specific embedding covariances between old and current networks to mitigate the covariance shift. Additionally, we integrate a feature-level self-distillation approach to enhance generalization. Comprehensive experiments on commonly used datasets demonstrate the effectiveness of our approach. The source code is available at \href{https://github.com/fwu11/MACIL.git}{https://github.com/fwu11/MACIL.git}.
Diffusion-based Layer-wise Semantic Reconstruction for Unsupervised Out-of-Distribution Detection
Nov 16, 2024Unsupervised out-of-distribution (OOD) detection aims to identify out-of-domain data by learning only from unlabeled In-Distribution (ID) training samples, which is crucial for developing a safe real-world machine learning system. Current reconstruction-based methods provide a good alternative approach by measuring the reconstruction error between the input and its corresponding generative counterpart in the pixel/feature space. However, such generative methods face a key dilemma: improving the reconstruction power of the generative model while keeping a compact representation of the ID data. To address this issue, we propose the diffusion-based layer-wise semantic reconstruction approach for unsupervised OOD detection. The innovation of our approach is that we leverage the diffusion model's intrinsic data reconstruction ability to distinguish ID samples from OOD samples in the latent feature space. Moreover, to set up a comprehensive and discriminative feature representation, we devise a multi-layer semantic feature extraction strategy. By distorting the extracted features with Gaussian noise and applying the diffusion model for feature reconstruction, the separation of ID and OOD samples is implemented according to the reconstruction errors. Extensive experimental results on multiple benchmarks built upon various datasets demonstrate that our method achieves state-of-the-art performance in terms of detection accuracy and speed. Code is available at <https://github.com/xbyym/DLSR>.
* 26 pages, 23 figures, published to Neurlps2024
Progressive Conservative Adaptation for Evolving Target Domains
Feb 07, 2024Conventional domain adaptation typically transfers knowledge from a source domain to a stationary target domain. However, in many real-world cases, target data usually emerge sequentially and have continuously evolving distributions. Restoring and adapting to such target data results in escalating computational and resource consumption over time. Hence, it is vital to devise algorithms to address the evolving domain adaptation (EDA) problem, \emph{i.e.,} adapting models to evolving target domains without access to historic target domains. To achieve this goal, we propose a simple yet effective approach, termed progressive conservative adaptation (PCAda). To manage new target data that diverges from previous distributions, we fine-tune the classifier head based on the progressively updated class prototypes. Moreover, as adjusting to the most recent target domain can interfere with the features learned from previous target domains, we develop a conservative sparse attention mechanism. This mechanism restricts feature adaptation within essential dimensions, thus easing the inference related to historical knowledge. The proposed PCAda is implemented with a meta-learning framework, which achieves the fast adaptation of the classifier with the help of the progressively updated class prototypes in the inner loop and learns a generalized feature without severely interfering with the historic knowledge via the conservative sparse attention in the outer loop. Experiments on Rotated MNIST, Caltran, and Portraits datasets demonstrate the effectiveness of our method.
Revisiting the Power of Prompt for Visual Tuning
Feb 04, 2024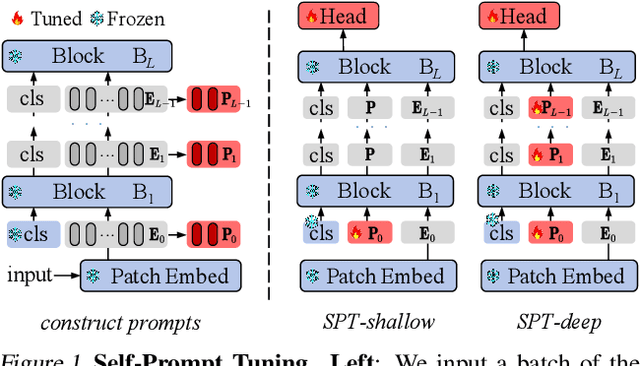
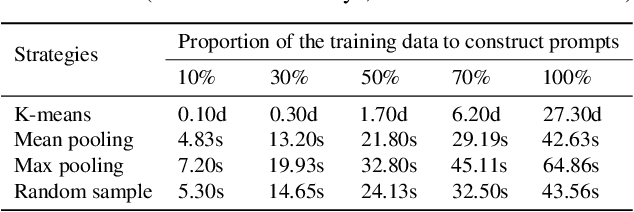
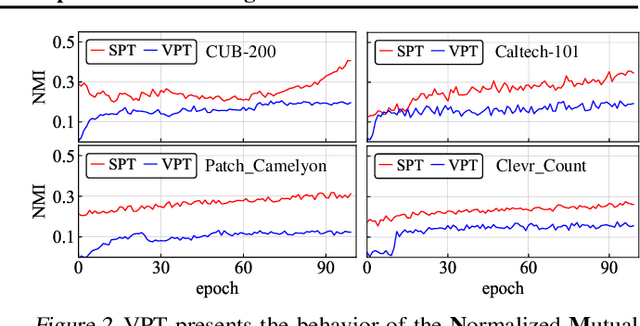
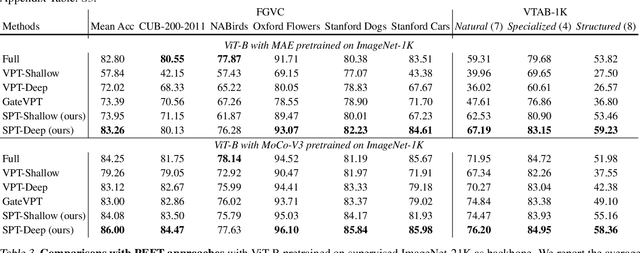
Visual prompt tuning (VPT) is a promising solution incorporating learnable prompt tokens to customize pre-trained models for downstream tasks. However, VPT and its variants often encounter challenges like prompt initialization, prompt length, and subpar performance in self-supervised pretraining, hindering successful contextual adaptation. This study commences by exploring the correlation evolvement between prompts and patch tokens during proficient training. Inspired by the observation that the prompt tokens tend to share high mutual information with patch tokens, we propose initializing prompts with downstream token prototypes. The strategic initialization, a stand-in for the previous initialization, substantially improves performance in fine-tuning. To refine further, we optimize token construction with a streamlined pipeline that maintains excellent performance with almost no increase in computational expenses compared to VPT. Exhaustive experiments show our proposed approach outperforms existing methods by a remarkable margin. For instance, it surpasses full fine-tuning in 19 out of 24 tasks, using less than 0.4% of learnable parameters on the FGVC and VTAB-1K benchmarks. Notably, our method significantly advances the adaptation for self-supervised pretraining, achieving impressive task performance gains of at least 10% to 30%. Besides, the experimental results demonstrate the proposed SPT is robust to prompt lengths and scales well with model capacity and training data size. We finally provide an insightful exploration into the amount of target data facilitating the adaptation of pre-trained models to downstream tasks.
Removing Interference and Recovering Content Imaginatively for Visible Watermark Removal
Dec 22, 2023Visible watermarks, while instrumental in protecting image copyrights, frequently distort the underlying content, complicating tasks like scene interpretation and image editing. Visible watermark removal aims to eliminate the interference of watermarks and restore the background content. However, existing methods often implement watermark component removal and background restoration tasks within a singular branch, leading to residual watermarks in the predictions and ignoring cases where watermarks heavily obscure the background. To address these limitations, this study introduces the Removing Interference and Recovering Content Imaginatively (RIRCI) framework. RIRCI embodies a two-stage approach: the initial phase centers on discerning and segregating the watermark component, while the subsequent phase focuses on background content restoration. To achieve meticulous background restoration, our proposed model employs a dual-path network capable of fully exploring the intrinsic background information beneath semi-transparent watermarks and peripheral contextual information from unaffected regions. Moreover, a Global and Local Context Interaction module is built upon multi-layer perceptrons and bidirectional feature transformation for comprehensive representation modeling in the background restoration phase. The efficacy of our approach is empirically validated across two large-scale datasets, and our findings reveal a marked enhancement over existing watermark removal techniques.