 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultinex: Lightweight Low-light Image Enhancement via Multi-prior Retinex
Apr 11, 2026Low-light image enhancement (LLIE) aims to restore natural visibility, color fidelity, and structural detail under severe illumination degradation. State-of-the-art (SOTA) LLIE techniques often rely on large models and multi-stage training, limiting practicality for edge deployment. Moreover, their dependence on a single color space introduces instability and visible exposure or color artifacts. To address these, we propose Multinex, an ultra-lightweight structured framework that integrates multiple fine-grained representations within a principled Retinex residual formulation. It decomposes an image into illumination and color prior stacks derived from distinct analytic representations, and learns to fuse these representations into luminance and reflectance adjustments required to correct exposure. By prioritizing enhancement over reconstruction and exploiting lightweight neural operations, Multinex significantly reduces computational cost, exemplified by its lightweight (45K parameters) and nano (0.7K parameters) versions. Extensive benchmarks show that all lightweight variants significantly outperform their corresponding lightweight SOTA models, and reach comparable performance to heavy models. Paper page available at https://albrateanu.github.io/multinex.
A Theory of Random Graph Shift in Truncated-Spectrum vRKHS
Feb 27, 2026This paper develops a theory of graph classification under domain shift through a random-graph generative lens, where we consider intra-class graphs sharing the same random graph model (RGM) and the domain shift induced by changes in RGM components. While classic domain adaptation (DA) theories have well-underpinned existing techniques to handle graph distribution shift, the information of graph samples, which are itself structured objects, is less explored. The non-Euclidean nature of graphs and specialized architectures for graph learning further complicate a fine-grained analysis of graph distribution shifts. In this paper, we propose a theory that assumes RGM as the data generative process, exploiting its connection to hypothesis complexity in function space perspective for such fine-grained analysis. Building on a vector-valued reproducing kernel Hilbert space (vRKHS) formulation, we derive a generalization bound whose shift penalty admits a factorization into (i) a domain discrepancy term, (ii) a spectral-geometry term summarized by the accessible truncated spectrum, and (iii) an amplitude term that aggregates convergence and construction-stability effects. We empirically verify the insights on these terms in both real data and simulations.
Group-Agent Reinforcement Learning with Heterogeneous Agents
Jan 21, 2025



Group-agent reinforcement learning (GARL) is a newly arising learning scenario, where multiple reinforcement learning agents study together in a group, sharing knowledge in an asynchronous fashion. The goal is to improve the learning performance of each individual agent. Under a more general heterogeneous setting where different agents learn using different algorithms, we advance GARL by designing novel and effective group-learning mechanisms. They guide the agents on whether and how to learn from action choices from the others, and allow the agents to adopt available policy and value function models sent by another agent if they perform better. We have conducted extensive experiments on a total of 43 different Atari 2600 games to demonstrate the superior performance of the proposed method. After the group learning, among the 129 agents examined, 96% are able to achieve a learning speed-up, and 72% are able to learn over 100 times faster. Also, around 41% of those agents have achieved a higher accumulated reward score by learning in less than 5% of the time steps required by a single agent when learning on its own.
Precise, Fast, and Low-cost Concept Erasure in Value Space: Orthogonal Complement Matters
Dec 09, 2024

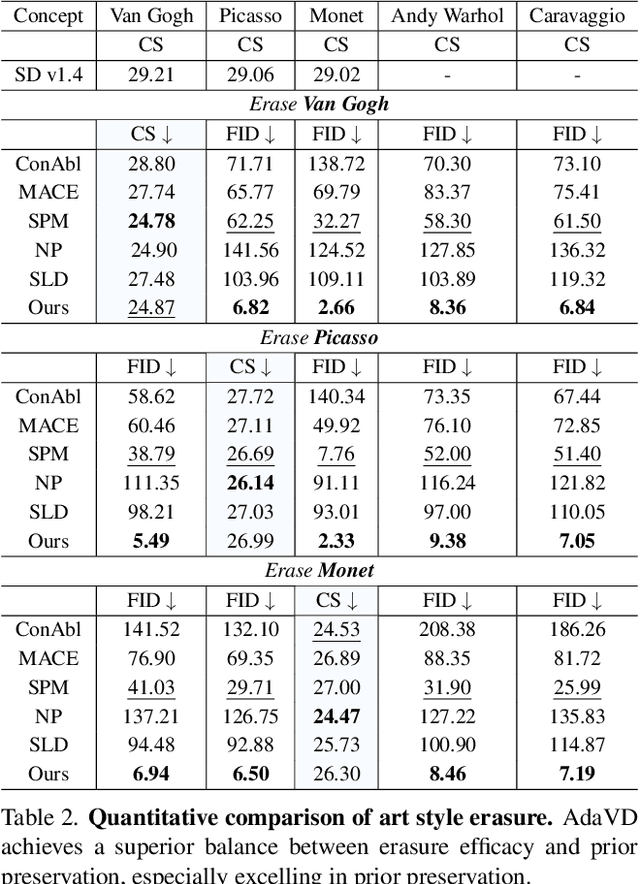

The success of text-to-image generation enabled by diffuion models has imposed an urgent need to erase unwanted concepts, e.g., copyrighted, offensive, and unsafe ones, from the pre-trained models in a precise, timely, and low-cost manner. The twofold demand of concept erasure requires a precise removal of the target concept during generation (i.e., erasure efficacy), while a minimal impact on non-target content generation (i.e., prior preservation). Existing methods are either computationally costly or face challenges in maintaining an effective balance between erasure efficacy and prior preservation. To improve, we propose a precise, fast, and low-cost concept erasure method, called Adaptive Vaule Decomposer (AdaVD), which is training-free. This method is grounded in a classical linear algebraic orthogonal complement operation, implemented in the value space of each cross-attention layer within the UNet of diffusion models. An effective shift factor is designed to adaptively navigate the erasure strength, enhancing prior preservation without sacrificing erasure efficacy. Extensive experimental results show that the proposed AdaVD is effective at both single and multiple concept erasure, showing a 2- to 10-fold improvement in prior preservation as compared to the second best, meanwhile achieving the best or near best erasure efficacy, when comparing with both training-based and training-free state of the arts. AdaVD supports a series of diffusion models and downstream image generation tasks, the code is available on the project page: https://github.com/WYuan1001/AdaVD
LoopGaussian: Creating 3D Cinemagraph with Multi-view Images via Eulerian Motion Field
Apr 13, 2024



Cinemagraph is a unique form of visual media that combines elements of still photography and subtle motion to create a captivating experience. However, the majority of videos generated by recent works lack depth information and are confined to the constraints of 2D image space. In this paper, inspired by significant progress in the field of novel view synthesis (NVS) achieved by 3D Gaussian Splatting (3D-GS), we propose LoopGaussian to elevate cinemagraph from 2D image space to 3D space using 3D Gaussian modeling. To achieve this, we first employ the 3D-GS method to reconstruct 3D Gaussian point clouds from multi-view images of static scenes,incorporating shape regularization terms to prevent blurring or artifacts caused by object deformation. We then adopt an autoencoder tailored for 3D Gaussian to project it into feature space. To maintain the local continuity of the scene, we devise SuperGaussian for clustering based on the acquired features. By calculating the similarity between clusters and employing a two-stage estimation method, we derive an Eulerian motion field to describe velocities across the entire scene. The 3D Gaussian points then move within the estimated Eulerian motion field. Through bidirectional animation techniques, we ultimately generate a 3D Cinemagraph that exhibits natural and seamlessly loopable dynamics. Experiment results validate the effectiveness of our approach, demonstrating high-quality and visually appealing scene generation.
Scalable Lipschitz Estimation for CNNs
Mar 27, 2024Estimating the Lipschitz constant of deep neural networks is of growing interest as it is useful for informing on generalisability and adversarial robustness. Convolutional neural networks (CNNs) in particular, underpin much of the recent success in computer vision related applications. However, although existing methods for estimating the Lipschitz constant can be tight, they have limited scalability when applied to CNNs. To tackle this, we propose a novel method to accelerate Lipschitz constant estimation for CNNs. The core idea is to divide a large convolutional block via a joint layer and width-wise partition, into a collection of smaller blocks. We prove an upper-bound on the Lipschitz constant of the larger block in terms of the Lipschitz constants of the smaller blocks. Through varying the partition factor, the resulting method can be adjusted to prioritise either accuracy or scalability and permits parallelisation. We demonstrate an enhanced scalability and comparable accuracy to existing baselines through a range of experiments.
Progressive Feature Self-reinforcement for Weakly Supervised Semantic Segmentation
Dec 18, 2023Compared to conventional semantic segmentation with pixel-level supervision, Weakly Supervised Semantic Segmentation (WSSS) with image-level labels poses the challenge that it always focuses on the most discriminative regions, resulting in a disparity between fully supervised conditions. A typical manifestation is the diminished precision on the object boundaries, leading to a deteriorated accuracy of WSSS. To alleviate this issue, we propose to adaptively partition the image content into deterministic regions (e.g., confident foreground and background) and uncertain regions (e.g., object boundaries and misclassified categories) for separate processing. For uncertain cues, we employ an activation-based masking strategy and seek to recover the local information with self-distilled knowledge. We further assume that the unmasked confident regions should be robust enough to preserve the global semantics. Building upon this, we introduce a complementary self-enhancement method that constrains the semantic consistency between these confident regions and an augmented image with the same class labels. Extensive experiments conducted on PASCAL VOC 2012 and MS COCO 2014 demonstrate that our proposed single-stage approach for WSSS not only outperforms state-of-the-art benchmarks remarkably but also surpasses multi-stage methodologies that trade complexity for accuracy. The code can be found at \url{https://github.com/Jessie459/feature-self-reinforcement}.
Understanding and Improving Ensemble Adversarial Defense
Nov 02, 2023



The strategy of ensemble has become popular in adversarial defense, which trains multiple base classifiers to defend against adversarial attacks in a cooperative manner. Despite the empirical success, theoretical explanations on why an ensemble of adversarially trained classifiers is more robust than single ones remain unclear. To fill in this gap, we develop a new error theory dedicated to understanding ensemble adversarial defense, demonstrating a provable 0-1 loss reduction on challenging sample sets in an adversarial defense scenario. Guided by this theory, we propose an effective approach to improve ensemble adversarial defense, named interactive global adversarial training (iGAT). The proposal includes (1) a probabilistic distributing rule that selectively allocates to different base classifiers adversarial examples that are globally challenging to the ensemble, and (2) a regularization term to rescue the severest weaknesses of the base classifiers. Being tested over various existing ensemble adversarial defense techniques, iGAT is capable of boosting their performance by increases up to 17% evaluated using CIFAR10 and CIFAR100 datasets under both white-box and black-box attacks.
Physics-Driven ML-Based Modelling for Correcting Inverse Estimation
Sep 25, 2023



When deploying machine learning estimators in science and engineering (SAE) domains, it is critical to avoid failed estimations that can have disastrous consequences, e.g., in aero engine design. This work focuses on detecting and correcting failed state estimations before adopting them in SAE inverse problems, by utilizing simulations and performance metrics guided by physical laws. We suggest to flag a machine learning estimation when its physical model error exceeds a feasible threshold, and propose a novel approach, GEESE, to correct it through optimization, aiming at delivering both low error and high efficiency. The key designs of GEESE include (1) a hybrid surrogate error model to provide fast error estimations to reduce simulation cost and to enable gradient based backpropagation of error feedback, and (2) two generative models to approximate the probability distributions of the candidate states for simulating the exploitation and exploration behaviours. All three models are constructed as neural networks. GEESE is tested on three real-world SAE inverse problems and compared to a number of state-of-the-art optimization/search approaches. Results show that it fails the least number of times in terms of finding a feasible state correction, and requires physical evaluations less frequently in general.
Bi-directional Distribution Alignment for Transductive Zero-Shot Learning
Mar 19, 2023


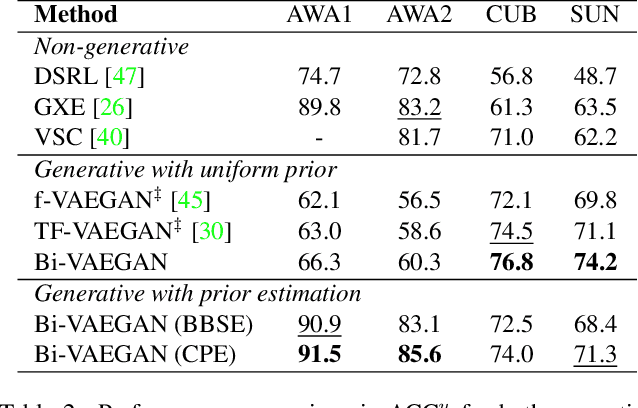
It is well-known that zero-shot learning (ZSL) can suffer severely from the problem of domain shift, where the true and learned data distributions for the unseen classes do not match. Although transductive ZSL (TZSL) attempts to improve this by allowing the use of unlabelled examples from the unseen classes, there is still a high level of distribution shift. We propose a novel TZSL model (named as Bi-VAEGAN), which largely improves the shift by a strengthened distribution alignment between the visual and auxiliary spaces. The key proposal of the model design includes (1) a bi-directional distribution alignment, (2) a simple but effective L_2-norm based feature normalization approach, and (3) a more sophisticated unseen class prior estimation approach. In benchmark evaluation using four datasets, Bi-VAEGAN achieves the new state of the arts under both the standard and generalized TZSL settings. Code could be found at https://github.com/Zhicaiwww/Bi-VAEGAN