 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplitGaussian: Reconstructing Dynamic Scenes via Visual Geometry Decomposition
Aug 06, 2025



Reconstructing dynamic 3D scenes from monocular video remains fundamentally challenging due to the need to jointly infer motion, structure, and appearance from limited observations. Existing dynamic scene reconstruction methods based on Gaussian Splatting often entangle static and dynamic elements in a shared representation, leading to motion leakage, geometric distortions, and temporal flickering. We identify that the root cause lies in the coupled modeling of geometry and appearance across time, which hampers both stability and interpretability. To address this, we propose \textbf{SplitGaussian}, a novel framework that explicitly decomposes scene representations into static and dynamic components. By decoupling motion modeling from background geometry and allowing only the dynamic branch to deform over time, our method prevents motion artifacts in static regions while supporting view- and time-dependent appearance refinement. This disentangled design not only enhances temporal consistency and reconstruction fidelity but also accelerates convergence. Extensive experiments demonstrate that SplitGaussian outperforms prior state-of-the-art methods in rendering quality, geometric stability, and motion separation.
Shaping a Stabilized Video by Mitigating Unintended Changes for Concept-Augmented Video Editing
Oct 16, 2024



Text-driven video editing utilizing generative diffusion models has garnered significant attention due to their potential applications. However, existing approaches are constrained by the limited word embeddings provided in pre-training, which hinders nuanced editing targeting open concepts with specific attributes. Directly altering the keywords in target prompts often results in unintended disruptions to the attention mechanisms. To achieve more flexible editing easily, this work proposes an improved concept-augmented video editing approach that generates diverse and stable target videos flexibly by devising abstract conceptual pairs. Specifically, the framework involves concept-augmented textual inversion and a dual prior supervision mechanism. The former enables plug-and-play guidance of stable diffusion for video editing, effectively capturing target attributes for more stylized results. The dual prior supervision mechanism significantly enhances video stability and fidelity. Comprehensive evaluations demonstrate that our approach generates more stable and lifelike videos, outperforming state-of-the-art methods.
LoopGaussian: Creating 3D Cinemagraph with Multi-view Images via Eulerian Motion Field
Apr 13, 2024



Cinemagraph is a unique form of visual media that combines elements of still photography and subtle motion to create a captivating experience. However, the majority of videos generated by recent works lack depth information and are confined to the constraints of 2D image space. In this paper, inspired by significant progress in the field of novel view synthesis (NVS) achieved by 3D Gaussian Splatting (3D-GS), we propose LoopGaussian to elevate cinemagraph from 2D image space to 3D space using 3D Gaussian modeling. To achieve this, we first employ the 3D-GS method to reconstruct 3D Gaussian point clouds from multi-view images of static scenes,incorporating shape regularization terms to prevent blurring or artifacts caused by object deformation. We then adopt an autoencoder tailored for 3D Gaussian to project it into feature space. To maintain the local continuity of the scene, we devise SuperGaussian for clustering based on the acquired features. By calculating the similarity between clusters and employing a two-stage estimation method, we derive an Eulerian motion field to describe velocities across the entire scene. The 3D Gaussian points then move within the estimated Eulerian motion field. Through bidirectional animation techniques, we ultimately generate a 3D Cinemagraph that exhibits natural and seamlessly loopable dynamics. Experiment results validate the effectiveness of our approach, demonstrating high-quality and visually appealing scene generation.
Mitigating Undisciplined Over-Smoothing in Transformer for Weakly Supervised Semantic Segmentation
May 04, 2023A surge of interest has emerged in weakly supervised semantic segmentation due to its remarkable efficiency in recent years. Existing approaches based on transformers mainly focus on exploring the affinity matrix to boost CAMs with global relationships. While in this work, we first perform a scrupulous examination towards the impact of successive affinity matrices and discover that they possess an inclination toward sparsification as the network approaches convergence, hence disclosing a manifestation of over-smoothing. Besides, it has been observed that enhanced attention maps tend to evince a substantial amount of extraneous background noise in deeper layers. Drawing upon this, we posit a daring conjecture that the undisciplined over-smoothing phenomenon introduces a noteworthy quantity of semantically irrelevant background noise, causing performance degradation. To alleviate this issue, we propose a novel perspective that highlights the objects of interest by investigating the regions of the trait, thereby fostering an extensive comprehension of the successive affinity matrix. Consequently, we suggest an adaptive re-activation mechanism (AReAM) that alleviates the issue of incomplete attention within the object and the unbounded background noise. AReAM accomplishes this by supervising high-level attention with shallow affinity matrices, yielding promising results. Exhaustive experiments conducted on the commonly used dataset manifest that segmentation results can be greatly improved through our proposed AReAM, which imposes restrictions on each affinity matrix in deep layers to make it attentive to semantic regions.
Text-guided mask-free local image retouching
Dec 15, 2022



In the realm of multi-modality, text-guided image retouching techniques emerged with the advent of deep learning. Most currently available text-guided methods, however, rely on object-level supervision to constrain the region that may be modified. This not only makes it more challenging to develop these algorithms, but it also limits how widely deep learning can be used for image retouching. In this paper, we offer a text-guided mask-free image retouching approach that yields consistent results to address this concern. In order to perform image retouching without mask supervision, our technique can construct plausible and edge-sharp masks based on the text for each object in the image. Extensive experiments have shown that our method can produce high-quality, accurate images based on spoken language. The source code will be released soon.
Deep Fashion3D: A Dataset and Benchmark for 3D Garment Reconstruction from Single Images
Mar 28, 2020
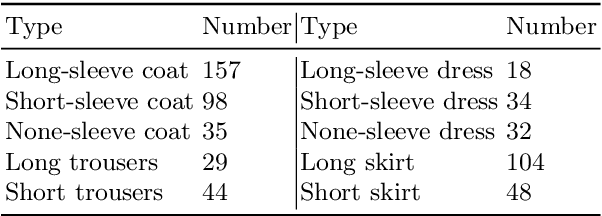

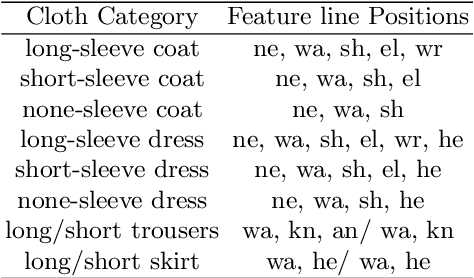
High-fidelity clothing reconstruction is the key to achieving photorealism in a wide range of applications including human digitization, virtual try-on, etc. Recent advances in learning-based approaches have accomplished unprecedented accuracy in recovering unclothed human shape and pose from single images, thanks to the availability of powerful statistical models, e.g. SMPL, learned from a large number of body scans. In contrast, modeling and recovering clothed human and 3D garments remains notoriously difficult, mostly due to the lack of large-scale clothing models available for the research community. We propose to fill this gap by introducing Deep Fashion3D, the largest collection to date of 3D garment models, with the goal of establishing a novel benchmark and dataset for the evaluation of image-based garment reconstruction systems. Deep Fashion3D contains 2078 models reconstructed from real garments, which covers 10 different categories and 563 garment instances. It provides rich annotations including 3D feature lines, 3D body pose and the corresponded multi-view real images. In addition, each garment is randomly posed to enhance the variety of real clothing deformations. To demonstrate the advantage of Deep Fashion3D, we propose a novel baseline approach for single-view garment reconstruction, which leverages the merits of both mesh and implicit representations. A novel adaptable template is proposed to enable the learning of all types of clothing in a single network. Extensive experiments have been conducted on the proposed dataset to verify its significance and usefulness. We will make Deep Fashion3D publicly available upon publication.