 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPart: Part-Level 3D Generation with Unified 3D Geom-Seg Latents
Dec 10, 2025Part-level 3D generation is essential for applications requiring decomposable and structured 3D synthesis. However, existing methods either rely on implicit part segmentation with limited granularity control or depend on strong external segmenters trained on large annotated datasets. In this work, we observe that part awareness emerges naturally during whole-object geometry learning and propose Geom-Seg VecSet, a unified geometry-segmentation latent representation that jointly encodes object geometry and part-level structure. Building on this representation, we introduce UniPart, a two-stage latent diffusion framework for image-guided part-level 3D generation. The first stage performs joint geometry generation and latent part segmentation, while the second stage conditions part-level diffusion on both whole-object and part-specific latents. A dual-space generation scheme further enhances geometric fidelity by predicting part latents in both global and canonical spaces. Extensive experiments demonstrate that UniPart achieves superior segmentation controllability and part-level geometric quality compared with existing approaches.
MarsRL: Advancing Multi-Agent Reasoning System via Reinforcement Learning with Agentic Pipeline Parallelism
Nov 14, 2025Recent progress in large language models (LLMs) has been propelled by reinforcement learning with verifiable rewards (RLVR) and test-time scaling. However, the limited output length of LLMs constrains the depth of reasoning attainable in a single inference process. Multi-agent reasoning systems offer a promising alternative by employing multiple agents including Solver, Verifier, and Corrector, to iteratively refine solutions. While effective in closed-source models like Gemini 2.5 Pro, they struggle to generalize to open-source models due to insufficient critic and correction capabilities. To address this, we propose MarsRL, a novel reinforcement learning framework with agentic pipeline parallelism, designed to jointly optimize all agents in the system. MarsRL introduces agent-specific reward mechanisms to mitigate reward noise and employs pipeline-inspired training to enhance efficiency in handling long trajectories. Applied to Qwen3-30B-A3B-Thinking-2507, MarsRL improves AIME2025 accuracy from 86.5% to 93.3% and BeyondAIME from 64.9% to 73.8%, even surpassing Qwen3-235B-A22B-Thinking-2507. These findings highlight the potential of MarsRL to advance multi-agent reasoning systems and broaden their applicability across diverse reasoning tasks.
Get Experience from Practice: LLM Agents with Record & Replay
May 23, 2025AI agents, empowered by Large Language Models (LLMs) and communication protocols such as MCP and A2A, have rapidly evolved from simple chatbots to autonomous entities capable of executing complex, multi-step tasks, demonstrating great potential. However, the LLMs' inherent uncertainty and heavy computational resource requirements pose four significant challenges to the development of safe and efficient agents: reliability, privacy, cost and performance. Existing approaches, like model alignment, workflow constraints and on-device model deployment, can partially alleviate some issues but often with limitations, failing to fundamentally resolve these challenges. This paper proposes a new paradigm called AgentRR (Agent Record & Replay), which introduces the classical record-and-replay mechanism into AI agent frameworks. The core idea is to: 1. Record an agent's interaction trace with its environment and internal decision process during task execution, 2. Summarize this trace into a structured "experience" encapsulating the workflow and constraints, and 3. Replay these experiences in subsequent similar tasks to guide the agent's behavior. We detail a multi-level experience abstraction method and a check function mechanism in AgentRR: the former balances experience specificity and generality, while the latter serves as a trust anchor to ensure completeness and safety during replay. In addition, we explore multiple application modes of AgentRR, including user-recorded task demonstration, large-small model collaboration and privacy-aware agent execution, and envision an experience repository for sharing and reusing knowledge to further reduce deployment cost.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
L3: DIMM-PIM Integrated Architecture and Coordination for Scalable Long-Context LLM Inference
Apr 24, 2025Large Language Models (LLMs) increasingly require processing long text sequences, but GPU memory limitations force difficult trade-offs between memory capacity and bandwidth. While HBM-based acceleration offers high bandwidth, its capacity remains constrained. Offloading data to host-side DIMMs improves capacity but introduces costly data swapping overhead. We identify that the critical memory bottleneck lies in the decoding phase of multi-head attention (MHA) exclusively, which demands substantial capacity for storing KV caches and high bandwidth for attention computation. Our key insight reveals this operation uniquely aligns with modern DIMM-based processing-in-memory (PIM) architectures, which offers scalability of both capacity and bandwidth. Based on this observation and insight, we propose L3, a hardware-software co-designed system integrating DIMM-PIM and GPU devices. L3 introduces three innovations: First, hardware redesigns resolve data layout mismatches and computational element mismatches in DIMM-PIM, enhancing LLM inference utilization. Second, communication optimization enables hiding the data transfer overhead with the computation. Third, an adaptive scheduler coordinates GPU-DIMM-PIM operations to maximize parallelism between devices. Evaluations using real-world traces show L3 achieves up to 6.1$\times$ speedup over state-of-the-art HBM-PIM solutions while significantly improving batch sizes.
HUNYUANPROVER: A Scalable Data Synthesis Framework and Guided Tree Search for Automated Theorem Proving
Dec 30, 2024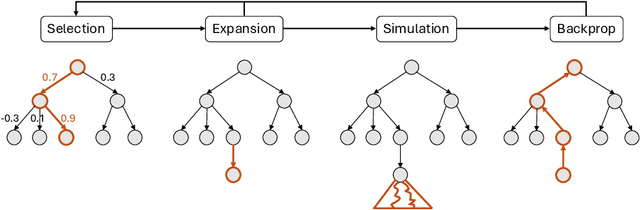
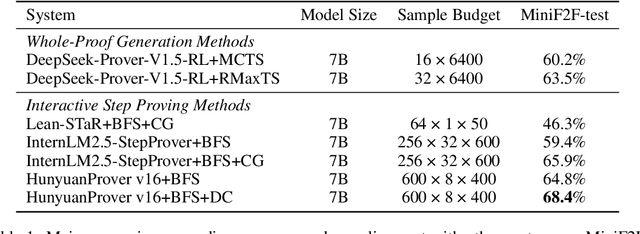
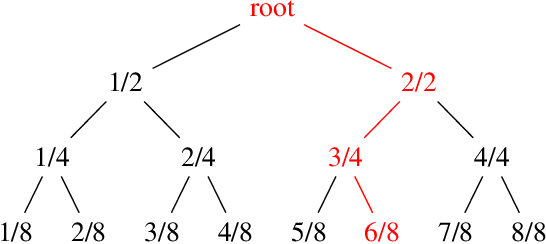

We introduce HunyuanProver, an language model finetuned from the Hunyuan 7B for interactive automatic theorem proving with LEAN4. To alleviate the data sparsity issue, we design a scalable framework to iterative synthesize data with low cost. Besides, guided tree search algorithms are designed to enable effective ``system 2 thinking`` of the prover. HunyuanProver achieves state-of-the-art (SOTA) performances on major benchmarks. Specifically, it achieves a pass of 68.4% on the miniF2F-test compared to 65.9%, the current SOTA results. It proves 4 IMO statements (imo_1960_p2, imo_1962_p2}, imo_1964_p2 and imo_1983_p6) in miniF2F-test. To benefit the community, we will open-source a dataset of 30k synthesized instances, where each instance contains the original question in natural language, the converted statement by autoformalization, and the proof by HunyuanProver.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
SketchMetaFace: A Learning-based Sketching Interface for High-fidelity 3D Character Face Modeling
Jul 04, 2023



Modeling 3D avatars benefits various application scenarios such as AR/VR, gaming, and filming. Character faces contribute significant diversity and vividity as a vital component of avatars. However, building 3D character face models usually requires a heavy workload with commercial tools, even for experienced artists. Various existing sketch-based tools fail to support amateurs in modeling diverse facial shapes and rich geometric details. In this paper, we present SketchMetaFace - a sketching system targeting amateur users to model high-fidelity 3D faces in minutes. We carefully design both the user interface and the underlying algorithm. First, curvature-aware strokes are adopted to better support the controllability of carving facial details. Second, considering the key problem of mapping a 2D sketch map to a 3D model, we develop a novel learning-based method termed "Implicit and Depth Guided Mesh Modeling" (IDGMM). It fuses the advantages of mesh, implicit, and depth representations to achieve high-quality results with high efficiency. In addition, to further support usability, we present a coarse-to-fine 2D sketching interface design and a data-driven stroke suggestion tool. User studies demonstrate the superiority of our system over existing modeling tools in terms of the ease to use and visual quality of results. Experimental analyses also show that IDGMM reaches a better trade-off between accuracy and efficiency. SketchMetaFace is available at https://zhongjinluo.github.io/SketchMetaFace/.
3D Keypoint Estimation Using Implicit Representation Learning
Jun 20, 2023In this paper, we tackle the challenging problem of 3D keypoint estimation of general objects using a novel implicit representation. Previous works have demonstrated promising results for keypoint prediction through direct coordinate regression or heatmap-based inference. However, these methods are commonly studied for specific subjects, such as human bodies and faces, which possess fixed keypoint structures. They also suffer in several practical scenarios where explicit or complete geometry is not given, including images and partial point clouds. Inspired by the recent success of advanced implicit representation in reconstruction tasks, we explore the idea of using an implicit field to represent keypoints. Specifically, our key idea is employing spheres to represent 3D keypoints, thereby enabling the learnability of the corresponding signed distance field. Explicit keypoints can be extracted subsequently by our algorithm based on the Hough transform. Quantitative and qualitative evaluations also show the superiority of our representation in terms of prediction accuracy.
NerVE: Neural Volumetric Edges for Parametric Curve Extraction from Point Cloud
Mar 29, 2023



Extracting parametric edge curves from point clouds is a fundamental problem in 3D vision and geometry processing. Existing approaches mainly rely on keypoint detection, a challenging procedure that tends to generate noisy output, making the subsequent edge extraction error-prone. To address this issue, we propose to directly detect structured edges to circumvent the limitations of the previous point-wise methods. We achieve this goal by presenting NerVE, a novel neural volumetric edge representation that can be easily learned through a volumetric learning framework. NerVE can be seamlessly converted to a versatile piece-wise linear (PWL) curve representation, enabling a unified strategy for learning all types of free-form curves. Furthermore, as NerVE encodes rich structural information, we show that edge extraction based on NerVE can be reduced to a simple graph search problem. After converting NerVE to the PWL representation, parametric curves can be obtained via off-the-shelf spline fitting algorithms. We evaluate our method on the challenging ABC dataset. We show that a simple network based on NerVE can already outperform the previous state-of-the-art methods by a great margin. Project page: https://dongdu3.github.io/projects/2023/NerVE/.