 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
Revisiting Optimal Convergence Rate for Smooth and Non-convex Stochastic Decentralized Optimization
Oct 14, 2022
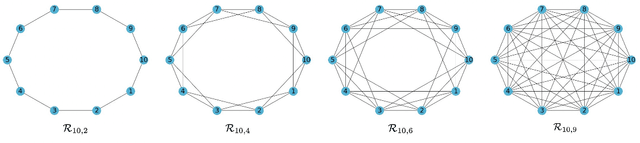

Decentralized optimization is effective to save communication in large-scale machine learning. Although numerous algorithms have been proposed with theoretical guarantees and empirical successes, the performance limits in decentralized optimization, especially the influence of network topology and its associated weight matrix on the optimal convergence rate, have not been fully understood. While (Lu and Sa, 2021) have recently provided an optimal rate for non-convex stochastic decentralized optimization with weight matrices defined over linear graphs, the optimal rate with general weight matrices remains unclear. This paper revisits non-convex stochastic decentralized optimization and establishes an optimal convergence rate with general weight matrices. In addition, we also establish the optimal rate when non-convex loss functions further satisfy the Polyak-Lojasiewicz (PL) condition. Following existing lines of analysis in literature cannot achieve these results. Instead, we leverage the Ring-Lattice graph to admit general weight matrices while maintaining the optimal relation between the graph diameter and weight matrix connectivity. Lastly, we develop a new decentralized algorithm to nearly attain the above two optimal rates under additional mild conditions.
Recurrent Dynamic Embedding for Video Object Segmentation
May 08, 2022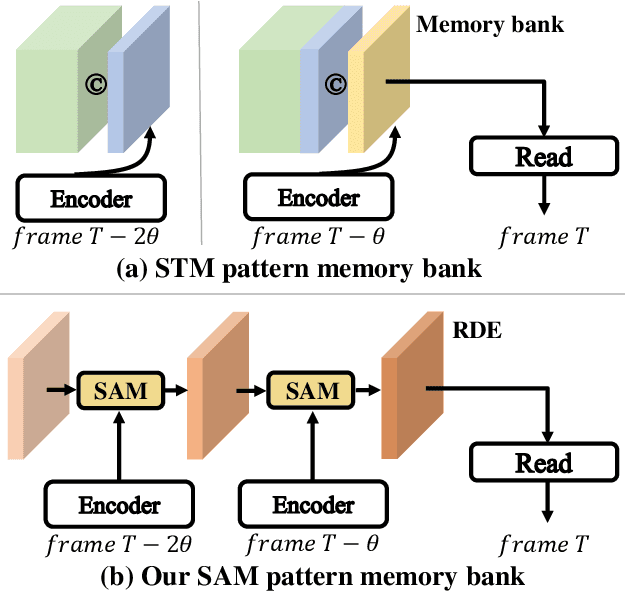
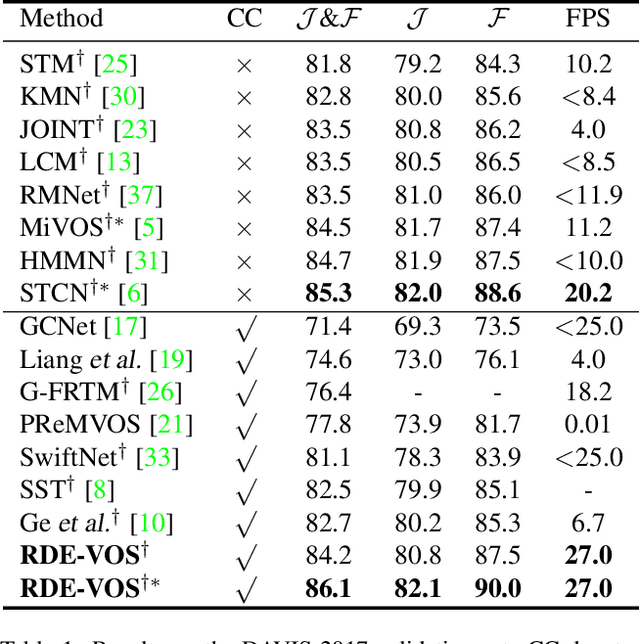
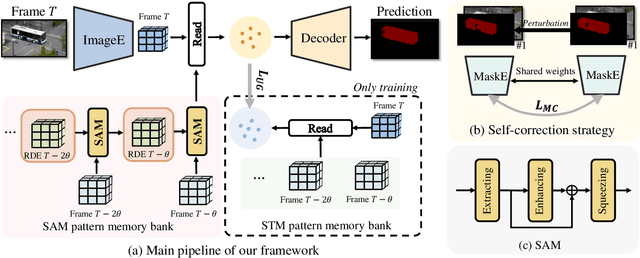
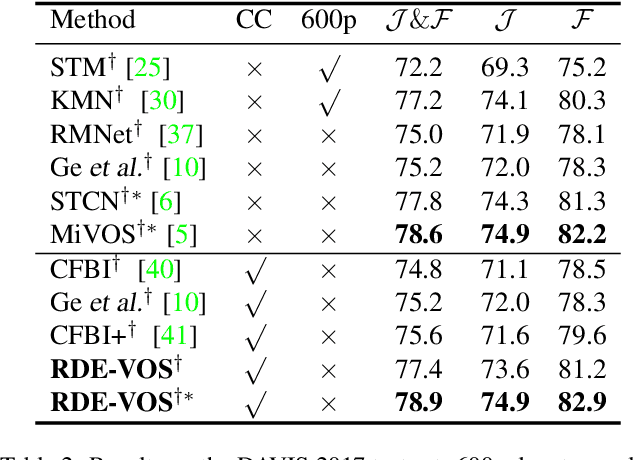
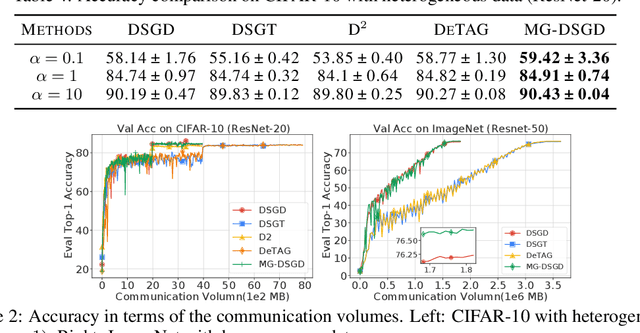
Space-time memory (STM) based video object segmentation (VOS) networks usually keep increasing memory bank every several frames, which shows excellent performance. However, 1) the hardware cannot withstand the ever-increasing memory requirements as the video length increases. 2) Storing lots of information inevitably introduces lots of noise, which is not conducive to reading the most important information from the memory bank. In this paper, we propose a Recurrent Dynamic Embedding (RDE) to build a memory bank of constant size. Specifically, we explicitly generate and update RDE by the proposed Spatio-temporal Aggregation Module (SAM), which exploits the cue of historical information. To avoid error accumulation owing to the recurrent usage of SAM, we propose an unbiased guidance loss during the training stage, which makes SAM more robust in long videos. Moreover, the predicted masks in the memory bank are inaccurate due to the inaccurate network inference, which affects the segmentation of the query frame. To address this problem, we design a novel self-correction strategy so that the network can repair the embeddings of masks with different qualities in the memory bank. Extensive experiments show our method achieves the best tradeoff between performance and speed. Code is available at https://github.com/Limingxing00/RDE-VOS-CVPR2022.
Multi-View Consistent Generative Adversarial Networks for 3D-aware Image Synthesis
Apr 13, 2022



3D-aware image synthesis aims to generate images of objects from multiple views by learning a 3D representation. However, one key challenge remains: existing approaches lack geometry constraints, hence usually fail to generate multi-view consistent images. To address this challenge, we propose Multi-View Consistent Generative Adversarial Networks (MVCGAN) for high-quality 3D-aware image synthesis with geometry constraints. By leveraging the underlying 3D geometry information of generated images, i.e., depth and camera transformation matrix, we explicitly establish stereo correspondence between views to perform multi-view joint optimization. In particular, we enforce the photometric consistency between pairs of views and integrate a stereo mixup mechanism into the training process, encouraging the model to reason about the correct 3D shape. Besides, we design a two-stage training strategy with feature-level multi-view joint optimization to improve the image quality. Extensive experiments on three datasets demonstrate that MVCGAN achieves the state-of-the-art performance for 3D-aware image synthesis.
RCL: Recurrent Continuous Localization for Temporal Action Detection
Mar 14, 2022

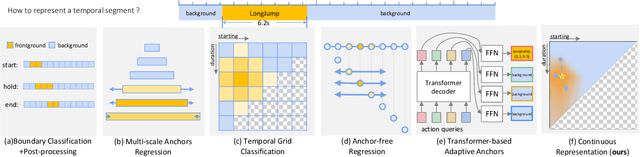

Temporal representation is the cornerstone of modern action detection techniques. State-of-the-art methods mostly rely on a dense anchoring scheme, where anchors are sampled uniformly over the temporal domain with a discretized grid, and then regress the accurate boundaries. In this paper, we revisit this foundational stage and introduce Recurrent Continuous Localization (RCL), which learns a fully continuous anchoring representation. Specifically, the proposed representation builds upon an explicit model conditioned with video embeddings and temporal coordinates, which ensure the capability of detecting segments with arbitrary length. To optimize the continuous representation, we develop an effective scale-invariant sampling strategy and recurrently refine the prediction in subsequent iterations. Our continuous anchoring scheme is fully differentiable, allowing to be seamlessly integrated into existing detectors, e.g., BMN and G-TAD. Extensive experiments on two benchmarks demonstrate that our continuous representation steadily surpasses other discretized counterparts by ~2% mAP. As a result, RCL achieves 52.92% mAP@0.5 on THUMOS14 and 37.65% mAP on ActivtiyNet v1.3, outperforming all existing single-model detectors.
Disentangled Representation Learning for Text-Video Retrieval
Mar 14, 2022



Cross-modality interaction is a critical component in Text-Video Retrieval (TVR), yet there has been little examination of how different influencing factors for computing interaction affect performance. This paper first studies the interaction paradigm in depth, where we find that its computation can be split into two terms, the interaction contents at different granularity and the matching function to distinguish pairs with the same semantics. We also observe that the single-vector representation and implicit intensive function substantially hinder the optimization. Based on these findings, we propose a disentangled framework to capture a sequential and hierarchical representation. Firstly, considering the natural sequential structure in both text and video inputs, a Weighted Token-wise Interaction (WTI) module is performed to decouple the content and adaptively exploit the pair-wise correlations. This interaction can form a better disentangled manifold for sequential inputs. Secondly, we introduce a Channel DeCorrelation Regularization (CDCR) to minimize the redundancy between the components of the compared vectors, which facilitate learning a hierarchical representation. We demonstrate the effectiveness of the disentangled representation on various benchmarks, e.g., surpassing CLIP4Clip largely by +2.9%, +3.1%, +7.9%, +2.3%, +2.8% and +6.5% R@1 on the MSR-VTT, MSVD, VATEX, LSMDC, AcitivityNet, and DiDeMo, respectively.
Exponential Graph is Provably Efficient for Decentralized Deep Training
Oct 26, 2021
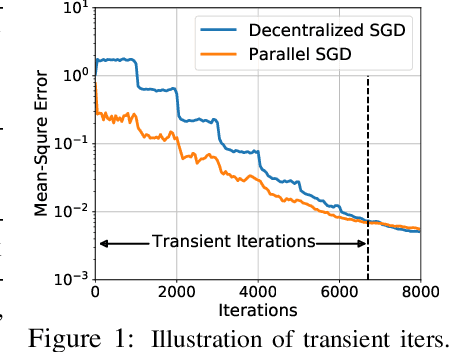
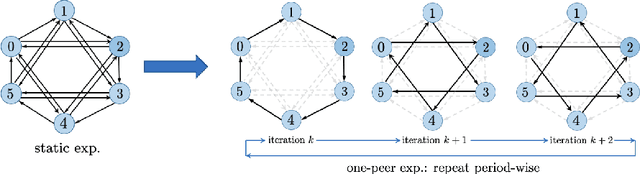
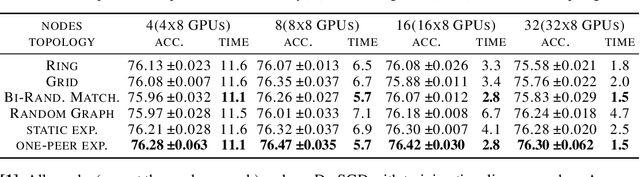
Decentralized SGD is an emerging training method for deep learning known for its much less (thus faster) communication per iteration, which relaxes the averaging step in parallel SGD to inexact averaging. The less exact the averaging is, however, the more the total iterations the training needs to take. Therefore, the key to making decentralized SGD efficient is to realize nearly-exact averaging using little communication. This requires a skillful choice of communication topology, which is an under-studied topic in decentralized optimization. In this paper, we study so-called exponential graphs where every node is connected to $O(\log(n))$ neighbors and $n$ is the total number of nodes. This work proves such graphs can lead to both fast communication and effective averaging simultaneously. We also discover that a sequence of $\log(n)$ one-peer exponential graphs, in which each node communicates to one single neighbor per iteration, can together achieve exact averaging. This favorable property enables one-peer exponential graph to average as effective as its static counterpart but communicates more efficiently. We apply these exponential graphs in decentralized (momentum) SGD to obtain the state-of-the-art balance between per-iteration communication and iteration complexity among all commonly-used topologies. Experimental results on a variety of tasks and models demonstrate that decentralized (momentum) SGD over exponential graphs promises both fast and high-quality training. Our code is implemented through BlueFog and available at https://github.com/Bluefog-Lib/NeurIPS2021-Exponential-Graph.
Accelerating Gossip SGD with Periodic Global Averaging
May 19, 2021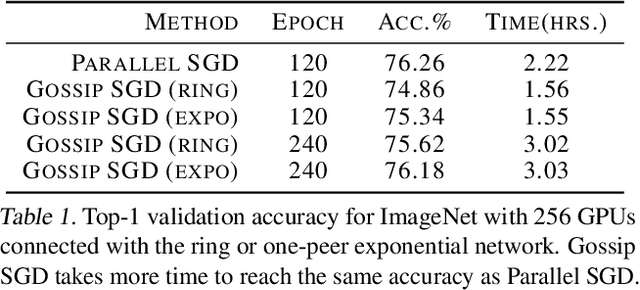
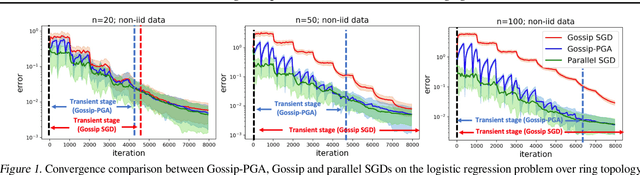

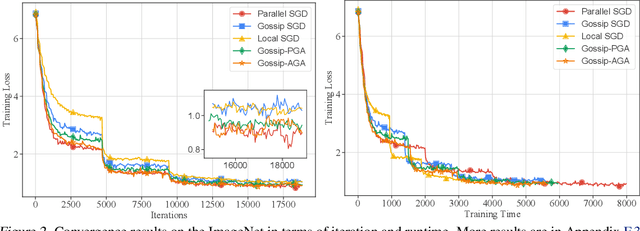
Communication overhead hinders the scalability of large-scale distributed training. Gossip SGD, where each node averages only with its neighbors, is more communication-efficient than the prevalent parallel SGD. However, its convergence rate is reversely proportional to quantity $1-\beta$ which measures the network connectivity. On large and sparse networks where $1-\beta \to 0$, Gossip SGD requires more iterations to converge, which offsets against its communication benefit. This paper introduces Gossip-PGA, which adds Periodic Global Averaging into Gossip SGD. Its transient stage, i.e., the iterations required to reach asymptotic linear speedup stage, improves from $\Omega(\beta^4 n^3/(1-\beta)^4)$ to $\Omega(\beta^4 n^3 H^4)$ for non-convex problems. The influence of network topology in Gossip-PGA can be controlled by the averaging period $H$. Its transient-stage complexity is also superior to Local SGD which has order $\Omega(n^3 H^4)$. Empirical results of large-scale training on image classification (ResNet50) and language modeling (BERT) validate our theoretical findings.
OR-Net: Pointwise Relational Inference for Data Completion under Partial Observation
May 05, 2021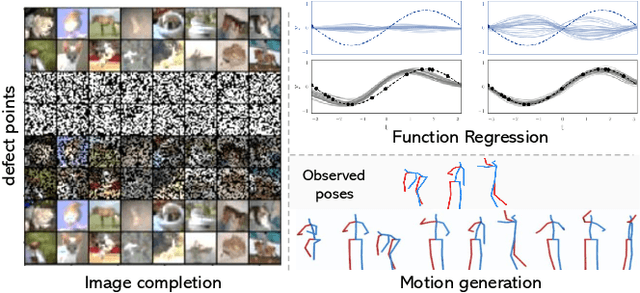
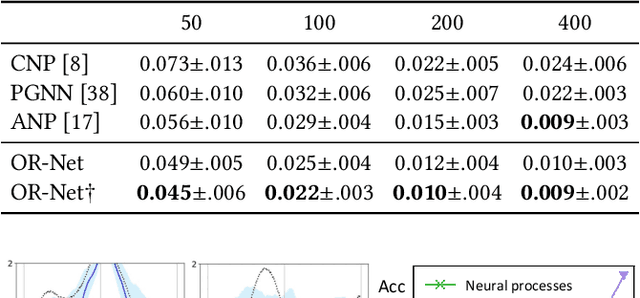
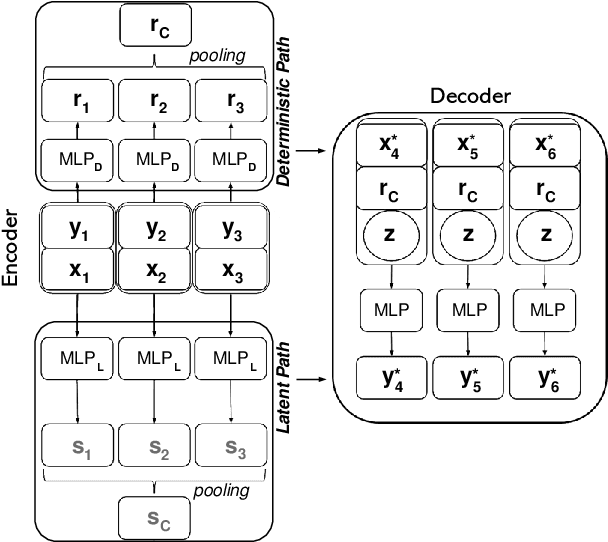

Contemporary data-driven methods are typically fed with full supervision on large-scale datasets which limits their applicability. However, in the actual systems with limitations such as measurement error and data acquisition problems, people usually obtain incomplete data. Although data completion has attracted wide attention, the underlying data pattern and relativity are still under-developed. Currently, the family of latent variable models allows learning deep latent variables over observed variables by fitting the marginal distribution. As far as we know, current methods fail to perceive the data relativity under partial observation. Aiming at modeling incomplete data, this work uses relational inference to fill in the incomplete data. Specifically, we expect to approximate the real joint distribution over the partial observation and latent variables, thus infer the unseen targets respectively. To this end, we propose Omni-Relational Network (OR-Net) to model the pointwise relativity in two aspects: (i) On one hand, the inner relationship is built among the context points in the partial observation; (ii) On the other hand, the unseen targets are inferred by learning the cross-relationship with the observed data points. It is further discovered that the proposed method can be generalized to different scenarios regardless of whether the physical structure can be observed or not. It is demonstrated that the proposed OR-Net can be well generalized for data completion tasks of various modalities, including function regression, image completion on MNIST and CelebA datasets, and also sequential motion generation conditioned on the observed poses.
DecentLaM: Decentralized Momentum SGD for Large-batch Deep Training
Apr 24, 2021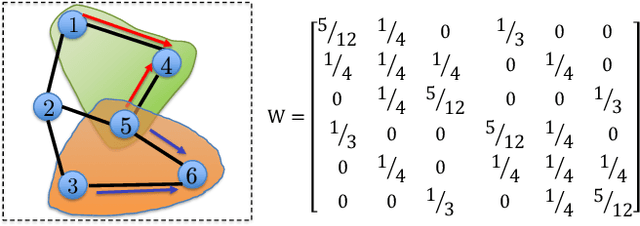



The scale of deep learning nowadays calls for efficient distributed training algorithms. Decentralized momentum SGD (DmSGD), in which each node averages only with its neighbors, is more communication efficient than vanilla Parallel momentum SGD that incurs global average across all computing nodes. On the other hand, the large-batch training has been demonstrated critical to achieve runtime speedup. This motivates us to investigate how DmSGD performs in the large-batch scenario. In this work, we find the momentum term can amplify the inconsistency bias in DmSGD. Such bias becomes more evident as batch-size grows large and hence results in severe performance degradation. We next propose DecentLaM, a novel decentralized large-batch momentum SGD to remove the momentum-incurred bias. The convergence rate for both non-convex and strongly-convex scenarios is established. Our theoretical results justify the superiority of DecentLaM to DmSGD especially in the large-batch scenario. Experimental results on a variety of computer vision tasks and models demonstrate that DecentLaM promises both efficient and high-quality training.