 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRCL: Recurrent Continuous Localization for Temporal Action Detection
Paper and Code
Mar 14, 2022

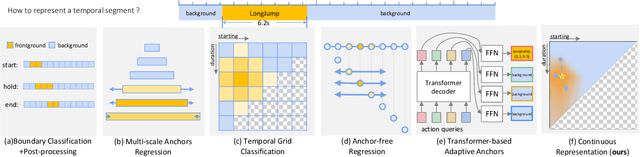

Temporal representation is the cornerstone of modern action detection techniques. State-of-the-art methods mostly rely on a dense anchoring scheme, where anchors are sampled uniformly over the temporal domain with a discretized grid, and then regress the accurate boundaries. In this paper, we revisit this foundational stage and introduce Recurrent Continuous Localization (RCL), which learns a fully continuous anchoring representation. Specifically, the proposed representation builds upon an explicit model conditioned with video embeddings and temporal coordinates, which ensure the capability of detecting segments with arbitrary length. To optimize the continuous representation, we develop an effective scale-invariant sampling strategy and recurrently refine the prediction in subsequent iterations. Our continuous anchoring scheme is fully differentiable, allowing to be seamlessly integrated into existing detectors, e.g., BMN and G-TAD. Extensive experiments on two benchmarks demonstrate that our continuous representation steadily surpasses other discretized counterparts by ~2% mAP. As a result, RCL achieves 52.92% mAP@0.5 on THUMOS14 and 37.65% mAP on ActivtiyNet v1.3, outperforming all existing single-model detectors.